Objective: We have seen in the course that nonparametric models aim at directly estimating the regression function of MSE criterion. In this TP, we shall learn how to implement the three basic nonparametric models including \(K\)-NN, Decision Trees and Kernel Smoother method.
Abalone is a popular seafood in Japanese and European cuisine. However, the age of abalone is determined by cutting the shell through the cone, staining it, and counting the number of Rings through a microscope, a boring and time-consuming task. Other measurements, which are easier to obtain, are used to predict the age, including their physical measurements, weights etc. This section aims at predicting the Rings of abalone using its physical measurements. Read and load the data from kaggle: Abalone dataset.
# %pip install kagglehub # if you have not installed "kagglehub" module yetimport kagglehub# Download latest versionpath = kagglehub.dataset_download("rodolfomendes/abalone-dataset")# Import dataimport pandas as pddata = pd.read_csv(path +"/abalone.csv")data.head()
Sex
Length
Diameter
Height
Whole weight
Shucked weight
Viscera weight
Shell weight
Rings
0
M
0.455
0.365
0.095
0.5140
0.2245
0.1010
0.150
15
1
M
0.350
0.265
0.090
0.2255
0.0995
0.0485
0.070
7
2
F
0.530
0.420
0.135
0.6770
0.2565
0.1415
0.210
9
3
M
0.440
0.365
0.125
0.5160
0.2155
0.1140
0.155
10
4
I
0.330
0.255
0.080
0.2050
0.0895
0.0395
0.055
7
A. Overview of the dataset.
What’s the dimension of this dataset? How many quantitative and qualitative variables are there in this dataset?
Create statistical summary of the dataset. Identify problems if there is any in this dataset.
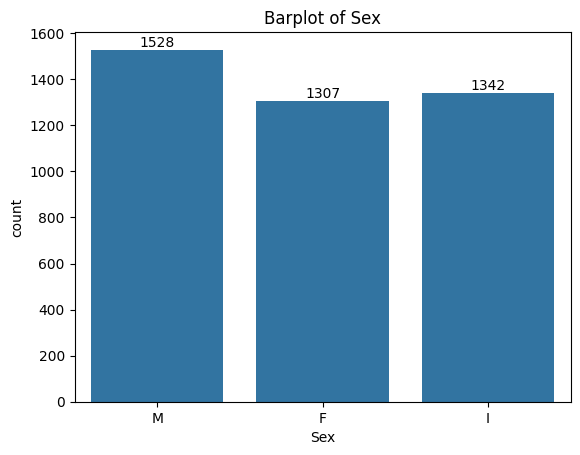
# Qualitative datadata[['Sex']].value_counts(normalize=True).to_frame().Timport matplotlib.pyplot as pltimport seaborn as snsax = sns.countplot(data, x="Sex")ax.set_title("Barplot of Sex")ax.bar_label(ax.containers[0])plt.show()
data.describe().drop(labels=['count'])
Length
Diameter
Height
Whole weight
Shucked weight
Viscera weight
Shell weight
Rings
mean
0.523992
0.407881
0.139516
0.828742
0.359367
0.180594
0.238831
9.933684
std
0.120093
0.099240
0.041827
0.490389
0.221963
0.109614
0.139203
3.224169
min
0.075000
0.055000
0.000000
0.002000
0.001000
0.000500
0.001500
1.000000
25%
0.450000
0.350000
0.115000
0.441500
0.186000
0.093500
0.130000
8.000000
50%
0.545000
0.425000
0.140000
0.799500
0.336000
0.171000
0.234000
9.000000
75%
0.615000
0.480000
0.165000
1.153000
0.502000
0.253000
0.329000
11.000000
max
0.815000
0.650000
1.130000
2.825500
1.488000
0.760000
1.005000
29.000000
print(f'Abalone with 0 height: {sum(data.Height ==0)}')print(f'Number of duplicated data: {sum(data.duplicated())}')
Abalone with 0 height: 2
Number of duplicated data: 0
There are two abalone with 0 heights. We should remove them.
data.query('Height > 0', inplace=True)
Study the correlation matrix of this dataset. Comment this correlation matrix.
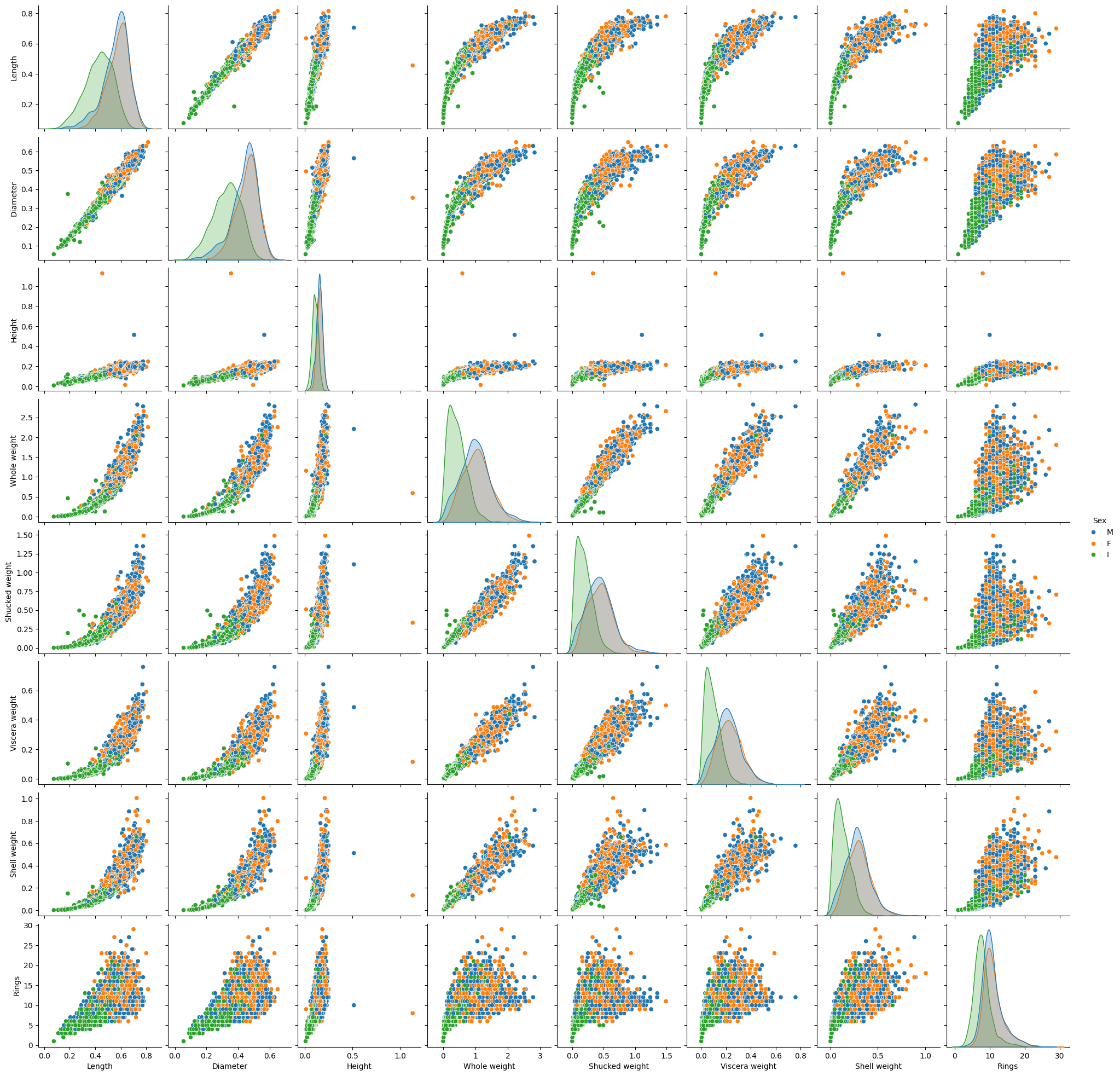
Shell weight appears to be the most correlated input with the target. Moreover, there are many highly correlated pairs which might impact performance of the model. Moreover, as the number of inputs is small enough, we can visualize scatter plot of each pairs as follows.
sns.pairplot(data, hue="Sex")plt.show()
There seems to be outliers in variable height that might impact model performance. Such outliers should be removed.
data.query("Height < 0.5", inplace=True)
B. Model development.
Split the dataset into \(80\%-20\%\) training-testing data using random_state = 42.
print(f'Best tree hyperparameters: {grid_cv.best_params_}')tr = grid_cv.best_estimator_.fit(X_train, y_train)y_pred_tr = tr.predict(X_test)print(f'Test RMSE: {np.sqrt(mean_absolute_error(y_test, y_pred_tr))}')import plotly.graph_objects as gofig1 = go.Figure(go.Scatter(x=y_test, y=y_pred_tr, name="Actual vs Pred", mode="markers", marker=dict(size=10)))fig1.add_trace(go.Scatter(x=y_test, y=y_test, name="Line y = x", mode="lines", line=dict(color='red')))fig1.update_layout(height=500, width=700, title="Actual vs Prediction")fig1.show()
Best tree hyperparameters: {'criterion': 'squared_error', 'max_features': 8, 'min_samples_leaf': 20, 'min_samples_split': 20}
Test RMSE: 1.294609989247988
Unable to display output for mime type(s): application/vnd.plotly.v1+json
Build a Kernel Smoother method to predict the testing data and report its RMSE (my python module: gradientcobra and its module: KernelSmoother).
y_pred_ks = ks.predict(X_test_scaled)print(f'Test RMSE: {np.sqrt(mean_absolute_error(y_test, y_pred_ks))}')import plotly.graph_objects as gofig2 = go.Figure(go.Scatter(x=y_test, y=y_pred_ks, name="Actual vs Pred", mode="markers", marker=dict(size=10)))fig2.add_trace(go.Scatter(x=y_test, y=y_test, name="Line y = x", mode="lines", line=dict(color='red')))fig2.update_layout(height=500, width=700, title="Actual vs Prediction")fig2.show()
Test RMSE: 1.2501940214421492
C. Neural Network.
Design a neural network to predict the testing data and compute its RMSE.
Compre to the previous results and conclude.
# This is an example with Kerasfrom sklearn.metrics import mean_squared_errorfrom keras.models import Sequentialfrom keras.layers import Dense, Inputfrom keras import regularizers# Inputd = X_train.shape[1]model = Sequential()model.add(Input(shape=(d,)))model.add(Dense(64, activation="relu"))model.add(Dense(64, activation="relu"))model.add(Dense(1, activation="linear"))# Set up optimizer for our modelmodel.compile(optimizer='adam', loss='mean_squared_error', metrics=['mse'])# Training the networkhistory = model.fit( X_train_scaled, y_train, epochs=100, batch_size=32, validation_split=0.1, verbose=0)# Extract loss valuestrain_loss = history.history['loss']val_loss = history.history['val_loss']
import plotly.io as piopio.renderers.default ='notebook'# Plot the learning curvesepochs =list(range(1, len(train_loss) +1))fig1 = go.Figure(go.Scatter(x=epochs, y=train_loss, name="Training loss"))fig1.add_trace(go.Scatter(x=epochs, y=val_loss, name="Training loss"))fig1.update_layout(title="Training and Validation Loss", width=800, height=500, xaxis=dict(title="Epoch", type="log"), yaxis=dict(title="Loss"))fig1.show()
y_pred_nn = model.predict(X_test_scaled)print(f'Test RMSE: {np.sqrt(mean_absolute_error(y_test, y_pred_nn))}')import plotly.graph_objects as gofig2 = go.Figure(go.Scatter(x=y_test, y=y_pred_nn.reshape(-1), name="Actual vs Pred", mode="markers", marker=dict(size=10)))fig2.add_trace(go.Scatter(x=y_test, y=y_test, name="Line y = x", mode="lines", line=dict(color='red')))fig2.update_layout(height=500, width=700, title="Actual vs Prediction")fig2.show()
27/27 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step
Test RMSE: 1.2237433819694146
2. Revisit Spam dataset
Your task in this section is to create email spam filters by applying the nonparametric models introduced in the course.
Report test performance metrics on the spam dataset loaded below.
Build a pipeline that takes text input as a real email, then return the type of the email using your best spam filter found in the first question.
path ="https://raw.githubusercontent.com/hassothea/MLcourses/main/data/spam.txt"data = pd.read_csv(path, sep=" ")from sklearn.preprocessing import MinMaxScalerX_train, X_test, y_train, y_test = train_test_split( data.iloc[:,1:-1], data['type'], test_size=0.2, random_state=42)scaler = MinMaxScaler()X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)# One-hot encodingencode = {"spam": 1, "nonspam": 0}decode = {0: "nonspam", 1: "spam"}# y_train = np.array([encode[i] for i in y_train])# y_test = np.array([encode[i] for i in y_test])data.head(5)
Best number of neighbors: {'criterion': 'entropy', 'max_features': 31, 'min_samples_leaf': 65, 'min_samples_split': 10}
Accuracy: 0.8957654723127035
array([[500, 31],
[ 65, 325]], dtype=int64)
We can build a Pipeline that converts real emails to be a data frame of consistent format for our models.
def SpamFilter(email, method ="knn"):def capitals(text, count, symbol): total_capitals =0 longest_sequence =0 current_sequence =0 capital_lengths = [] sym =set(symbol)for char in text:if char.lower() in sym: count[symbol[char]] +=1elif char in count.keys(): count[char] +=1if char.isupper(): total_capitals +=1 current_sequence +=1else:if current_sequence >0: capital_lengths.append(current_sequence)if current_sequence > longest_sequence: longest_sequence = current_sequence current_sequence =0# Append the last sequence if it ends with a capital letterif current_sequence >0: capital_lengths.append(current_sequence)if current_sequence > longest_sequence: longest_sequence = current_sequence average_length =sum(capital_lengths) /len(capital_lengths) if capital_lengths else0 count['capitalTotal'], count['capitalLong'], count['capitalAve'] = total_capitals, longest_sequence, average_lengthreturn count symbol = {'000': 'num000','650': 'num650','857': 'num857','415': 'num415','85': 'num85','1999': 'num1999',';': 'charSemicolon','(': 'charRoundbracket',')': 'charRoundbracket','[': 'charSquarebracket',']': 'charSquarebracket','!': 'charExclamation','$': 'charDollar','#': 'charHash'} count = {x: 0for x in data.columns[1:-1]} count_ = capitals(email, count, symbol) X = pd.DataFrame(count_, index=[0]) X = scaler.transform(X)if method =="knn": pred = knn.predict(X)else: pred = tr.predict(X)return pred[0]
# testemail ='Hi Jack,\n I hope this email find you well. I am writing to ask for the address of Marry because I want to send her an invitation for my wedding.\n\n Thank you for the information.\n\n Best regards, Mark'# This is the prediction by KNNprint(f'KNN predict this email to be: {SpamFilter(email)}')# This is the prediction by Treeprint(f'Tree predict this email to be: {SpamFilter(email)}')
KNN predict this email to be: nonspam
Tree predict this email to be: nonspam