| x1 | x2 | y |
|---|---|---|
| -0.752759 | 2.704286 | 1 |
| 1.935603 | -0.838856 | 0 |
Advanced Machine Learning

![]()
Binary Logistic Regression
Summary
Logistic Regression Model
- Main assumption: \(p(1|\text{x})=1/(1+e^{-\color{green}{z}})=1/(1+e^{-\color{green}{(\beta_0+\text{x}^T\vec{\beta})}})\).
- Interpretation:
- Boundary decision is
Linear(hyperplane) defined by \(\beta_0\) and \(\vec{\beta}\). - Probability of being in each class depends on the relative distance of that point to the boundary.
- Works well when classes are linearly separable.
- Boundary decision is
- Interpretation:
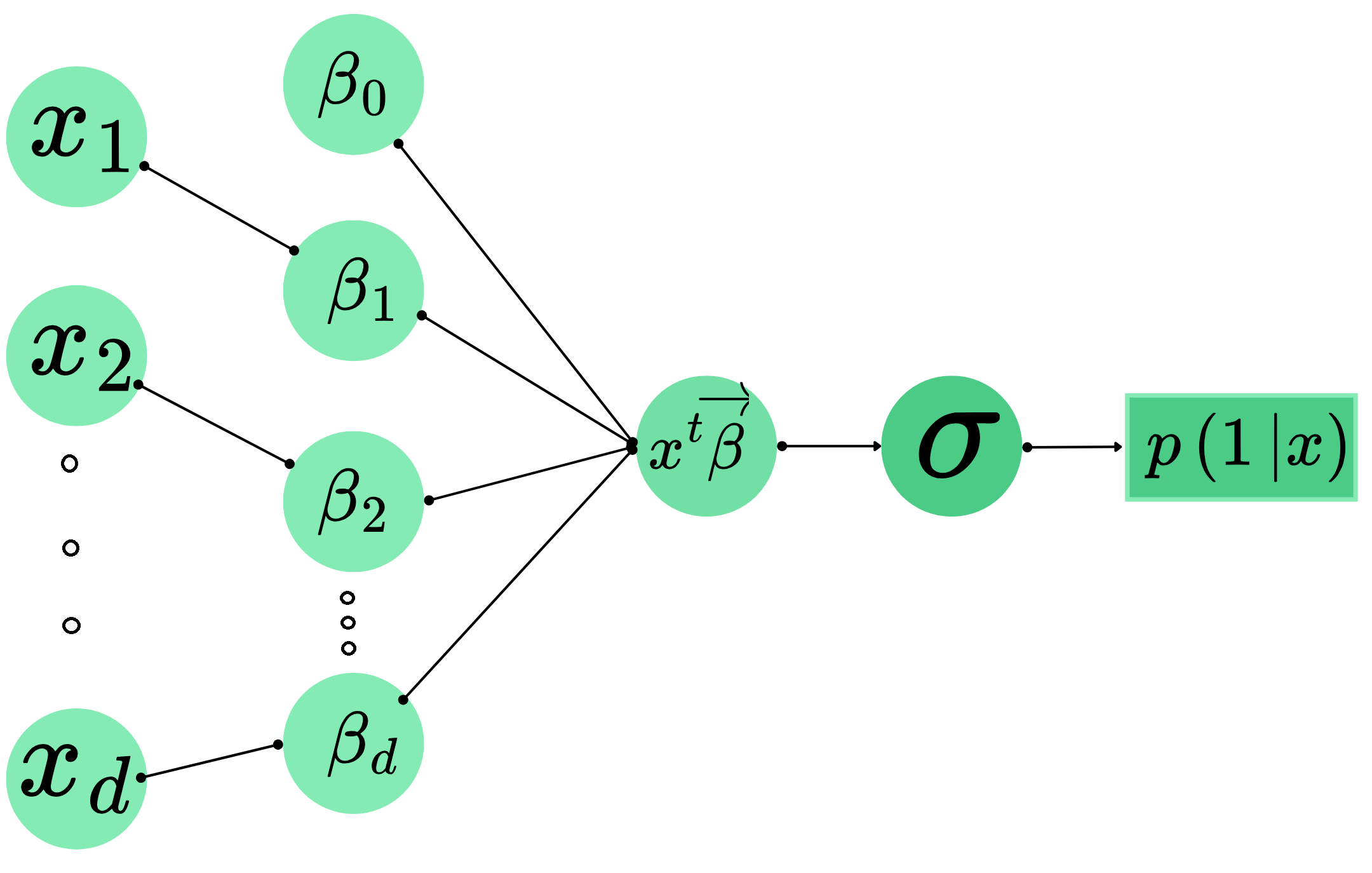
- Objective: buliding a Logistic Regression model is equivalent to searching for parameters \(\beta_0\) and \(\vec{\beta}\) that minimizes the Log Loss function (Equation 1).
- The loss cannot be minimized analytically but can be minimized numerically.
Multinomial Logistic Regression
Example
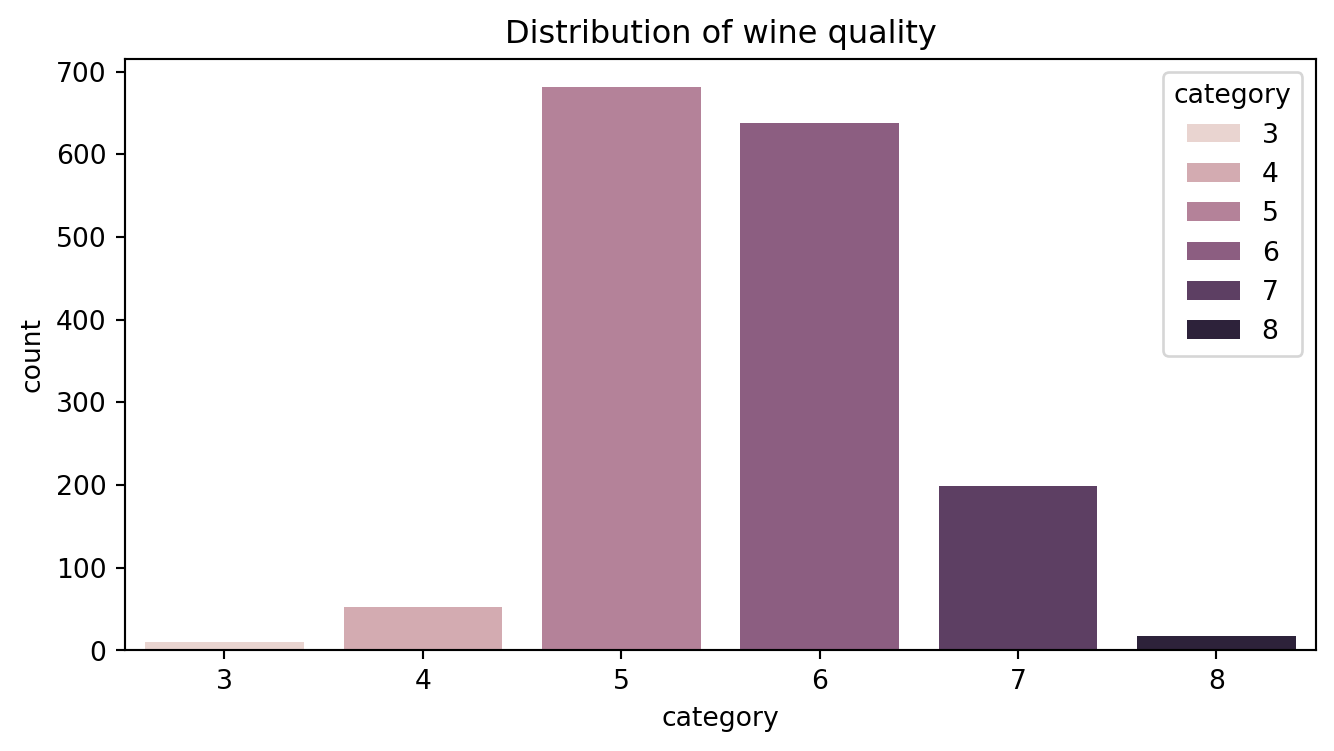
- Task:
Predictingtarget \(y\in\{1,2,\dots,M\}\) using its input \(\text{x}\in\mathbb{R}^d\). - Example: Kaggle wine quality data.
Multinomial Logistic Regression
Example (modified)
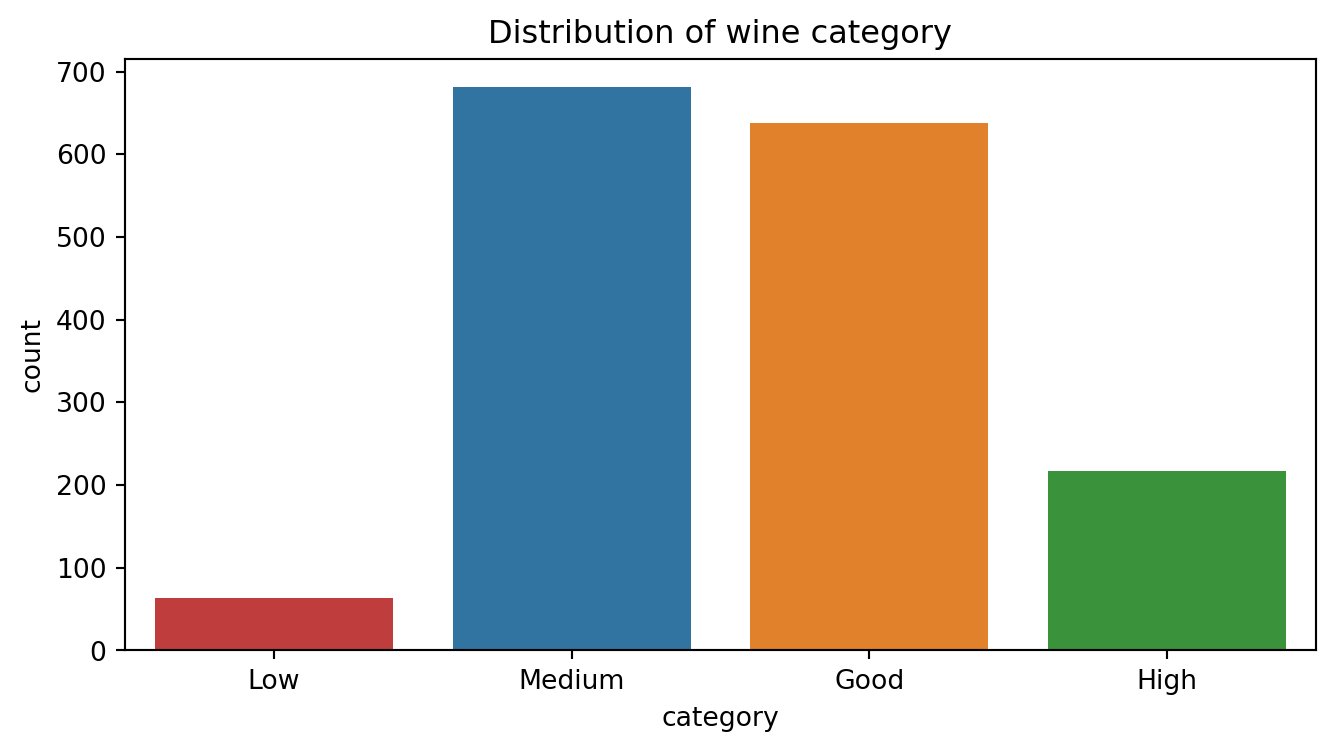
- Task:
Predictingtarget \(y\in\{1,2,\dots,M\}\) using its input \(\text{x}\in\mathbb{R}^d\). - Example: Kaggle wine quality data.
Multinomial Logistic Regression
Model
- \(\text{Softmax}:\mathbb{R}^M\to\mathbb{S}_{M-1}=\{p_j\in[0,1]^M:\sum_{j=1}^Mp_j=1\}\) defined by \[\vec{z}\mapsto \vec{s}=\text{Softmax}(z)=\Big(\frac{e^{z_1}}{\sum_{j=1}^Me^{z_j}},\dots,\frac{e^{z_M}}{\sum_{j=1}^Me^{z_j}}\Big).\]
- Model: Given parameter matrix \(\color{green}{W}\) of size \(M\times d\) and intercept vector \(\color{green}{\vec{b}}\in\mathbb{R}^d\), the predicted probability of any input data \(\text{x}_i\in\mathbb{R}^d\) is defined by

\[\begin{align*}\color{red}{\hat{p}_i}&=\text{Softmax}(\color{green}{W}\text{x}_i+\color{green}{\vec{b}})\\ &=\text{Softmax}\begin{pmatrix} \color{green}{\begin{bmatrix}w_{11}& \dots & w_{1d}\\ w_{11}& \dots & w_{1d}\\ \vdots & \vdots & \vdots\\ w_{M1}& \dots & w_{Md}\end{bmatrix}}\begin{bmatrix}x_{i1}\\ x_{i2}\\ \vdots\\ x_{id}\end{bmatrix}+\color{green}{\begin{bmatrix}b_{1}\\ b_{2}\\ \vdots\\ b_{M}\end{bmatrix}}\end{pmatrix}=\color{red}{\begin{bmatrix}p_{i1}\\ p_{i2}\\ \vdots\\ p_{iM}\end{bmatrix}}\end{align*}\]
Multinomial Logistic Regression
Model
\[\begin{align*}\color{red}{\hat{p}_i}&=\text{Softmax}(\color{green}{W}\text{x}_i+\color{green}{\vec{b}})\\ &=\text{Softmax}\begin{pmatrix} \color{green}{\begin{bmatrix}w_{11}& \dots & w_{1d}\\ w_{11}& \dots & w_{1d}\\ \vdots & \vdots & \vdots\\ w_{M1}& \dots & w_{Md}\end{bmatrix}}\begin{bmatrix}x_{i1}\\ x_{i2}\\ \vdots\\ x_{id}\end{bmatrix}+\color{green}{\begin{bmatrix}b_{1}\\ b_{2}\\ \vdots\\ b_{M}\end{bmatrix}}\end{pmatrix}=\color{red}{\begin{bmatrix}p_{i1}\\ p_{i2}\\ \vdots\\ p_{iM}\end{bmatrix}}\end{align*}\]

Multinomial Logistic Regression
In action: Target vs Inputs
Code
sns.set(style="whitegrid")
_, axs = plt.subplots(2,3,figsize=(10,5))
i = 0
for var in df_wine.columns[:6]:
sns.boxplot(df_wine, x="category", y=var,
hue="category", ax=axs[i//3, i%3],
order=['Low', 'Medium', 'Good', 'High'])
axs[i//3, i%3].set_title(f"Category vs {var}")
i += 1
plt.tight_layout()
plt.show()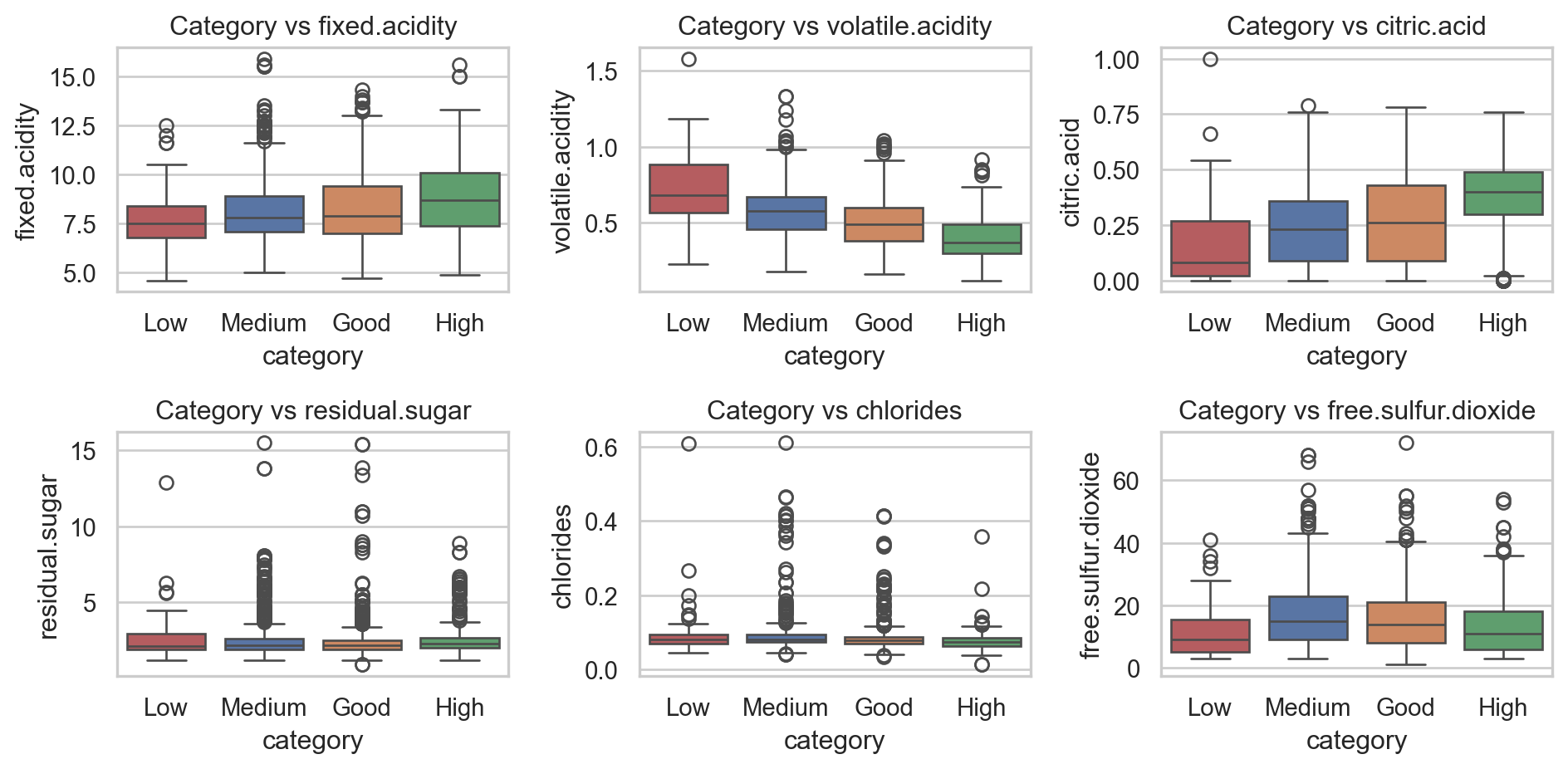
Multinomial Logistic Regression
In action: Target vs Inputs
Code
from matplotlib.gridspec import GridSpec
fig = plt.figure(figsize=(10,5))
gs = GridSpec(4, 6)
axs = []
i = 0
for var in df_wine.columns[6:-2]:
if i < 2:
axs.append(fig.add_subplot(gs[:2, (2*i % 6):(2*i+2)%6]))
elif i == 2:
axs.append(fig.add_subplot(gs[:2, 4:]))
elif i == 3:
axs.append(fig.add_subplot(gs[2:, 1:3]))
else:
axs.append(fig.add_subplot(gs[2:, 3:5]))
sns.boxplot(df_wine, x="category", y=var,
hue="category", ax=axs[-1],
order=['Low', 'Medium', 'Good', 'High'])
axs[-1].set_title(f"Category vs {var}")
i += 1
plt.tight_layout()
plt.show()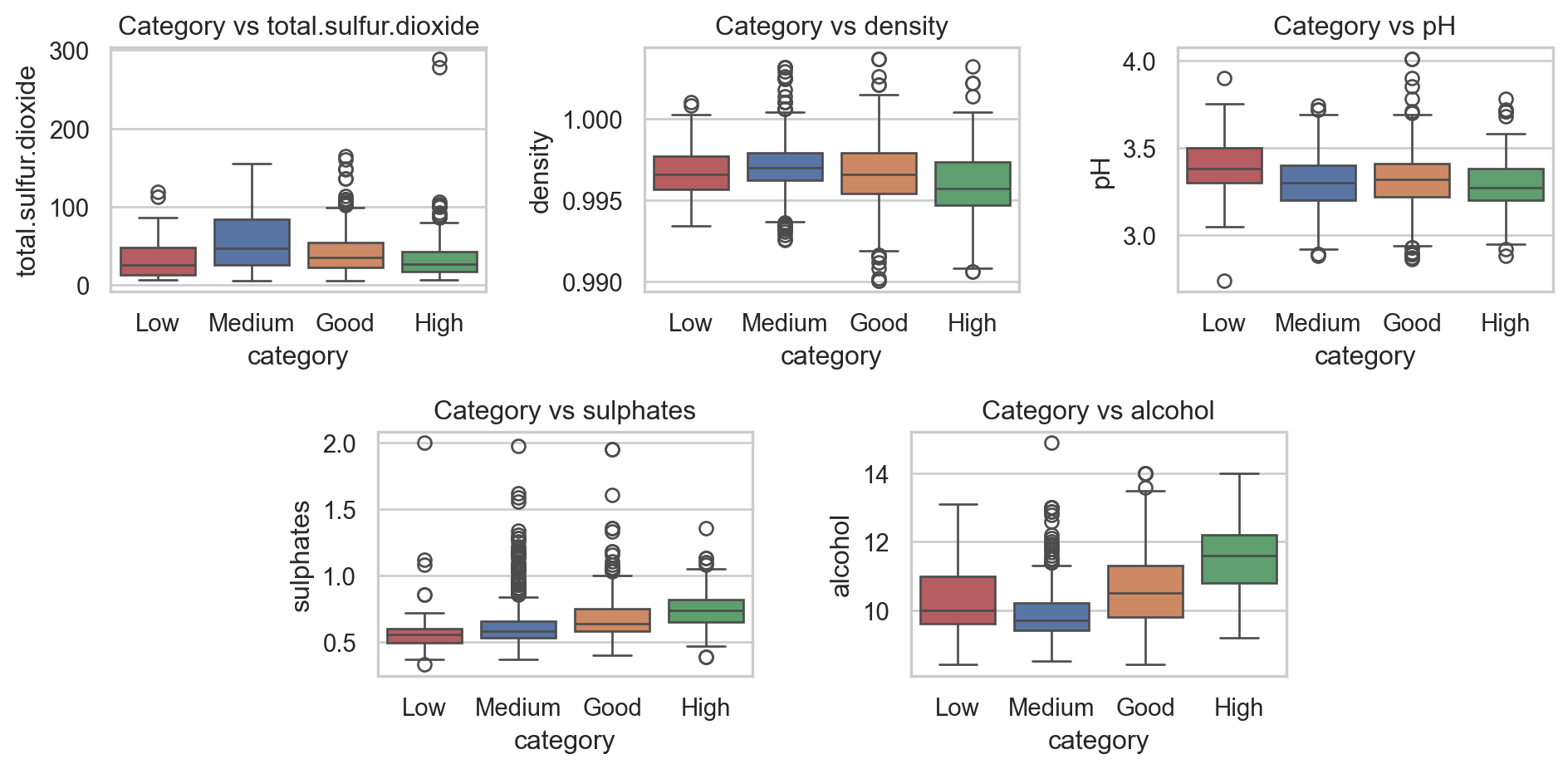
Multinomial Logistic Regression
In action: Kaggle wine quality data
Multinomial Logistic Regression
from sklearn.preprocessing import MinMaxScaler, PolynomialFeatures
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, balanced_accuracy_score, f1_score, recall_score, precision_score, log_loss, confusion_matrix, ConfusionMatrixDisplay
# Train test split
X_wine_train, X_wine_test, y_wine_train, y_wine_test = train_test_split(
df_wine.iloc[:,:-2], df_wine['category'], test_size=0.25,
stratify=df_wine['category'],
random_state=42)
# Scaling data
scaler = MinMaxScaler()
# Fitting the model
X_wine_train = scaler.fit_transform(X_wine_train)
X_wine_test = scaler.transform(X_wine_test)
lgr = LogisticRegression(max_iter=300)
lgr_fit = lgr.fit(X_wine_train, y_wine_train)
y_hat_test1 = lgr_fit.predict(X_wine_test)
performance1 = pd.DataFrame( {
'Acc': [accuracy_score(y_wine_test, y_hat_test1)],
'Balanced Acc': [balanced_accuracy_score(y_wine_test, y_hat_test1)],
'Precision': [precision_score(y_wine_test, y_hat_test1, average="macro")],
'Recall': [recall_score(y_wine_test, y_hat_test1, average="macro")],
'F1-score': [f1_score(y_wine_test, y_hat_test1, average="macro")] }, index=['Logit'])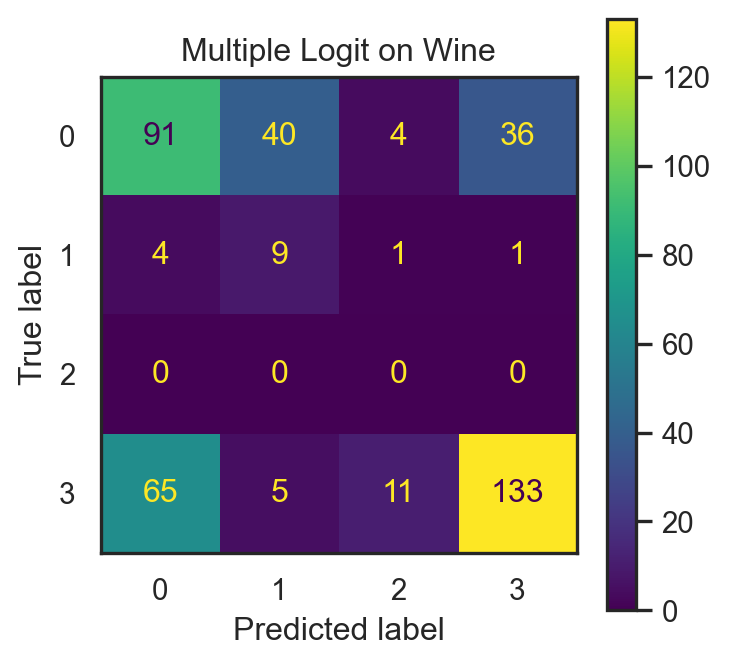
| Acc | Balanced Acc | Precision | Recall | F1-score | |
|---|---|---|---|---|---|
| Logit | 0.5825 | 0.379442 | 0.438415 | 0.379442 | 0.375857 |
Multinomial Logistic Regression
In action: Kaggle wine quality data
Multinomial Logistic Regression with Polynomial Features
degree = list(range(2,9,2))
# List to store all losses
poly_loss, poly_test_loss, test_loss = [], [], {}
for deg in degree:
pf = PolynomialFeatures(degree=deg)
X_poly = pf.fit_transform(X_wine_train)
model = LogisticRegression(max_iter=300)
score = -cross_val_score(model, X_poly, y_wine_train, cv=10,
scoring='neg_log_loss').mean()
poly_loss.append(score)
# Fit and predict
model = model.fit(X_poly, y_wine_train)
X_poly_test = pf.transform(X_wine_test)
y_hat_test = model.predict(X_poly_test)
prob = model.predict_proba(X_poly_test)
poly_test_loss.append(log_loss(y_wine_test, prob))
test_loss['Acc'] = [accuracy_score(y_wine_test, y_hat_test)]
test_loss['Balanced Acc'] = [balanced_accuracy_score(y_wine_test, y_hat_test)]
test_loss['Precision'] = [precision_score(y_wine_test, y_hat_test, average="macro")]
test_loss['Recall'] = [recall_score(y_wine_test, y_hat_test, average="macro")]
test_loss['F1-score'] = [f1_score(y_wine_test, y_hat_test, average="macro")]
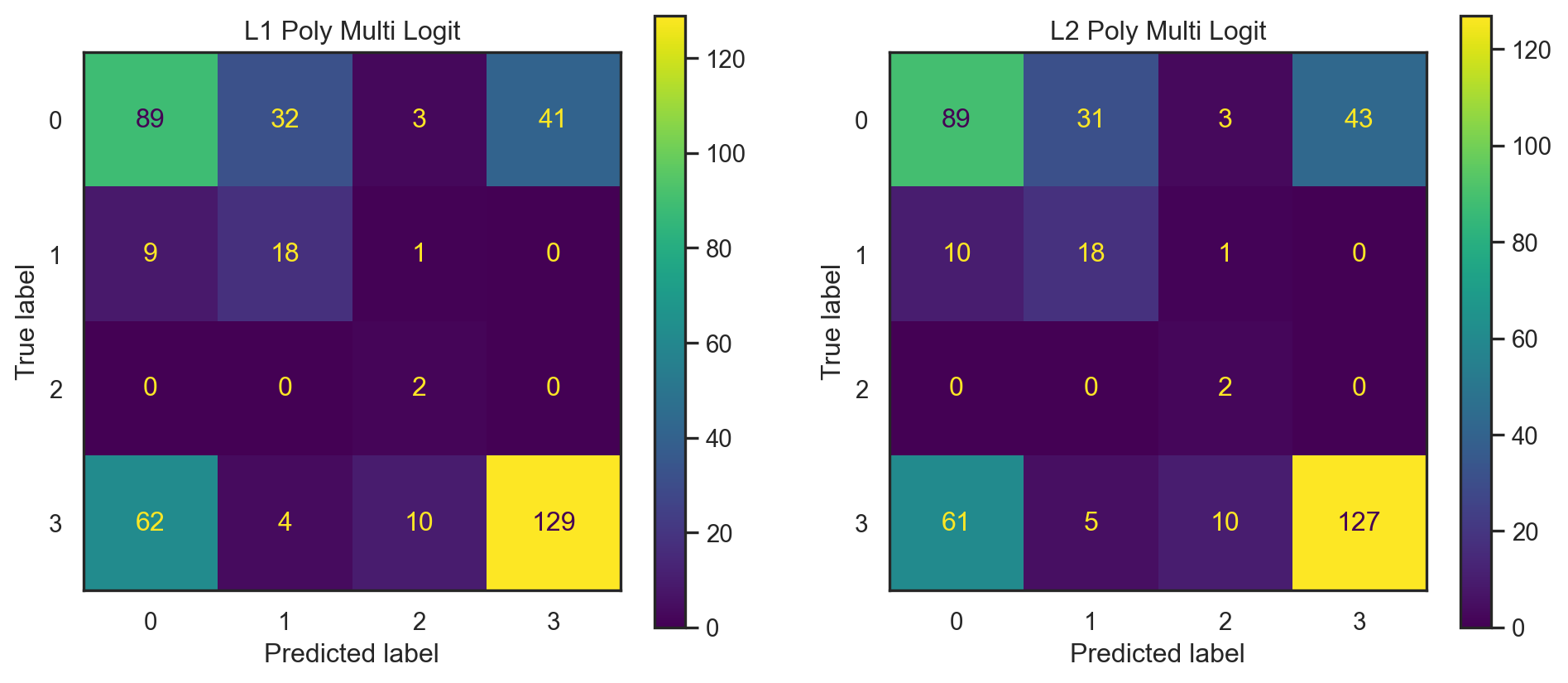
performance1 = pd.concat([performance1, pd.DataFrame(test_loss, index=[f'Poly {deg}'])])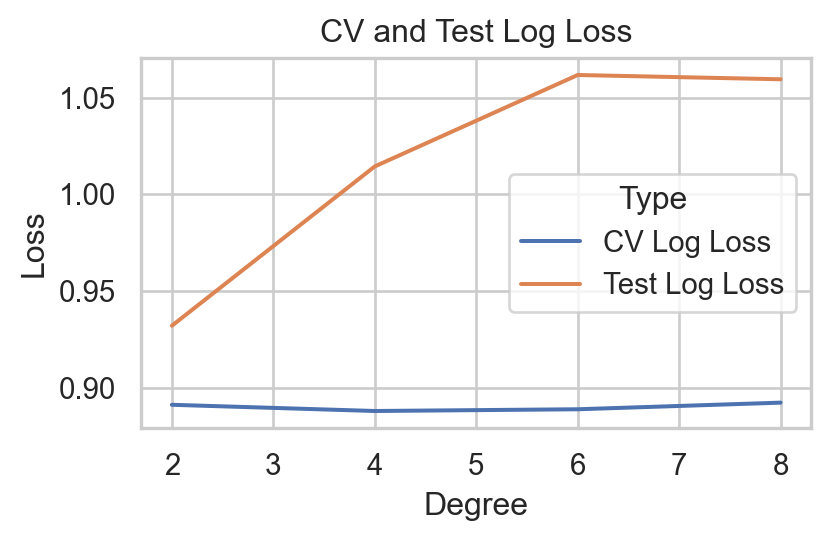
| Acc | Balanced Acc | Precision | Recall | F1-score | |
|---|---|---|---|---|---|
| Logit | 0.5825 | 0.379442 | 0.438415 | 0.379442 | 0.375857 |
| Poly 2 | 0.5850 | 0.407704 | 0.708400 | 0.407704 | 0.426100 |
| Poly 4 | 0.5925 | 0.432772 | 0.711266 | 0.432772 | 0.464086 |
| Poly 6 | 0.5925 | 0.435747 | 0.707423 | 0.435747 | 0.467052 |
| Poly 8 | 0.5925 | 0.435747 | 0.707353 | 0.435747 | 0.467121 |
Multinomial Logistic Regression
Summary
![]()