Objective: Predicting target \(y\) using input \(x\).
If \(y\) is continuous, the problem is called Regression.
If \(y\) is discrete/categorical, it’s called Classification.
Criteria
Quality of a prediction \(\hat{y}\) is measured by the loss: \(\ell(\hat{y},y)\).
Quality of a model \(\hat{f}\) is measured by the risk: \[{\cal R}(\hat{f})=\mathbb{E}_{X,Y}[\ell(Y, \hat{f}(X))].\]
Introduction
Supervised Learning Setting
Parametric models assume a specific form that depends on a fixed number of parameters. Example:
Linear model: \(\hat{f}_{\color{blue}{\beta}}(\text{x})=\color{blue}{\beta_0}+\sum_{j=1}^d\color{blue}{\beta_j}x_j\) with \(\color{blue}{\beta_0},\dots,\color{blue}{\beta_d}\in\mathbb{R}.\)
Polynomial model: \(\hat{f}_{\color{blue}{\beta}}(\text{x})=\color{blue}{\beta_0}+\sum_{p=0}^m\sum_{k=1}^d\sum_{j\leq k}\color{blue}{\beta_{jkp}}x_j^{p}x_k^{m-p}\) with \(\color{blue}{\beta_0},\color{blue}{\beta_{jkp}}\in\mathbb{R},\forall j,k,p.\)
Building a model is searching for \(\color{blue}{\beta^*}\) minimizing the risk, i.e., \[{\cal R}(\hat{f}_{\color{blue}{\beta^*}})=\inf_{\color{blue}{\beta}}\Big[\underbrace{{\cal R}(\hat{f}_{\color{blue}{\beta}})}_{\text{Goodness of fit}} + \underbrace{\color{gray}{\Omega(\color{blue}{\beta})}}_{\text{Flexibility}}\Big]\]
Introduction
Supervised Learning Setting
Nonparametric models rely directly on the target \(y\) without assuming any form of input-output relationship.
General weighted average form: \[\hat{f}(\text{x})=\sum_{i=1}^ny_i\color{blue}{W_{n,i}(\text{x})}.\]
Interpretation:
The prediction of \(\text{x}\) is determined by averaging values of targets \(y_i\)’s.
Targets \(y_i\) that their input \(\text{x}_i\) is similar to \(\text{x}\) are more important and carry heavier weight \(\color{blue}{W_{n,i}(\text{x})}\) in the average.
🤔 Why does it work?
🗝️ Because it estimates \(\color{red}{\eta(x)=\mathbb{E}(Y|X=x)}\).
🤔 But what’s this \(\color{red}{\eta(x)}\)?
Theoretical Motivation
Regression theory: \(L_2\)/MSE minimizer
\(\color{blue}{\text{Mean Squared Error}}\) of any model \(\hat{f}\) is defined by: \[\color{blue}{\text{MSE}}(\hat{f})=\mathbb{E}[(\hat{f}(X)-Y)^2].\]
If \(\text{x}\) be an input and \(\color{red}{\eta(\text{x})=\mathbb{E}(Y|X=\text{x})}\) then \(\forall\hat{f}\): \[\begin{align*}
\color{blue}{\text{MSE}}(\hat{f})&=\mathbb{E}[(\hat{f}(X)-\color{red}{\eta}(X))^2]+\mathbb{E}[(\color{red}{\eta}(X)-Y)^2]
\end{align*}\]
This implies that \(\color{red}{\eta}\) is the minimizer of \(\color{blue}{\text{MSE}}\) criterion, i.e., \[\color{blue}{\text{MSE}}(\color{red}{\eta})=\inf_{\hat{f}}\color{blue}{\text{MSE}}(\hat{f})=\mathbb{E}[(\color{red}{\eta}(X)-Y)^2].\]
\(\color{red}{\eta}\) is called Regression Function/\(L_2\) Bayesian Estimator.
Theoretical Motivation
Regression theory: \(L_2\)/MSE minimizer
\(\color{red}{\eta}\) is called Regression Function/\(L_2\) Bayesian Estimator.
\(\color{red}{\eta(\text{x})=\mathbb{E}(Y|X=\text{x})}\)is the average of \(y\) for inputs that are similar to the query point\(\text{x}\). In discrete case: \[\begin{align*}\color{red}{\eta}(\text{x})&=\mathbb{E}(Y|X=\text{x})=\sum_{i=1}^{\infty}y_i\color{blue}{\mathbb{P}(Y=y_i|X=\text{x})}
\end{align*}\]
Recall that nonparam. models: \(\hat{f}(\text{x})=\sum_{i=1}^ny_i\color{blue}{W_{n,i}(\text{x})}.\)
Q1: Why don’t we compute \(\color{blue}{\mathbb{P}(Y=y_i|X=\text{x})}\) directly?
A1: We don’t know the distribution of \(Y|X\).
Weights \(\color{blue}{W_{n,i}(\text{x})}\) plays a role as an estimate of \(\color{blue}{\mathbb{P}(Y=y_i|X=\text{x})}\).
Different choices of weights lead to different nonparametric models.
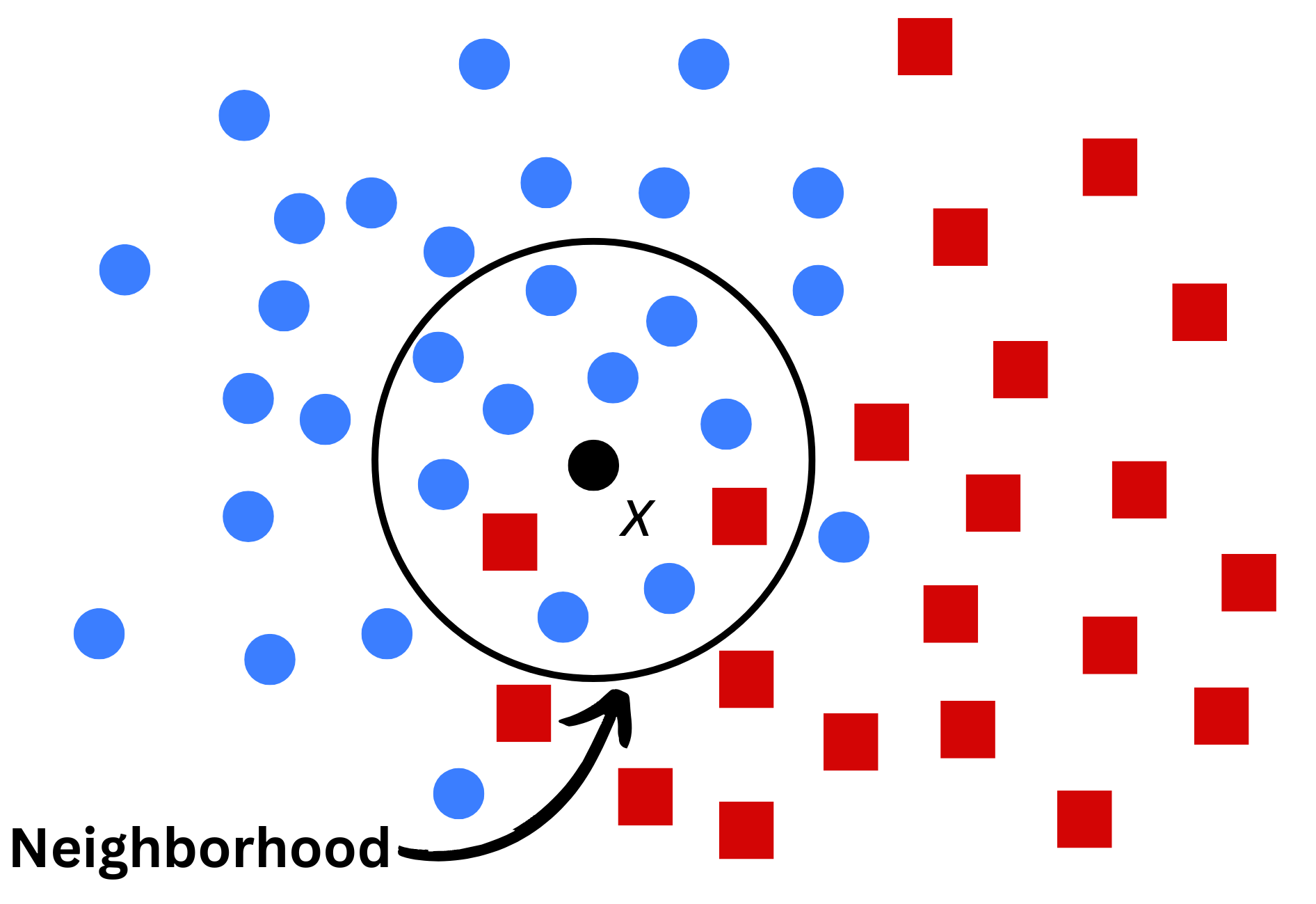
Weights \(\color{blue}{W_{n,i}(\text{x})}\) are often defined according to how “close” \(\text{x}_i\) to \(\text{x}\).
“Closeness” is often described by “metrics, neighborhoods or topological structures”…
Theoretical Motivation
Example: Missing Value Imputation
Code
from skimage import dataimport matplotlib.pyplot as pltimage = data.astronaut()import numpy as npfrom sklearn.impute import KNNImputern_miss =100np.random.seed(42)missing_id = np.random.choice(512, size=(n_miss,2))image_nan = image.copy()for i inrange(n_miss): image_nan[(missing_id[i,0]-2):(missing_id[i,0]+2),(missing_id[i,1]-2):(missing_id[i,1]+2),:] =0plt.figure(figsize=(4,4))plt.imshow(image_nan)plt.axis('off')plt.show()
Code
for i inrange(n_miss):for ch inrange(3): temp = image_nan[(missing_id[i,0]-5):(missing_id[i,0]+5), (missing_id[i,1]-5):(missing_id[i,1]+5), ch] image_nan[(missing_id[i,0]-2):(missing_id[i,0]+2),(missing_id[i,1]-2):(missing_id[i,1]+2),ch] = temp[temp>0].mean()plt.figure(figsize=(4,4))plt.imshow(image_nan)plt.axis('off')plt.show()
Missing pixels \(=\frac{1}{N}\sum_{k=1}^Np_k\) where \(p_k\) are neighboring non-missing pixels.
Q2: What are the weights \(\color{blue}{W_{n,i}(\text{x})}\) in this case?
Theoretical Motivation
Decision theory for classification
In classification, misclassification loss: \(\ell(\hat{f}(x),y)=\mathbb{1}_{\{\hat{f}(x)\neq y\}}=\begin{cases}1,\text{ if }\hat{f}(x)\neq y\\0,\text{ if }\hat{f}(x)=y\end{cases}\).
The misclassification risk is given by: \[{\cal R}_c(\hat{f})=\mathbb{E}[\ell(\hat{f}(X),Y)]=\mathbb{E}[\mathbb{1}_{\{\hat{f}(X)\neq Y\}}]=\mathbb{P}(\hat{f}(X)\neq Y).\]
This is equivalent to classification problems that maximize accuracy score because \[\text{Accuracy}=1-\mathbb{P}(\hat{f}(X)\neq Y)=\mathbb{P}(\hat{f}(X)=Y).\]
In balanced\(M\)-class classification, \[\text{If } g^*(x)=\arg\max_{1\leq k\leq M}\mathbb{P}(Y=k|X=x)\text{ then }{\cal R}_c(g^*)=\inf_{\hat{f}}{\cal R}_c(\hat{f}).\]
Theoretical Motivation
Summary
In regression with MSE, \(\color{red}{\eta(\text{x})=\mathbb{E}(Y|X=\text{x})}\) is the best regressor.
We cannot compute it, but we can estimate it.
Parametric models assume that \(\color{red}{\eta}\) takes some forms (linear, polynomial…).
Nonparametric models attempt to estimate \(\color{red}{\eta}\) using weighted average form: \(\hat{f}(\text{x})=\sum_{i=1}^ny_i\color{blue}{W_{n,i}(x)}\).
In balanced \(M\)-class classification with Accuracy score, \(g^*(\text{x})=\arg\max_{1\leq k\leq M}\color{blue}{\mathbb{P}(Y=k|X=\text{x})}\) is the best classifier.
We will now look at three different models that attempt to estimate regression function \(\color{red}{\eta}\) using different form of weights \(\color{blue}{W_{n,i}(\text{x})}\).
\(K\)-Nearest Neighbors (\(K\)-NN)
Setting
Given iid observations: \(\{(\text{x}_1,y_1),\dots, (\text{x}_n,y_n)\}\subset \mathbb{R}^d\times{\cal Y}\).
If \(D\) is a distance on \(\mathbb{R}^d\) (e.g. Euclidean distance), the \(k\)-th nearest neighbor\(\color{red}{\text{x}_{(k)}}\) of \(\text{x}\in\mathbb{R}^d\) is defined by
Let \(y_{(1)},\dots,y_{(n)}\) be the target of \(\text{x}_{(1)},\dots,\text{x}_{(n)}\) respectively.
If \(K\geq 1\), then \(K\)-NN predicts the target of an input \(\text{x}\) by
Regression:\[\begin{align*}\hat{y}&=\frac{1}{K}\sum_{k=1}^Ky_{(k)}\qquad\quad \color{gray}{(\color{blue}{W_{n,i}(\text{x})}=?)}\\
&=\text{Average $y_{(k)}$ among the $K$ neighbors}.\end{align*}\]
Classification:\[\begin{align*}\hat{y}&=\arg\max_{1\leq m\leq M}\frac{1}{K}\sum_{k=1}^K\mathbb{1}_{\{y^{(k)}=m\}}\\
&=\text{Majority class among the $K$ neighbors.}\end{align*}\]
\(K\)-Nearest Neighbors (\(K\)-NN)
Example
Regression:\[\begin{align*}\hat{y}&=\frac{1}{K}\sum_{k=1}^Ky_{(k)}\qquad\quad \color{gray}{(\color{blue}{W_{n,i}(\text{x})}=?)}\\
&=\text{Average $y_{(k)}$ among the $K$ neighbors}.\end{align*}\]
Classification:\[\begin{align*}\hat{y}&=\arg\max_{1\leq m\leq M}\frac{1}{K}\sum_{k=1}^K\mathbb{1}_{\{y^{(k)}=m\}}\\
&=\text{Majority class among the $K$ neighbors.}\end{align*}\]
\(K\)-Nearest Neighbors (\(K\)-NN)
In action
Let’s work with our Heart Disease Dataset (shpe: \(1025\times 14\)) and choose \(K=5\).
\(K\)-NN is a distance-based method, it’s essential to
Scale the inputs
Watch out for outliers/missing values
Encode categorical inputs
Watch out for the effect of imbalanced class…
Code
import numpy as npimport pandas as pddata = pd.read_csv(path +"/heart.csv")quan_vars = ['age','trestbps','chol','thalach','oldpeak']qual_vars = ['sex','cp','fbs','restecg','exang','slope','ca','thal','target']# Convert to correct typesfor i in quan_vars: data[i] = data[i].astype('float')for i in qual_vars: data[i] = data[i].astype('category')# Train test splitfrom sklearn.model_selection import train_test_splitX, y = data.iloc[:,:-1], data.iloc[:,-1]X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)from sklearn.preprocessing import MinMaxScaler, StandardScalerscaler = MinMaxScaler()# OnehotEncoding and ScalingX_train_cat = pd.get_dummies(X_train.select_dtypes(include="category"), drop_first=True)X_train_encoded = scaler.fit_transform(np.column_stack([X_train.select_dtypes(include="number").to_numpy(), X_train_cat]))X_test_cat = pd.get_dummies(X_test.select_dtypes(include="category"), drop_first=True)X_test_encoded = scaler.transform(np.column_stack([X_test.select_dtypes(include="number").to_numpy(), X_test_cat]))# KNNfrom sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors=5)knn = knn.fit(X_train_encoded, y_train)y_pred = knn.predict(X_test_encoded)from sklearn.metrics import roc_auc_score, accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, ConfusionMatrixDisplaytest_perf = pd.DataFrame( data={'Accuracy': accuracy_score(y_test, y_pred),'Precision': precision_score(y_test, y_pred),'Recall': recall_score(y_test, y_pred),'F1-score': f1_score(y_test, y_pred),'AUC': roc_auc_score(y_test, y_pred)}, columns=["Accuracy", "Precision", "Recall", "F1-score", "AUC"], index=["5NN"])test_perf
Accuracy
Precision
Recall
F1-score
AUC
5NN
0.868293
0.861111
0.885714
0.873239
0.867857
Q3: Can we do better?
A3: Yes! \(K=5\) is arbitrary. We should fine-tune it!
\(K\)-Nearest Neighbors (\(K\)-NN)
Influence of \(K\)
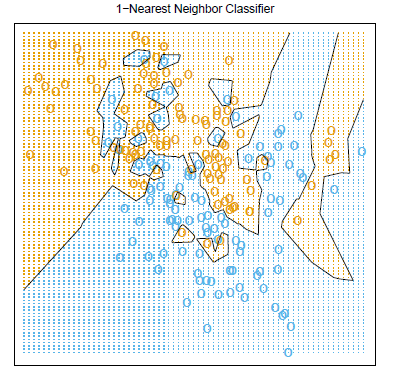
Too small \(K\Leftrightarrow\) too flexible \(\Leftrightarrow\) high variance \(\Leftrightarrow\) Overfitting.
\(K\)-Nearest Neighbors (\(K\)-NN)
Fine-tuning \(K\): Cross-validation
There are many way to perform Cross-validation in python.
Let’s use GridSearchCV from sklearn.model_selection module.
Curse of dimensionality refers to various challenges and phenomena that arise when working with high-dimensional data.
The main challenge for \(K\)-NN is that distances or closeness lose its meaning in high-dimensional spaces.
In this scenario, data points tend to be equally distant from one another.
Example: Simulate \(\text{x}_1,\dots,\text{x}_n\sim{\cal U}[-5,5]^d\) with \(d=1,10,100,500,1000, 5000, 10000, 50000\).
For each dimension \(d\), we compute: \[r(d)=\frac{\max_{i\neq j}D(\text{x}_i,\text{x}_j)}{\min_{i\neq j}D(\text{x}_i,\text{x}_j)}.\]
Obtain the following graph 👉
Code
N =10Ds = np.zeros(shape=(N*(N-1)//2, 8))j =0for d in [1,10,100, 500, 1000, 5000, 10000, 50000]: Xd = np.random.uniform(-5,5,size=(N,d)) i =0for s inrange(1, N):for k inrange(s): Ds[i,j] = np.linalg.norm(Xd[s,:] - Xd[k,:]) i +=1 j +=1import plotly.express as pxdf_dist = pd.DataFrame({'Ratio': np.round(Ds.max(axis=0)/Ds.min(axis=0), 2), 'Dim': ['1','10','100', '500', '1000', '5000', '10000', '50000']})fig4 = px.line(df_dist, x='Dim', y="Ratio", text="Ratio")fig4.update_layout( width=400, height=450, title="Max-min distance ratio at various dimension")fig4.update_xaxes(title='Dimension')fig4.update_yaxes(title='Max-Min Distance Ratio')fig4.update_traces(textposition="top right")fig4.show()
\(K\)-Nearest Neighbors (\(K\)-NN)
Summary
\(K\)-NN is a nonparametric model with weights: \(\color{blue}{W_{n,i}(\text{x})=\frac{\mathbb{1}_{\{\text{x}_i\in{\cal N}_{\text{x}}\}}}{K}}\), where \({\cal N}_{\text{x}}=\{\text{x}_{(1)},\dots,\text{x}_{(K)}\}\) the set of the first \(K\)-nearest neighbors of \(\text{x}\).
Data preprocessing is essential: scaling, encoding, outliers…
The key parameter \(K\) can be tuned using cross-validation technique.
\(K\)-NN may not be suitable in high-dimensional cases due to Curse of dimensionality. However, we can try:
In \(K\)-NN, “neighbors” are defined by the distance \(D\) (\(K\) points within the ball centered at the query point).
In CART, “neighbors” are defined by rectangular regions within inputs space.
Decision Trees
CART: Classification And Regression Trees
Building a CART \(\Leftrightarrow\) recursively split input space into smaller regions.
Rectangular regions \(\Rightarrow\) defining neighbors \(\Rightarrow\) prediction.
Start at root node where all points are in the same region (without split).
At each step, each region is split on feature \(X_j\) at threshold \(a\in\mathbb{R}\) such that the two subregions \(R_1=\{x\in\mathbb{R}^d: X_j\leq a\}\) and \(R_2=\{x\in\mathbb{R}^d: X_j> a\}\) are as pure as possible.
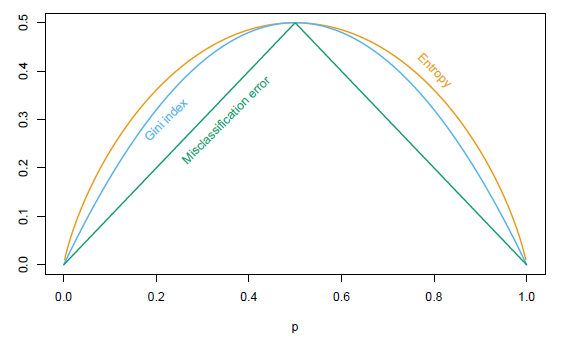
Entropy: \(-\sum_{k}\hat{p}_{k}\log(\hat{p}_{k})\) where \(\hat{p}_{k}=\frac{\sum_{i\in R}\mathbb{1}_{\{y_i=k\}}}{|R|}\) on region any \(R\).
Decision Trees
CART: Classification And Regression Trees
Building a CART \(\Leftrightarrow\) recursively split input space into smaller regions.
Rectangular regions \(\Rightarrow\) defining neighbors \(\Rightarrow\) prediction.
Start at root node where all points are in the same region (without split).
At each step, each region is split on feature \(X_j\) at threshold \(a\in\mathbb{R}\) such that the two subregions \(R_1=\{x\in\mathbb{R}^d: X_j\leq a\}\) and \(R_2=\{x\in\mathbb{R}^d: X_j> a\}\) are as pure as possible.
CART is a nonparametric model with weights: \(\color{blue}{W_{n,i}(\text{x})=\frac{\mathbb{1}_{\{\text{x}_i\in R_{\text{x}}\}}}{|R_{\text{x}}|}}\), where \(R_{\text{x}}\) the is the leave node containing \(\text{x}\).
They are not sensitive to scaling.
The key parameters includes depth, minimum leave size, impurity measures, number of splits, maximum features considered at each split… which can be tuned using cross-validation technique.
It is efficient in high-dimensional case as it handle features individually.
It can handle categorical data as well.
Just ike \(K\)-NN with small \(K\), deep trees are high-variance methods.
They should be pruned.
Kernel Smoothing Methods
Smoother weights
This is inspired by density estimation.
It aims at directly estimating \(\eta(x)=\mathbb{E}(Y|X=x)\) for regression or \(\mathbb{P}(Y=k|X=x)\) in classifications.
Regression: \[\hat{y}=\sum_{i=1}^ny_i\color{blue}{W_{n,i}(\text{x})},\] where \(\color{blue}{W_{n,i}(\text{x})}=\frac{K_h(\|\text{x}_i-\text{x}\|)}{\sum_{j=1}^nK_h(\|\text{x}_j-\text{x}\|)}\) with \(K_h(t)=K(t/h)\) for some moothing parameter \(h>0\).
Kernel smoother is a nonparametric model that assigns weight to each points using some kernel function \(K\), i.e., \[W_{n,i}(\text{x})=\frac{K_h(\|\text{x}_i-\text{x}\|)}{\sum_{j=1}^nK_h(\|\text{x}_j-\text{x}\|)}.\]
Training a Kernel Smoother is equivalent to tuning the smoothing parameter \(h>0\) using, for example, cross validation error.
Preprocessing is essential: scaling, encoding, transformation,…
Just like in \(K\)-NN, it might not work well in high-dimensional case but can be improved using the same methods.