🤔 តើអ្វីជាសិក្ខាម៉ាសុីន?
សិក្ខាម៉ាសុីនឬជាភាសារអង់គ្លេសហៅថា Machine Learning គឺជាការសិក្សាដែលផ្តោតលើវិធីសាស្រ្តដែលអាចឲ្យម៉ាសុីនកុំព្យូទ័ររៀននិងបង្កើនសមត្ថភាពរបស់វាក្នុងកិច្ចការណាមួយតាមរយៈការរៀននិង ចាប់យកពត៌មានពីទិន្នន័យ។ បញ្ញាសិប្បនិម្មិត (AI ឬ Artificial Intelligence) ជាបង្គុំនៃវិធីសាស្រ្តសិក្ខាម៉ាសុីន (Machine Learning Methods) ជាច្រើនប្រភេទបញ្ចូលគ្នា។
ដើម្បីងាយស្រួលស្វែងយល់អំពីសិក្ខាម៉ាសុីនយើងគួរស្គាល់ពាក្យគន្លឹះមួយចំនួនខាងក្រោមជាមុនសិន៖
ទិន្នន័យ (Data): ជាបេះដូងនៃសិក្ខាម៉ាសុីនហើយជាទូទៅយើងចែកទិន្នន័យជាផ្នែក input \(x\) (ទិន្នន័យដែលជាធាតុដើមសម្រាប់បម្លែងទៅជាលទ្ធផលនៃប្រតិបត្តិការ) និង output ឬ target \(y\) ដែលជាលទ្ធផលឬ ជាអថេរដែលយើងចង់ប៉ាន់ស្មានដោយប្រើប្រាស់ input \(x\) ។
លំនាំគម្រូឬ ម៉ូដែល (Model): ជាវិធីសាស្រ្តឬ ជាអនុគមន៍ \(f\) ដែលបម្លែងពី input \(x\) ទៅជាការព្យាករណ៍នៃ output \(y\) ដែលមានន័យថា៖ \(f(x)\approx y\) ។
រង្វាស់នៃកំហុសឬ ពិន្ទុ (Loss ឬ score): ជារង្វាស់ដែលប្រើដើម្បីវាយតម្លៃគុណភាពនៃម៉ូដែល។ កំហុសឬ ពិន្ទុជាអនុមន៍នៃម៉ូដែលហើយវាអាស្រ័យនឹងទិន្នន័យដែលយើងមាន។ ម៉ូដែលដែលល្អសម្រាប់កិច្ចការមួយគឺជាម៉ូដែលដែលបង្កើតកំហុសតិចឬ មានពិន្ទុច្រើនក្នុងប្រតិបត្តិការនោះ។
វិធីសាស្រ្តបរមាកម្ម (Optimization algorithm): ជាវិធីសាស្រ្តដែលយើងអាចប្រើដើម្បីស្វែងរកម៉ូដែលដែលល្អសម្រាប់ប្រតិបត្តការណ៍មួយ។ ដោយសារម៉ូដែលដែលល្អជាម៉ូដែលដែលផ្តល់កំហុសតិចឬ មានពិន្ទុច្រើន នោះការស្វែងរកម៉ូដែលដែលសមស្របគឺជាការធ្វើបរិមាកម្មលើអនុគមន៍នៃកំហុសឬ ពិន្ទុ ធៀបនឹងម៉ូដែល។
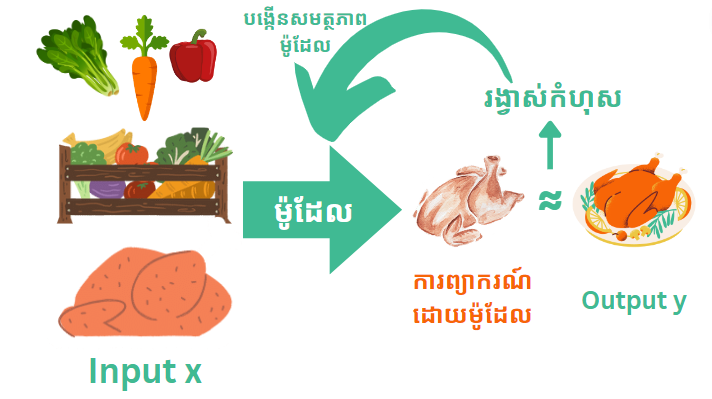
បើយើងមានទិន្នន័យសម្រាប់បង្វឹកម៉ូដែល (Traingn data) \({\cal T}=\{(x_1,y_1),...,(x_n,y_n)\}\) ដែលប្រដូចនឹងរូបទី១ខាងលើគឺ input \(x_i\) ដូចជាគ្រឿងផ្សំសម្រាប់ចម្អិនម្ហូប \(y_i\) (output) ។ យើងអាចប្រើទិន្នន័យនេះទៅបង្វឹកម៉ូដែលដែលអាចបម្លែងគ្រឿងផ្សំ \(x\) ថ្មីណាមួយឲ្យទៅជាម្ហូប \(y\) ណាមួយដោយរៀនតាមទិន្នន័យដែលមានក្នុង \(\cal T\) ។
មកដល់ត្រឹមនេះអ្វីៗនៅមិនទាន់ច្បាស់លាស់នៅឡើងទេដោយសារមានបញ្ហាជាច្រើនដែលយើងមិនទាន់បានបង្ហាញឲ្យច្បាស់ដូចជា៖
តើគូ input-output \((x_i,y_i)\) នីមួយៗត្រូវតាងឬ បញ្ចូលទៅក្នុងម៉ូដែលដោយរបៀបណា?
តើម៉ូដែលមានរូបមន្តបែបណា? តើយើងធ្វើបែបណាទើបអាចជ្រើសបានម៉ូដែលដែលល្អ?
តើម៉ូដែលអាចរៀនពីទិន្នន័យដោយរបៀបណា?
ចម្លើយនៃសំនួរទាំងនេះនឹងត្រូវបានបកស្រាដោយលំអិតជាបណ្តើរៗនៅផ្នែកបន្តរបន្ទាប់ទៀត ប៉ុន្តែអ្វីដែលសំខាន់បំផុតក្នុងផ្នែកនេះគឺ ការស្គាល់ជាដំបូងពីដំណើរការនៃធាតុសំខាន់ៗរបស់សិក្ខាម៉ាសុីនដែលបានរៀបរាប់ខាងលើឲ្យបានច្បាស់លាស់ជាមុនសិន។ គំនូរជីវចលខាងក្រោមសង្ខេបពីដំណើរការជាទូទៅនៃសិក្ខាម៉ាសុីន។

⚖️ ការសរសេរកម្មវិធីធម្មតានិង សិក្ខាម៉ាសុីន
ក្នុងការសរសេរកម្មវិធីធម្មតាឬ Traditional programming មនុស្សជាអ្នកសង្កេតពីចំណោទបញ្ហានិង ស្វែងរកដំណោះស្រាយដោយបង្កើតបានជា កម្មវិធី ដែលជារូបមន្តសម្រាប់បម្លែងពី input ទៅជា output ។
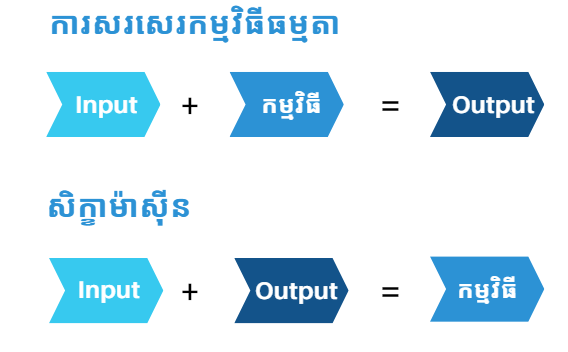
ដោយឡែកក្នុងសិក្ខាម៉ាសុីន យើងមានម៉ូដែល ដែលប្រៀបដូចជាកម្មវិធីសម្រាប់បម្លែងពី input ទៅជា output រួចហើយ ប៉ុន្តែវានៅអាស្រ័យនិង ប៉ារ៉ាម៉ែត្រគន្លឹះជាច្រើនដែលត្រូវការកែរតម្រូវដើម្បីឲ្យវាអាចក្លាយជាម៉ូដែលដែលល្អមួយ នេះមានន័យថាយើងត្រូវផ្តល់ឲ្យម៉ូដែលទាំង input និង output ដើម្បីធ្វើបរមាកម្មនិង ស្វែងរកកម្រិតប្រសើរសមស្របមួយសម្រាប់ម៉ូដែលនៃសិក្ខាម៉ាសុីន។ ហេតុនេះជំនួសឲ្យការសង្កេតពីមនុស្ស ដើម្បីបង្កើតកម្មវិធីយើងផ្តល់ឲ្យម៉ូដែលនូវទិន្នន័យទាំង input និង output សម្រាប់ឲ្យវារៀននិង ឈានទៅដល់កម្រិតមួយដែលអាចយកទៅប្រើប្រាស់ជាកម្មវិធីសម្រេច។
ឧទាហរណ៍៖ ជំនួសឲ្យការពិនិត្យរកភាពខុសប្លែកគ្នារវាង email ដែលជា spam និង មិនមែន spam យើងប្រើម៉ូដែលមួយដែលព្យាករណ៍ប្រភេទ email តាមរយៈការប្រៀបធៀប email នោះទៅនឹង email ទាំងអស់ដែលយើងមាន ហើយពិនិត្យមើលតែ email ចំនួន ១០ ដែលស្រដៀងនឹងវាបំផុត។ បើក្នុងចំណោម email ទាំង ១០ នោះសំបូរដោយ email ជា spam ច្រើនជាង email ដែលមិនមែនជា spam នោះយើងអាចសន្មត់ថា email ថ្មីនោះក៏គួរតែជា spam ដែរ។ នេះជាលំនាំមួយនៃម៉ូដែលសិក្ខាម៉ាសុីនដែលគេស្គាល់ថាជាម៉ូដែល \(K\)-Nearest Neighbors ឬ \(K\)NN (អ្នកនៅក្បែរជាងគេចំនួន \(K\) នាក់) ។ បញ្ហាដែលគួរចោទសួរក្នុងករណីនេះគឺថាតើហេតុអ្វីយើងពិនិត្យមើលតែ email ចំនួន ១០ ដែលស្រដៀងនឹង email ថ្មីនោះ? ជាទូទៅ ការស្វែងរកតម្លៃ \(K\) (ចំនួន email ដែលត្រូវយកទៅកំណត់ប្រភេទនៃ email ថ្មី) គឺជាបញ្ហាបរមាកម្មដែលយើងត្រូវកំណត់រកធ្វើយ៉ាងណាឲ្យលំនាំនៃការព្យាករណ៍តាមវិធីប្រៀបធៀបខាងលើនេះមានសមត្ថភាពដំណើរការបានល្អជាទូទៅនៅលើទិន្នន័យដែលយើងមាន។ ចំពោះថាតើយើងធ្វើបរមាកម្មដើម្បីស្វែងរក ដែលល្អបំផុតដោយរបៀបណា យើងនឹងបានឃើញនៅមេរៀនក្រោយៗទៀតដែលនិយាយអំពីការជ្រើសរើសម៉ូដែលសមស្រប តែក្នុងឧទាហរណ៍នេះ យើងគ្រាន់តែចង់បង្ហាញពីលំនាំនៃការព្យាករណ៍ប្រភេទ email មួយបែបតាមវិធីសាស្រ្តសិក្ខាម៉ាសុីនប៉ុណ្ណោះ។
🤓 ផ្នែកសំខាន់ៗនៃសិក្ខាម៉ាសុីន
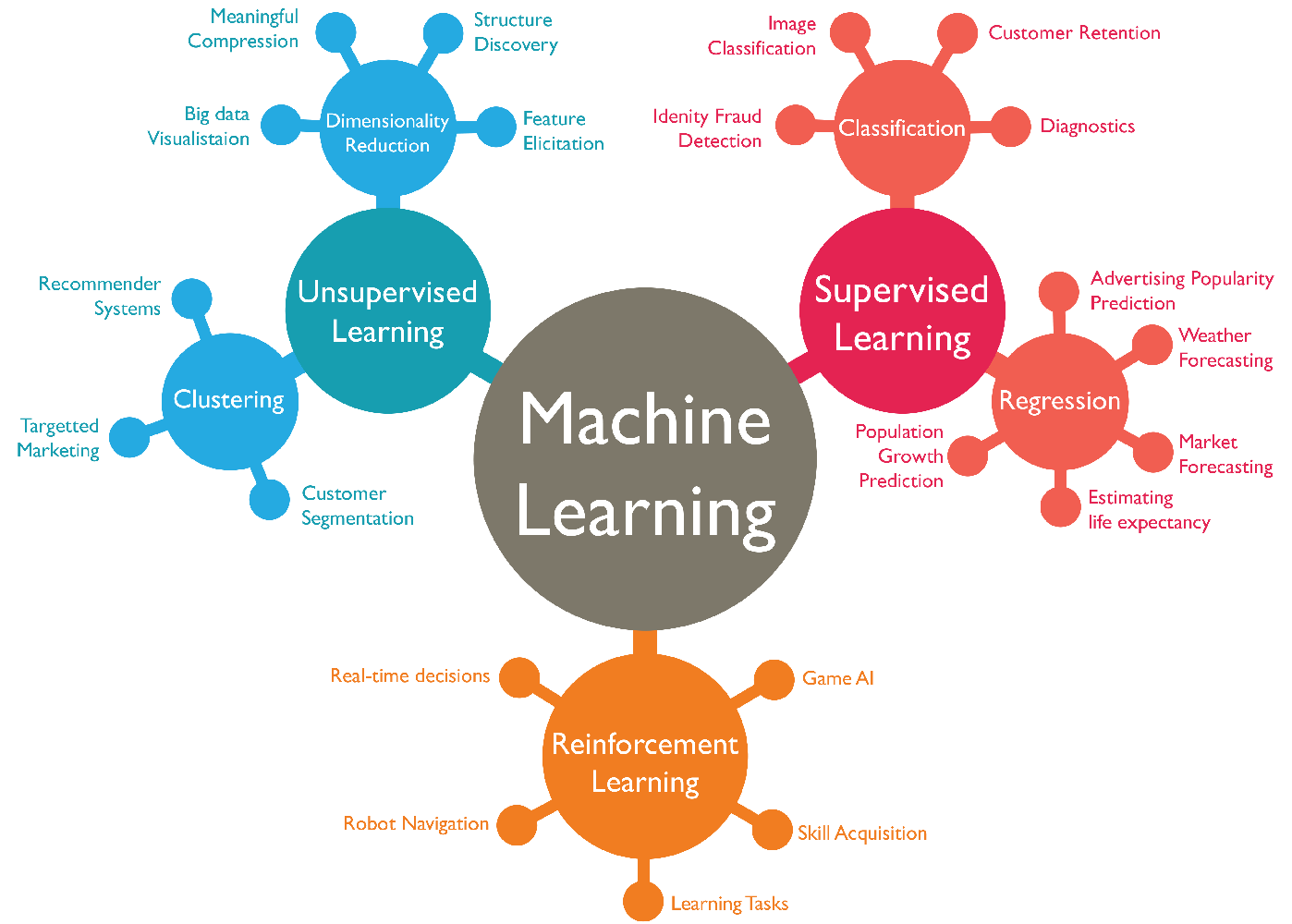
សិក្ខាម៉ាសុីនត្រូវបានបែងចែកជាផ្នែកសំខាន់ៗដូចខាងក្រោម។
🤓.🤓 សិក្ខាម៉ាសុីនបែបមានការណែនាំ (Supervised learning)
ការរៀបរាប់ពីសិក្ខាម៉ាសុីនខាងលើគឺមានទម្រង់បែបមានការណែនាំ ពីព្រោះយើងមាន input ហើយនិង output ។ ជាទូទៅ សិក្ខាម៉ាសុីនបែបមានការណែនាំ ឬ Supervised Machine Learning មានទម្រង់ជាការប្រើប្រាស់ input ទៅព្យាករណ៍ឬប៉ាន់ប្រមាណតម្លៃនៃ output តាមរយៈម៉ូដែល។ ពាក្យថា ណែនាំ (supervised) នៅទីនេះសំដៅដល់ការដែលការព្យាករណ៍នៃម៉ូដែល (និយមតាងដោយ \(\hat{y}\) ) អាចយកទៅធៀបនឹងតម្លៃ output ពិតប្រាកដ ហើយយើងអាចប្រើកំហុសនៃការព្យាករណ៍នេះទៅពង្រឹងសមត្ថភាពនៃម៉ូដែលឬ និយាយឲ្យចំគឺយើងជ្រើសរើសម៉ូដែលដែលបង្កើតកំហុសតិចបំផុត។ ឧទាហរណ៍៖
ការបែងចែក email ថាជាប្រភេទ spam ឬ មិនមែន spam ដូចឧទាហរណ៍ដែលលើកឡើងក្នុងផ្នែកមុន។
ការព្យាករណ៍តម្លៃទីផ្សារដោយប្រើប្រាស់តម្លៃសន្ទស្សន៍សេដ្ខកិច្ចផ្សេងៗដូចជា តម្លៃប្រេងឥន្ទនៈ តម្លៃអត្រាប្តូរប្រាក់ ឬតម្លៃមាសជាដើម។
ការព្យាករណ៍សីតុណ្ណភាពនៅថ្ងៃខាងមុខដោយប្រើប្រាស់ទិន្នន័យនៃចរន្តបរិយាកាសដែលមានខ្នាតធំៗ (large-scale flows) ដូចជាល្បឿនខ្យល់ជាដើម។
ជាទូទៅយើងអាចចែកសិក្ខាម៉ាសុីនបែបមានការណែនាំជាពីរប្រភេទគឺ៖
តម្រែតម្រង់តម្លៃ (regression): ជាប្រតិបត្តិការដែលតម្លៃ output ដែលត្រូវប៉ាន់ស្មានជាចំនួនពិត (\(y\in\mathbb{R}\)) ដូចជា តម្លៃទីផ្សារ សីតុណ្ណភាពឬ តម្លៃជាបរិមាណផ្សេងៗទៀត។
ការធ្វើចំណែកថ្នាក់បែបមានការណែនាំ (supervised classification): ជាប្រតិបត្តិការដែល output ជាប្រភេទគុណភាពឬ ជាប្រភេទក្រុមៗនៃវត្ថុដូចជា ការសម្គាល់រូបភាពថាជាសត្វឆ្កែឬ ឆ្មា (មាន២ជម្រើសសម្រាប់ output \(y\)) ការសម្គាល់រូបភាពថាជាលេខណាមួយនៃសំណុំ \(\{0,1,...,9\}\) ឬការព្យាករណ៍ថាមានភ្លៀងធ្លាក់ឬអត់នៅថ្ងៃស្អែកជាដើម។
🤓.🤓 សិក្ខាម៉ាសុីនបែបគ្មានការណែនាំ (Unsupervised learning)
ពាក្យថា គ្មានការណែនាំ (unsupervised) នៅទីនេះសម្តៅដល់អវត្តមាននៃ output \(y\) ក្នុងប្រតិបត្តិការ។ ក្នុងកិច្ចការប្រភេទនេះ ទិន្នន័យដែលប្រើប្រាស់មានតែ input \(x\) ប៉ុណ្ណោះ ដោយគោលដៅនៃប្រតិបត្តិការគឺស្វែងយល់ពីទំនាក់ទំនងរវាងទិន្នន័យ ភាពស្រដៀងគ្នានៃទិន្នន័យឬ ការបម្លែងទិន្នន័យឲ្យមានភាពងាយស្រួលក្នុងការគណនាជាងមុន។ ជារួម សិក្ខាម៉ាសុីនប្រភេទគ្មានការណែនាំមិនមានគោលដៅក្នុងការព្យាករណ៍តម្លៃ output ណាមួយនោះទេ តែយើងផ្តោតសំខាន់លើការស្វែងយល់ពីទ្រង់ទ្រាយនិង លក្ខណៈស្រដៀងគ្នានៃទិន្នន័យ ។ ឧទាហរណ៍៖
យើងមានទិន្នន័យនៃអ្នកប្រើប្រាស់បណ្តាញសង្គមហើយយើងចង់ដាក់ពួកគាត់ជាក្រុមៗដែលអ្នកប្រើប្រាស់ដែលមានលក្ខណៈស្រដៀងគ្នាត្រូវស្ថិតក្នុងក្រុមជាមួយគ្នាដើម្បីងាយស្រួលគ្រប់គ្រងឬ ផ្សាយពាណិជ្ជកម្មជាដើម។
ការធ្វើចំណែកថ្នាក់សៀវភៅនៅក្នុងបណ្ណាល័យ ការបែងចែករុក្ខជាតិឬ សត្វល្អិតទៅតាមលក្ខណៈរបស់វា។
ការបន្ថយវិមាត្រឬទំហំឌីជីថលនៃរូបភាពដើម្បីសន្សំសំចៃទំហំនៃការរក្សាទុករូបភាព ឬដើម្បីពន្លឿនការគណនាដោយប្រើប្រាស់រូបភាពជាដើម។
ក្នុងឧទាហរណ៍ទី១និង ទី២ខាងលើ យើងចង់ដាក់ទិន្នន័យជាក្រុមៗអាស្រ័យនឹងលក្ខណៈស្រដៀងឬ ខុសគ្នានៃទិន្នន័យដែលគេហៅថា ការធ្វើបំណែងចែកជាក្រុមដោយគ្មានការណែនាំ (unsupervised classification ឬ clustering) ចំណែកឧទាហរណ៍ទី៣គឺការបន្ថយវិមាត្រនៃទិន្នន័យ ឬ ទំហំនៃការរក្សាទុកទិន្នន័យដើម្បីពន្លឿនការគណនាដែលគេហៅថា ការបន្ថយវិមាត្រនៃទិន្នន័យ (dimensional reduction) ។
🤓.🤓 សិក្ខាម៉ាសុីនបែបពង្រឹងឡើងវិញ (Reinforcement learning)
ជាផ្នែកមួយនៃសិក្ខាម៉ាសុីននិង ការគ្រប់គ្រោងចាត់ចែងប្រកបដោយប្រសិទ្ធភាព (optimal control) ដែលដំណើរការដោយ ភ្នាក់ងារ (agent) ឬ ម៉ូដែលគ្រឹះធ្វើសកម្មភាពក្នុងប្រតិបត្តិការណ៍មួយផ្តោតលើអតិបរមាកម្មនៃរង្វាន់ឬ ពិន្ទុសរុបដែលអាស្រ័យនឹងសកម្មភាពដែលបានធ្វើរបស់ភ្នាក់ងារក្នុងប្រតិបត្តិការណ៍នោះ។ ប្រតិបត្តិការណ៍ប្រភេទនេះមានភាពខុសគ្នាពីផ្នែកសិក្ខាម៉ាសុីនបែបមានការណែនាំដោយវាមិនត្រូវការ output ដើម្បីកំណត់រង្វាន់ឬ ពិន្ទុនោះទេ តែវាផ្តោតលើការធ្វើឲ្យមានតុល្យភាពរវាងសកម្មភាពដែលមិនទាន់បានធ្វើនៅឡើយនិង ការប្រើប្រាស់អ្វីដែលបានឆ្លងកាត់ហើយ។ វិធីសាស្រ្តប្រភេទនេះត្រូវបានប្រើប្រាស់ក្នុងវិស្ស័យមនុស្សយន្ត ការដោះស្រាយល្បែងកំសាន្តផ្សេងៗដូចជា AlphaGO និងជាពិសេសវាក៏ជាគន្លឹះដ៏សំខាន់នៃការបង្វឹកម៉ូដែលភាសាខ្នាតធំដ៏ល្បីល្បាញគឺ ChatGPT4 ។
📚 ឯកសារសម្រាប់ស្វែងយល់បន្ថែម
សៀវភៅខាងក្រោមជាឯកសារជំនួយដ៏ល្អសម្រាប់អ្នកចង់ស្វែងយល់កាន់តែសុីជម្រៅលើសិក្ខាម៉ាសុីនចាប់ពីមូលដ្ឋានគ្រឹះទៅដល់ការអនុវត្តនិង ការសរសេរកូដក្នុងកម្មវិធីមួយចំនួនដូចជា Python និង R ផងដែរ។







