![]() Content
Content
Introduction & Brief History
World of Approximation
Neural Networks
Optimization
Applications

![]()
Introduction & Brief History
World of Approximation
Neural Networks
Optimization
Applications
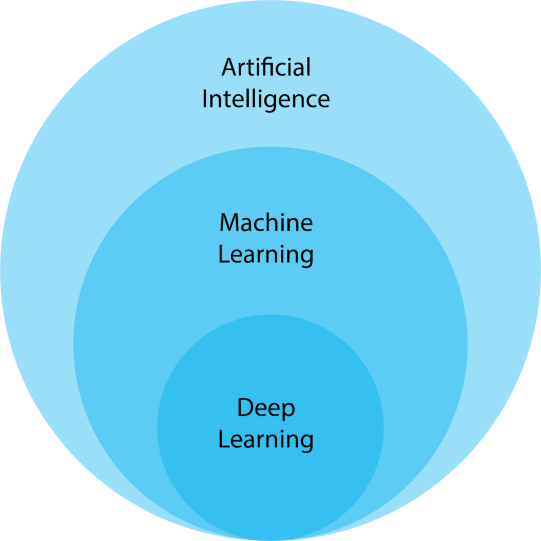
Deep Neural Networks (DNN) or Multilayer Perceptron (MLP) is a type of ML model built to simulate the complex decision-making power of the human brain 🧠.
It is a backbone that powers the recent development of Artificial Intelligence (AI) applications in our lives today.
relationship between input \(X\) and the target \(y\), called \(\color{red}{f}\).\[\underbrace{\begin{bmatrix}x_{11} & x_{12} & \dots & x_{1d}\\ x_{21} & x_{22} & \dots & x_{2d}\\ x_{31} & x_{32} & \dots & x_{3d}\\ \vdots & \vdots & \ddots & \vdots\\ x_{n1} & x_{n2} & \dots & x_{nd}\\ \end{bmatrix}}_{\text{Input }X}\xrightarrow[]{\color{red}{f}} \underbrace{\begin{bmatrix}y_1\\ y_2\\ y_3\\ \vdots\\ y_n \end{bmatrix}}_{\text{target }y}\]



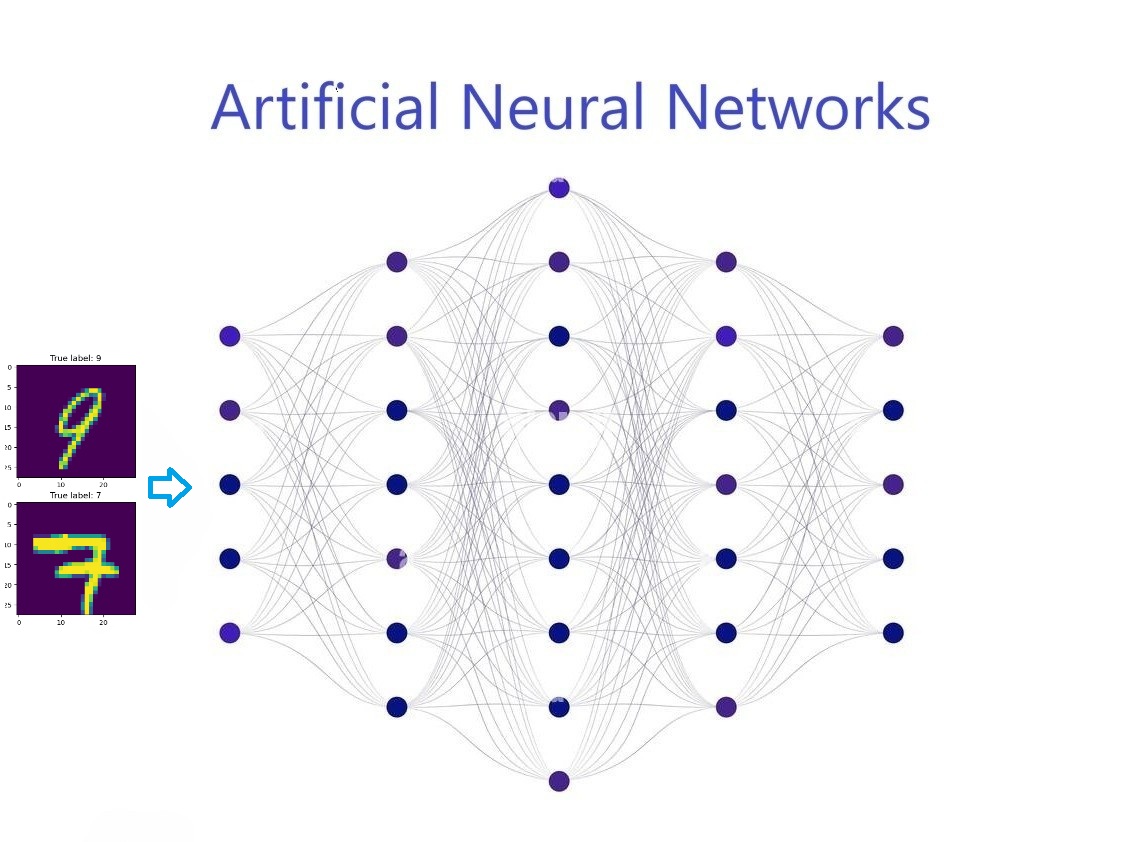

nonlinear activation function.
nonlinear activation function.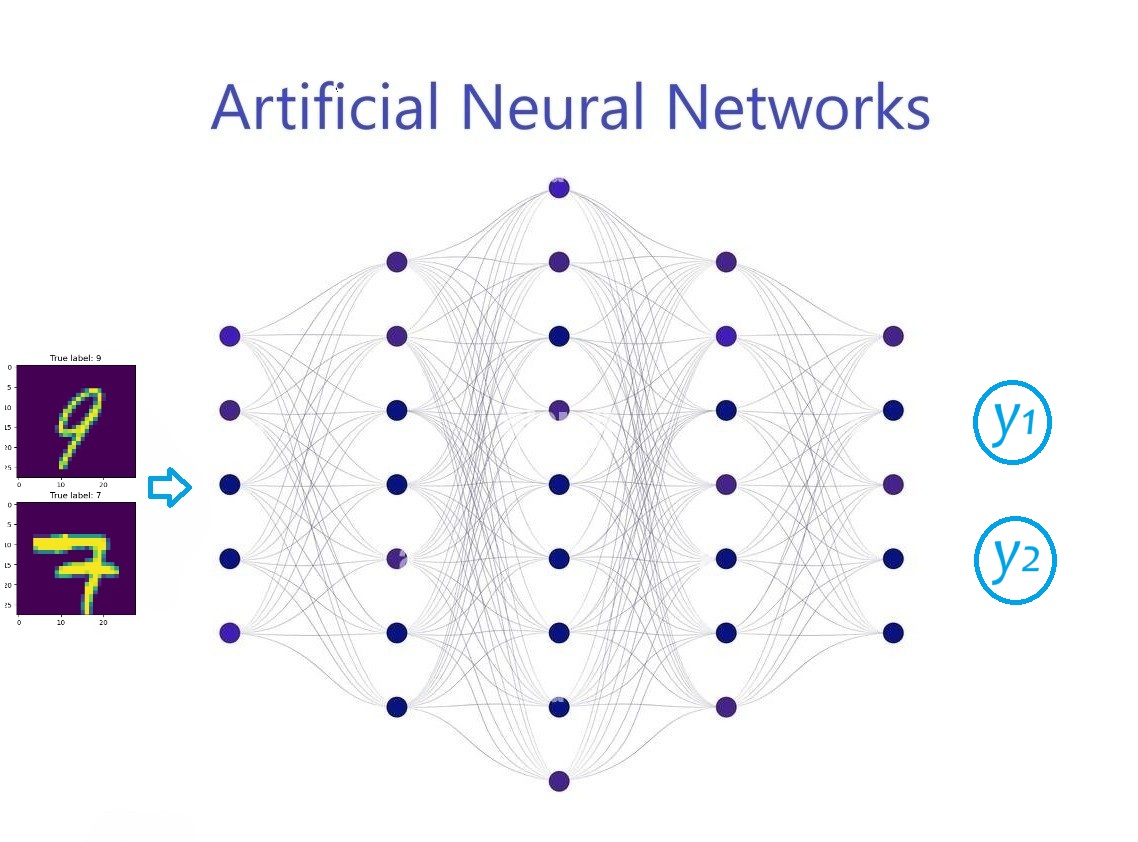
nonlinear activation function.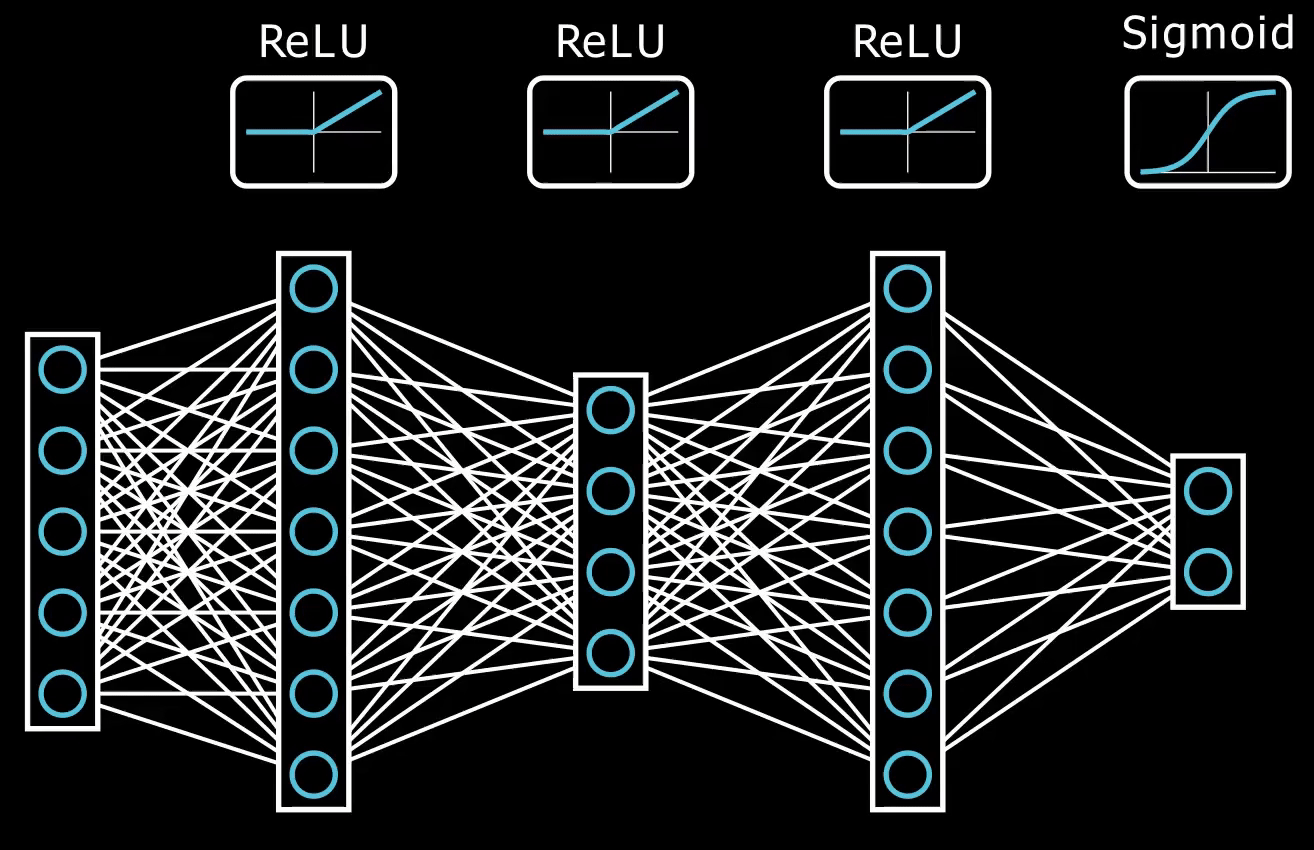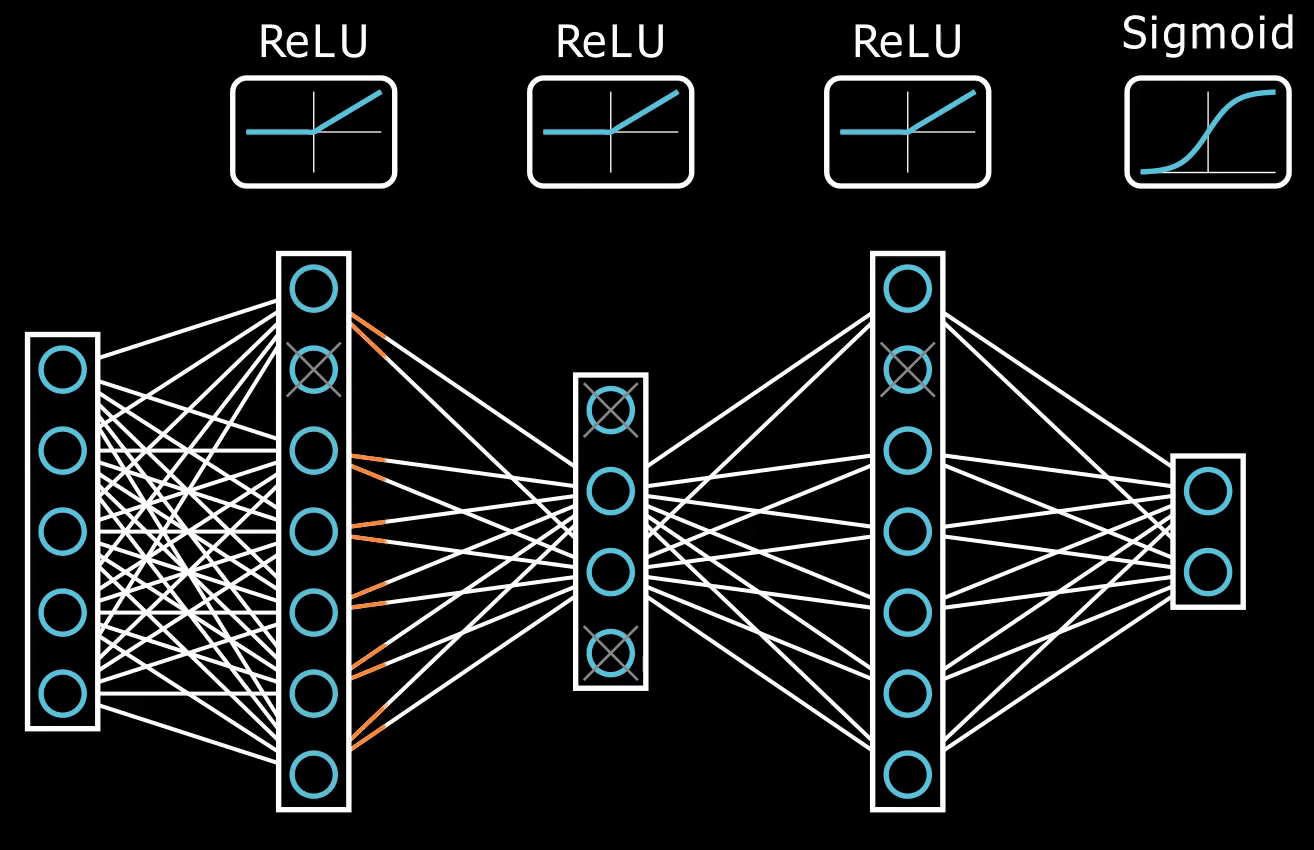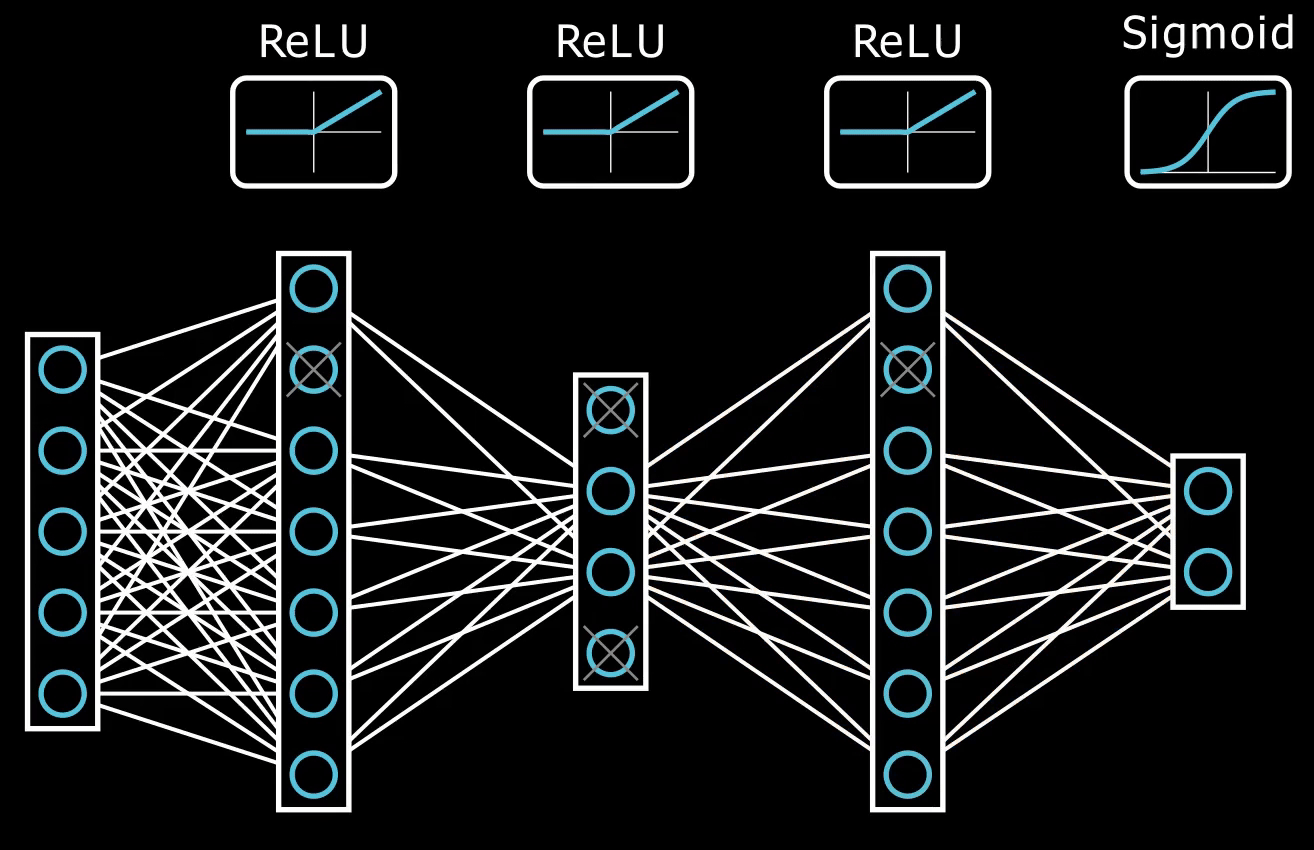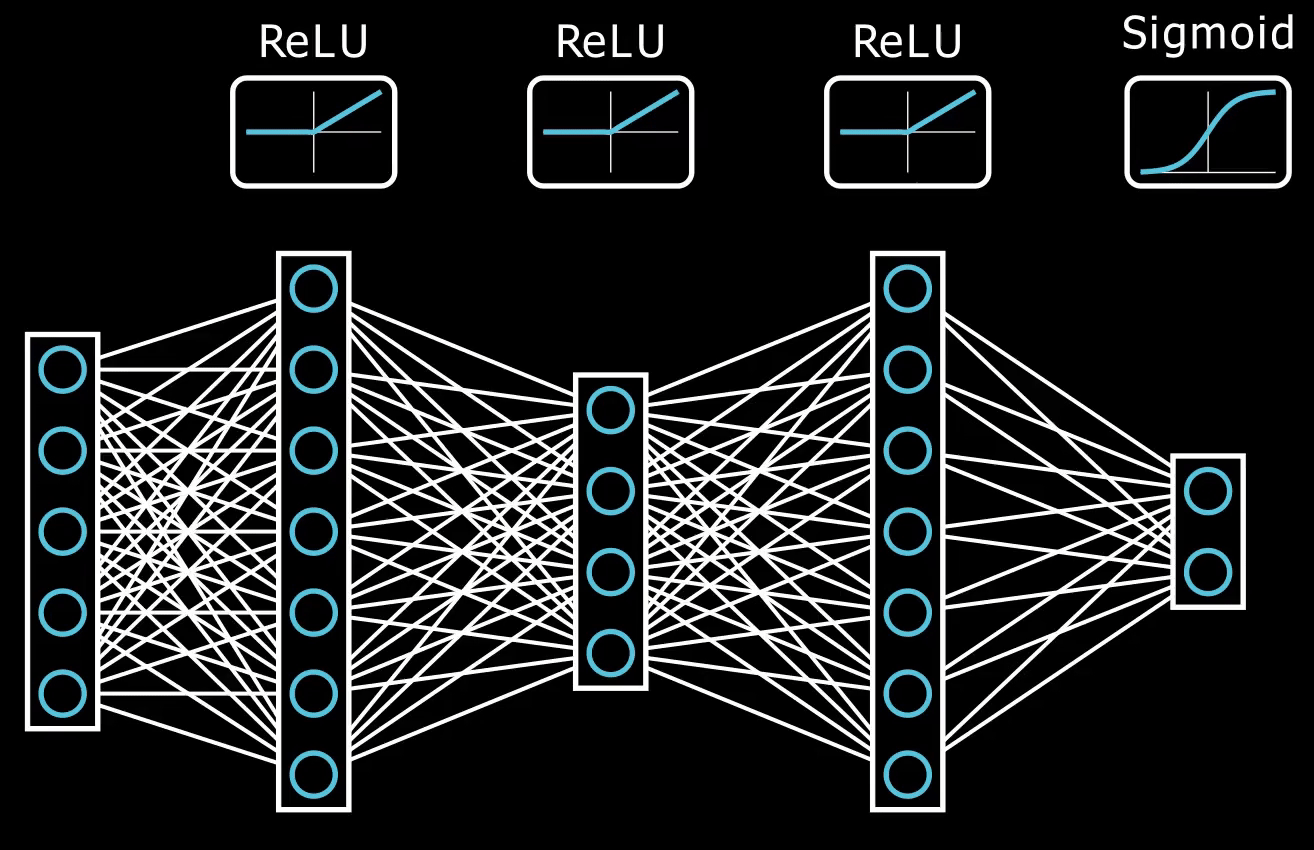

nonlinear activation function.
MLP using Keras.
Rings.👉 Jupyter notebook: Feedforward NN by hand.
![]()