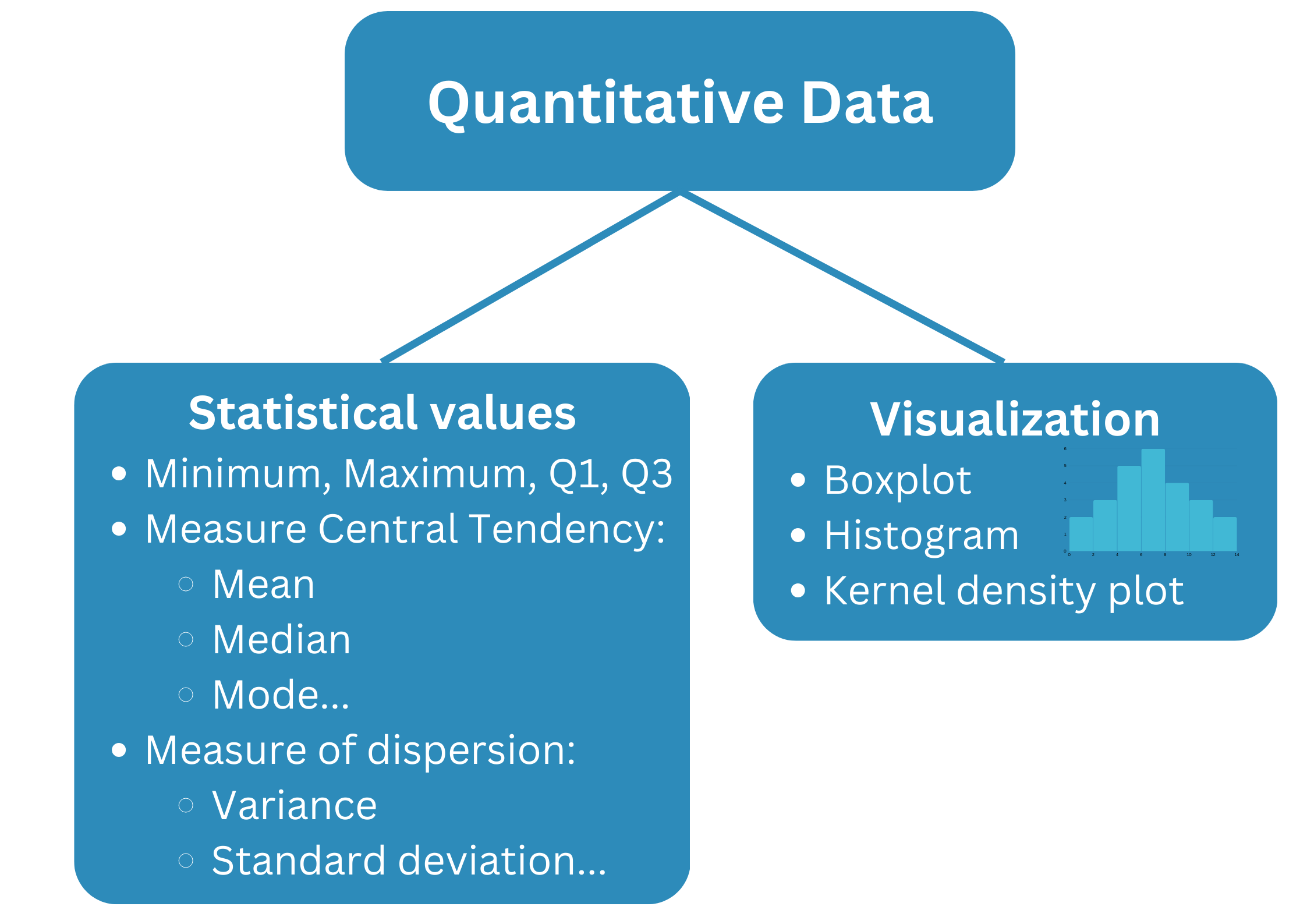
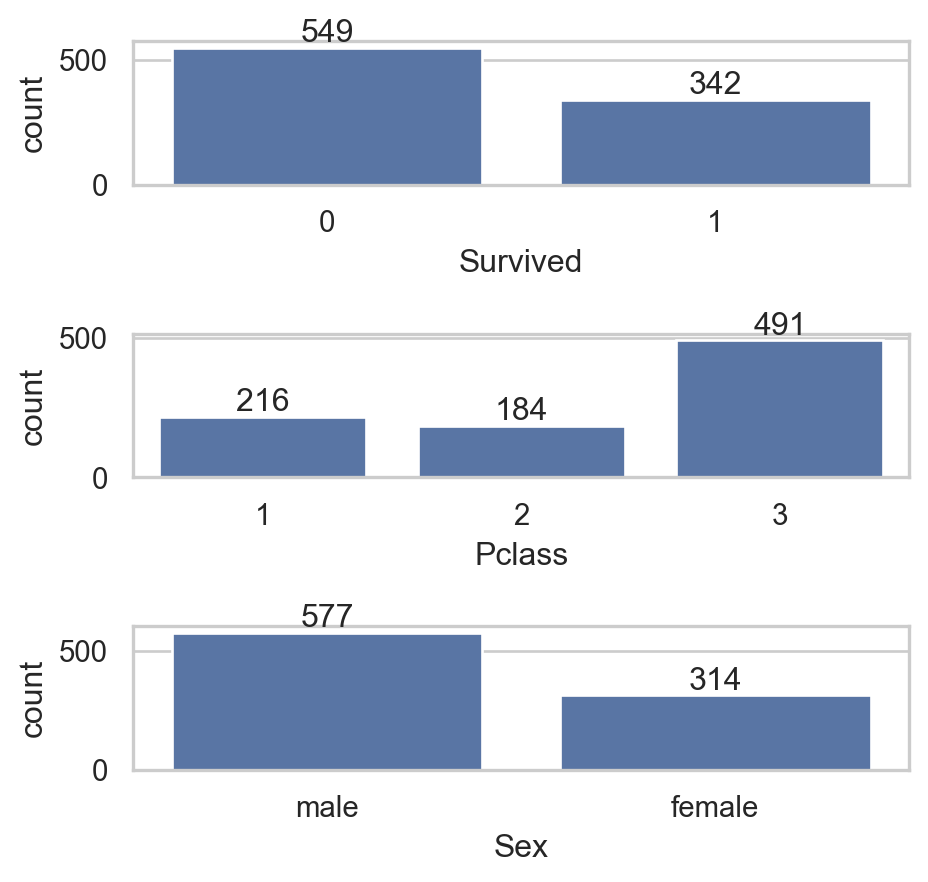
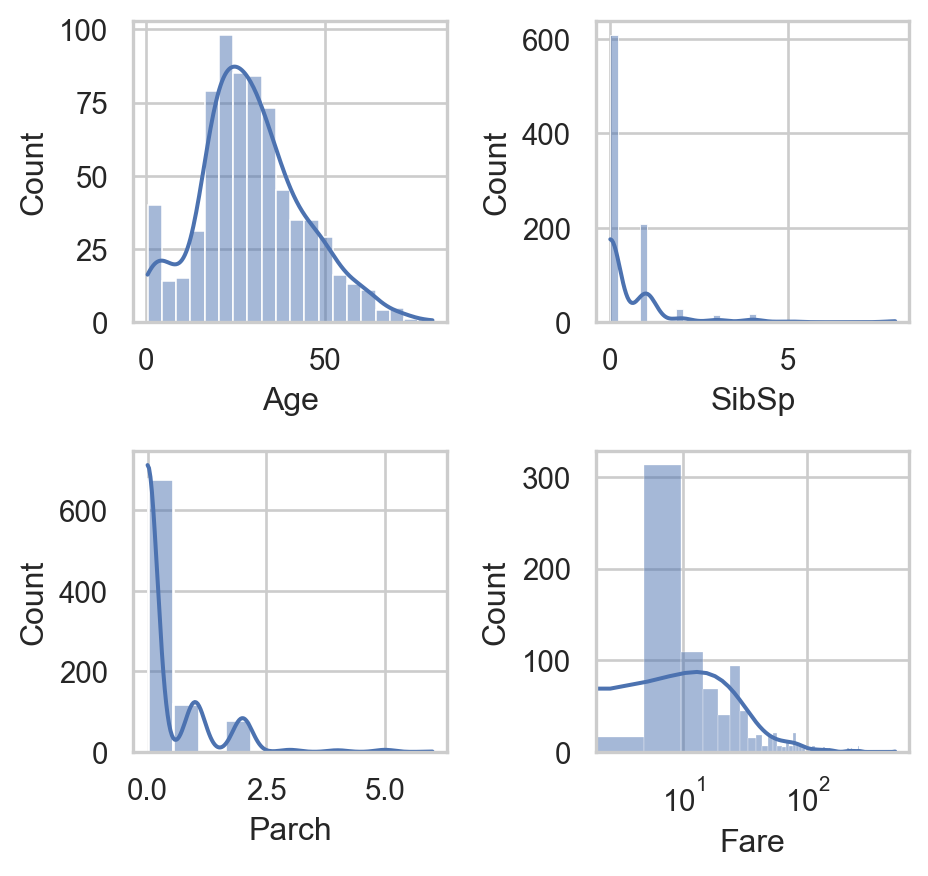
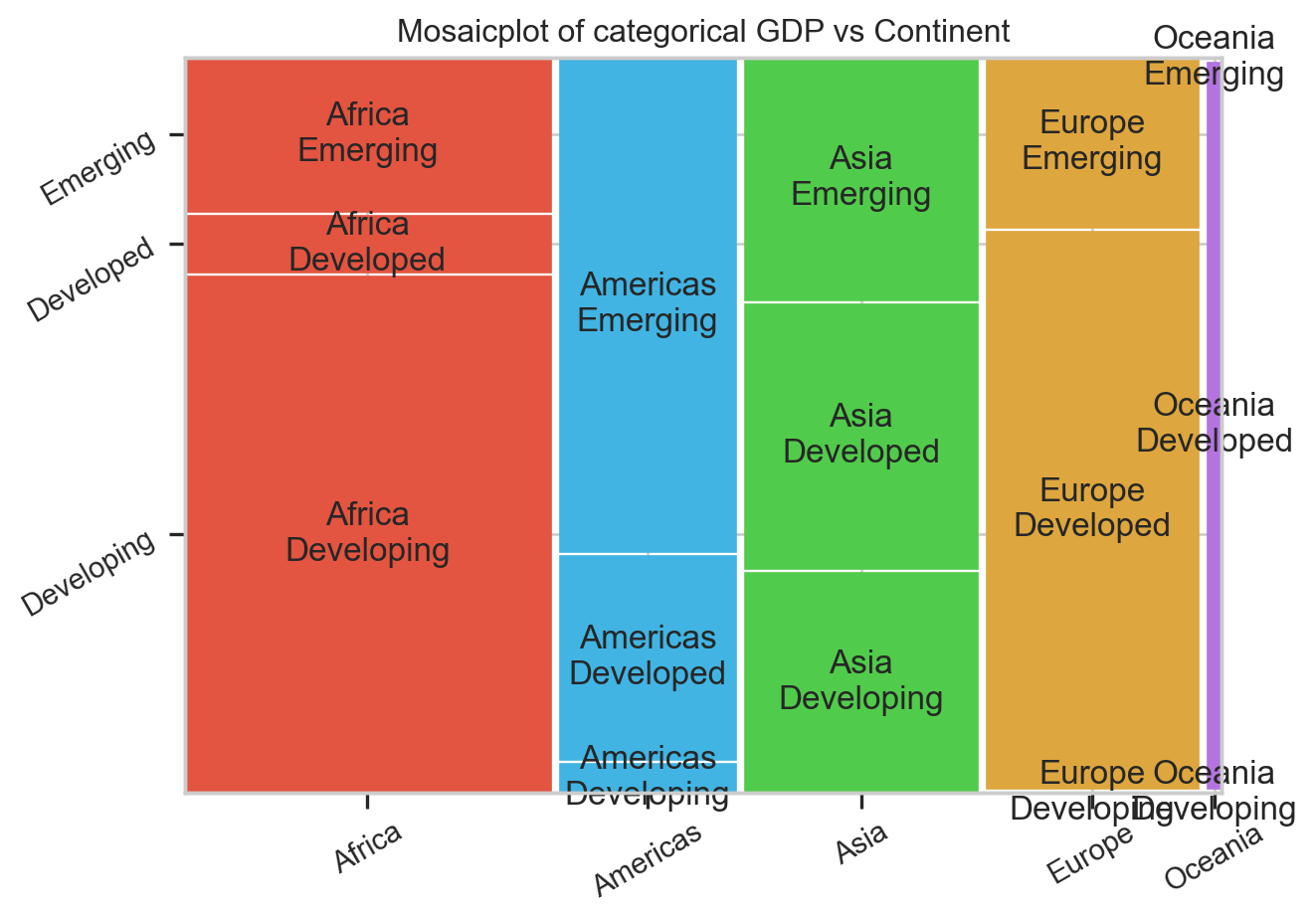
Code
import pandas as pd # Import pandas package
import seaborn as sns # Package for beautiful graphs
import matplotlib.pyplot as plt # Graph management
sns.set(style="whitegrid") # Set grid background
data = pd.read_csv(path_titanic + "/Titanic-Dataset.csv" ) # Import it into Python
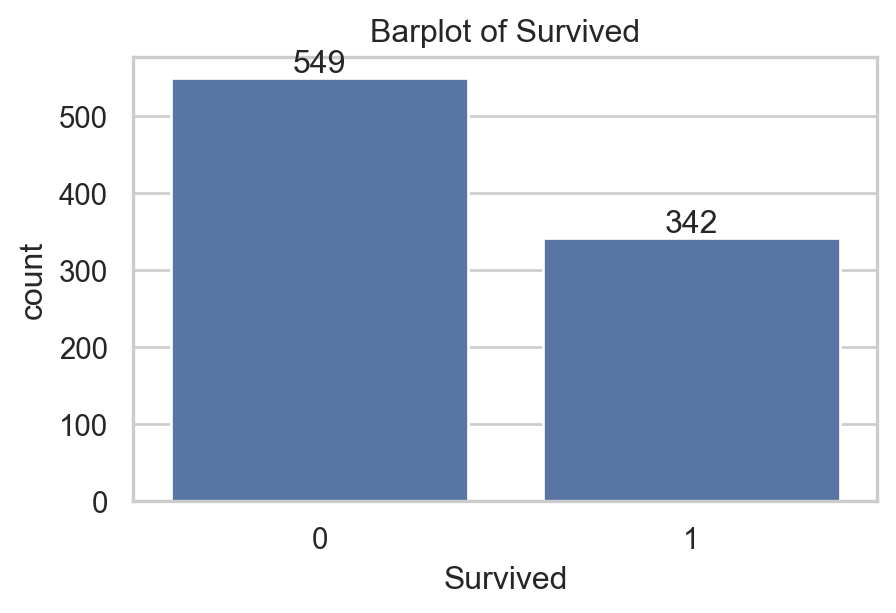
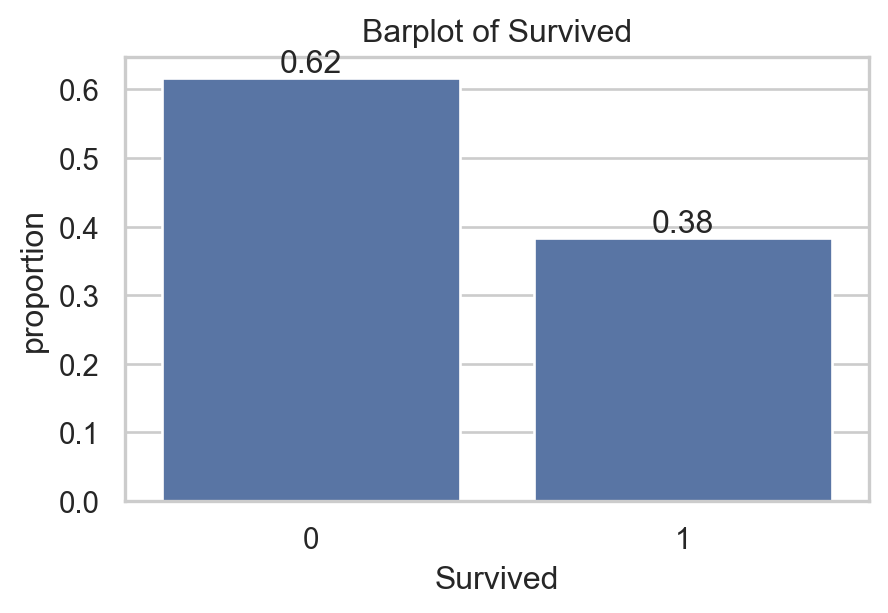
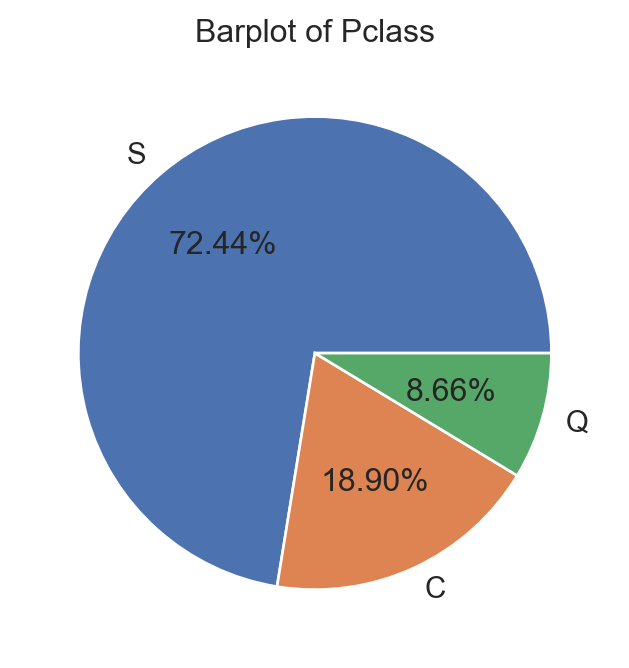
data[['Survived', 'Pclass', 'Age', 'Embarked']].head(5) # Show 5 first rows| Survived | Pclass | Age | Embarked | |
|---|---|---|---|---|
| 0 | 0 | 3 | 22.0 | S |
| 1 | 1 | 1 | 38.0 | C |
| 2 | 1 | 3 | 26.0 | S |
| 3 | 1 | 1 | 35.0 | S |
| 4 | 0 | 3 | 35.0 | S |