\(k\)-NN is a nonparametric model that predicts any new data point \(\color{blue}{\text{x}}\) based on
Identifying input data \(\color{red}{\text{x}_{(i)}}\approx\color{blue}{\text{x}}\),
Prediction is based on the label \(\color{red}{y_{(i)}}\) of those neighbors.
Regression:\[\begin{align*}\color{blue}{\hat{y}}&=\frac{1}{k}\sum_{j=1}^k\color{red}{y_{(i)}}\\
&=\text{Average $\color{red}{y_{(i)}}$ among the $k$ neighbors}.\end{align*}\]
Classification with \(M\) classes:\[\begin{align*}\color{blue}{\hat{y}}&=\arg\max_{1\leq m\leq M}\frac{1}{k}\sum_{j=1}^k\mathbb{1}_{\{\color{red}{y_{(i)}}=m\}}\\
&=\text{Majority group among the $k$ neighbors.}\end{align*}\]
Motivation & Introduction
Introduction
\(k\)-NN defines Neighbors based on the Euclidean distance between two points.
The main leading question to the development of Decision Tree methods is
Is there other way to define Neighbor?
x1
x2
y
-0.752759
2.704286
1
1.935603
-0.838856
0
-0.546282
-1.960234
0
0.952162
-2.022393
0
-0.955179
2.584544
1
-2.458261
2.011815
1
2.449595
-1.562629
0
1.065386
-2.900473
0
-0.793301
0.793835
1
2.015881
1.175845
0
-0.016509
-1.194730
0
🌳 Decision Trees
🌳 Decision Trees (\(k\)-NN)
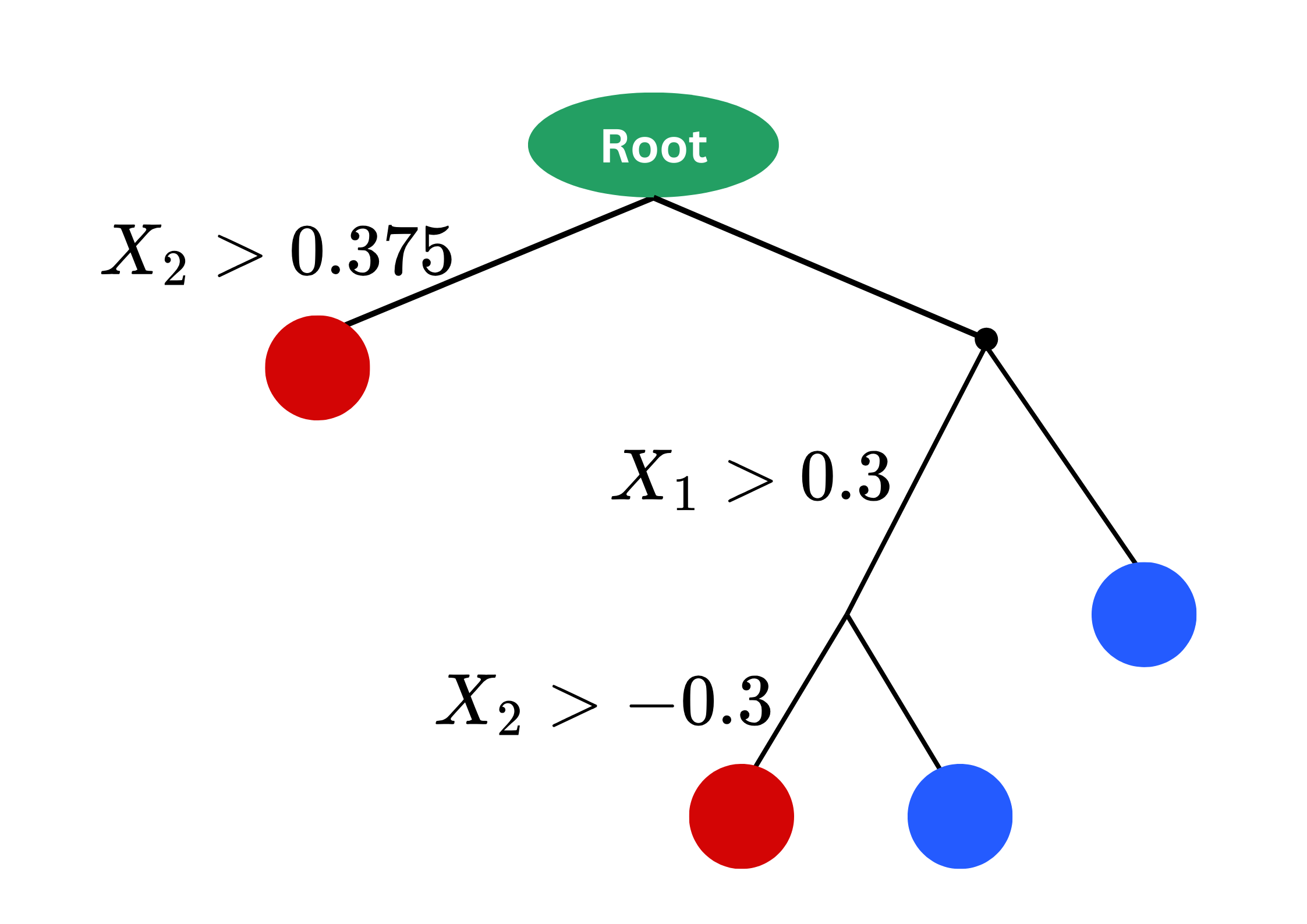
CART: Classification And Regression Trees
In CART, “neighbors” are defined by rectangular regions within inputs space.
Neighbors in \(k\)-NN are based on straight distance.