Exploratory Data Analysis & Unsuperivsed Learning Course: PHAUK Sokkey, PhD TP: HAS Sothea, PhD
Objective: In this lab, we’ll dive into the fascinating world of Gaussian Mixture Models (GMMs) and the Expectation-Maximization (EM) algorithm, both of which are fundamental concepts of unsupervised machine learning. GMMs can be viewed from various angles, such as density estimation and soft clustering. We’ll explore both perspectives and apply it to image segmentation, laying the groundwork for a broader understanding of generative models.
The Jupyter Notebook for this TP can be downloaded here: TP5-GMM_EM.
1. Gaussian Mixture Models
A. Perform GMM using GaussianMixture from sklearn.mixture on Iris dataset using n_components=5.
Read this documentation and answer the followign questions:
As the dataset is of dimension \(4\), we borrow a tool from next chapter PCA for visualizing this centers.
from sklearn.decomposition import PCA# PCA with 3 componentspc = PCA(n_components=3)X_proj = pc.fit_transform(X)# Project the meanscentroid_proj = pc.transform(gmm.means_)import plotly.io as piopio.renderers.default ='notebook'import plotly.graph_objects as gofig = go.Figure(go.Scatter3d(x=X_proj[:,0], y=X_proj[:,1], z=X_proj[:,2], name="Projected iris data", mode ="markers", marker =dict(size=6, color=y_pred)))fig.update_layout(title="Projection of Iris data onto the first 3 PCs", width=700, height=500)# Add meansfig.add_trace( go.Scatter3d(x=centroid_proj[:,0], y=centroid_proj[:,1], name="Centroids obtained from GMM", z=centroid_proj[:,2], mode="markers", marker=dict(size=10, color="black")))fig.show()
What does the score() do in this module?
Mixture models (MMs) assume that the density \(f_X\) of the observation \(x_1,...,x_n\in\mathbb{R}^d\) consists of mutiple components or clusters where the number of components is denoted by \(K>1\), i.e., \[f_X(x_i)=\sum_{k=1}^K\pi_kf_k(x_i;\theta_k)\text{ for all }i\in\{1,2,\dots,n\},\] where
\(\pi_k\) is the proportion of data points in component \(k\)
\(f_k(x;\theta_k)\) is the density of data \(x\) in the component \(k\)th with corresponding parameter \(\theta_k\) for \(k\in\{1,2,\dots,K\}\).
If we assume that within each cluster, the observation is normally distributed, i.e., \(f_k(x;\theta_k)={\cal N}(x;\theta_k)\) with \(\theta_k=(\mu_k,\Sigma_k)\), then we obtain Gaussian Mixture Model (GMM). In this case, the likelihood of the observation is written as
At this point, our objective is to search for values of \((\theta_1,\dots,\theta_K)\) maximizing the above likelihood function or equivalently, maximizing the following log-likelihood function:
Unfortunately, the form of such a log-likelihood is not maximizable in general. We therefore need a numerical method for solving this maximization problem. Back to our question, given a number of cluster \(K=5\) and all values of paramters \((\theta_1,\theta_2,\dots,\theta_5)\), the score function is the average log-likelihood of all the observations evaluated at these values of \(K=5\) and all the approximated parameters:
\[\text{Score}=\frac{1}{n}\sum_{i=1}^n\log\left[\sum_{k=1}^K\pi_k{\cal N}(x_i;\theta_k)\right]=\frac{{\cal L}(\theta_1,\theta_2,\dots,\theta_K)}{n}.\] Simply put, if the number of components with its approximated parameters fit well with the observed data: \(x_1,\dots,x_n\), this \(\text{Score}\) should be large.
Remark: the score often increases with the number of components as Gaussian density increases when data concentrate close to the center (which is likely to be true when there are many clusters).
Compute this score, AIC and BIC of the trained GMM.
B. Perform GMM on Iris data but this time using n_components = 1,2,...,10.
Compute the score, AIC and BIC at each number of component.
What is the optimal number of component.
import plotly.io as piopio.renderers.default ='notebook'score = []aic = []bic = []for k inrange(2,11): gmm = GaussianMixture(n_components=k, covariance_type='full') gmm.fit(X) score.append(gmm.score(X)) aic.append(gmm.aic(X)) bic.append(gmm.bic(X))from plotly.subplots import make_subplotsfig_score = make_subplots( rows=1, cols=3, subplot_titles=("Score vs No. clusters", "AIC vs No. clusters", "BIC vs No. clusters"))fig_score.add_trace(go.Scatter(x=list(range(2,11)), name="Score", y = score), row=1, col=1)fig_score.add_trace(go.Scatter(x=list(range(2,11)), name="AIC", y = aic), row=1, col=2)fig_score.add_trace(go.Scatter(x=list(range(2,11)), name="BIC", y = bic), row=1, col=3)fig_score.update_layout(width=780, height=400)
The optimal number of clsuters based on AIC is 8 while the optimal number of cluster is 2 based on BIC.
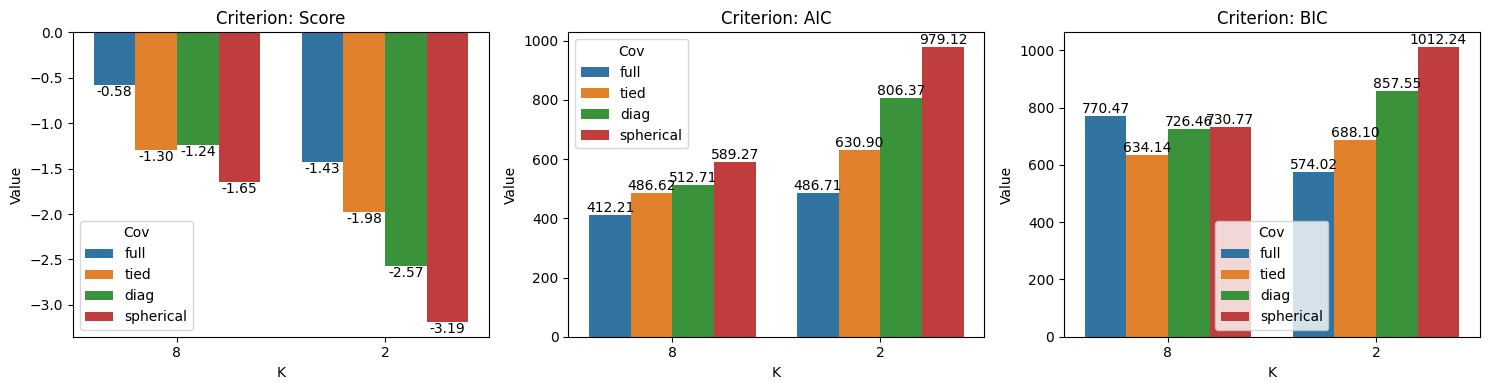
C. With the optimal number of components from question B, perform GMM on Iris data using different options of covariance_type from the list [‘full’, ‘tied’, ‘diag’, ‘spherical’]. In each case, compute the score associated to each variance type. Comment.
import seaborn as snsimport matplotlib.pyplot as plt_, axs = plt.subplots(1, 3, figsize=(15, 4))i =0for v in ['Score', 'AIC', 'BIC']: sns.barplot(data=df[df.Criteria == v], x="K", y="Value", hue="Cov", ax=axs[i]) axs[i].set_title(f"Criterion: {v}") axs[i].bar_label(axs[i].containers[0], fmt="%.2f") axs[i].bar_label(axs[i].containers[1], fmt="%.2f") axs[i].bar_label(axs[i].containers[2], fmt="%.2f") axs[i].bar_label(axs[i].containers[3], fmt="%.2f") i +=1plt.tight_layout()plt.show()
In terms of the Score (likelihood fit) and AIC, 8 components with a full covariance matrix fit best on the data, as indicated by the highest score and lowest AIC.
However, BIC suggests that 2 components with a full covariance matrix better fit the data.
D. Repeat question B and C on a simulated data from the previous TP4. How is GMM’s result compared to Kmeans or Hierarchical clustering?
Left as a practical exercise.
2. EM Algorithm
The EM algorithm is used to estimate the parameters of the GMM, ensuring that the model fits the data as closely as possible by iteratively refining the parameters. It leverages the concept of latent variables (responsibilities) to handle the fact that the actual class labels for the data points are unknown.
This iterative optimization makes GMMs a powerful tool for tasks like clustering and density estimation.
A. Recall the process of EM algorithm in GMM of \(K\) components.
Here, only one component of \(z_i\) that is not zero and if \(z_{ik}=1\) or \(x_i\) belongs to component \(k\), then \(x_i\) is distributed according to \({\cal N}(\mu_k,\sigma_k)\). For any observation \(x_i\) and any component \(k\in\{1,\dots,K\}\).
This implies that \(\mathbb{E}[z_{ik}]=p(z_{ik}=1|x_i)=\frac{\pi_k{\cal N}(x_i;\mu_k,\sigma_k^2)}{\sum_{j=1}^K\pi_j{\cal N}(x_i;\mu_j,\sigma_j^2)}=\gamma_{ik}\) because \(z_{ik}|x_i\sim{\cal B}(\gamma_{ik})\) (given \(x_i\) value, \(z_{ik}\) is a Bernoulli random variable of parameter \(\gamma_{ik}\)). This \(\gamma_{ik}\) is called responsibility, and it is the probability of a given observation \(x_i\) being a member of component \(k\).
We can now introduce “complete data log-likelihood” for parameter \(\theta_k=(\pi_k,\mu_k,\sigma_k^2)\) at the complete data \((x_1,\dots,x_n,z_1,\dots,z_n)\):
\(\theta=(\pi_1,\dots,\pi_K,\mu_1,\dots,\mu_K,\sigma_1,\dots,\sigma_K)\) are the parameters explicitly defined in \(Q\)
\(\theta_{\text{old}}=(\pi_1',\dots,\pi_K',\mu_1',\dots,\mu_K',\sigma_1',\dots,\sigma_K')\) are the parameters used for evaluating \((\gamma_{ik})\).
One may ask: why maximizing this expectation of the complete data log-likelihood w.r.t the parameters \(\theta_1,\dots,\theta_K\) also maximizing the observed log-likeliood?
Maximizing this expectation works because it is indeed the lower bound of the objective “log observed data likelihood”:
M-step: Compute the maximizer: \(\theta^{\text{new}}=\arg\max_{\theta}Q(\theta, \theta^{\text{old}})\). For GMM, we have explicit formula for the parameters as follows:
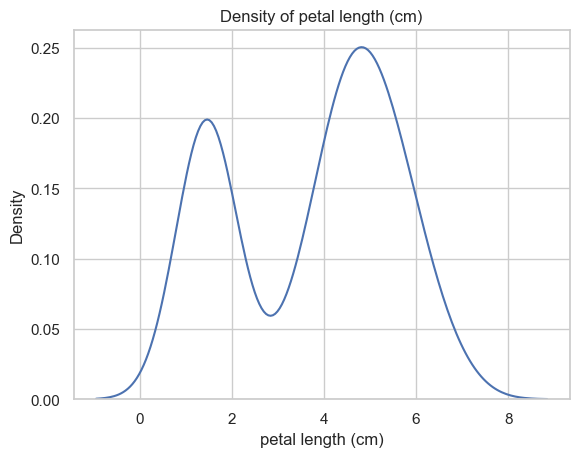
Plot the density of the third column of Iris dataset. From this density, what is the number of components?
sns.set(style="whitegrid")ax = sns.kdeplot(X[:,2])ax.set_title(f"Density of {Iris.feature_names[2]}")ax.set_xlabel(f"{Iris.feature_names[2]}")plt.show()
This density suggests that there are two distinct components of petal length of Iris flowers within Iris dataset.
Write a function EM1d(x, K=3, max_iter = 100) that takes 1D data array x, number of components K and the maximum itermation of EM algorithm max_iter. The function should return: responsibility matrix\(\Gamma\), center and variance of all \(K\) components.
Code
import numpy as np from scipy.stats import norm # Mixture densitydef densityMixture(x, mu, sigma, prop): n =len(x) K =len(prop) d = np.zeros(n) for i inrange(n): for k inrange(K): d[i] += prop[k] * norm.pdf(x[i], mu[k], sigma[k]) return d# Log likelihood functiondef logLikehood(x, mu, sigma, prop): result = densityMixture(x, mu, sigma, prop) return np.sum(np.log(densityMixture(x, mu, sigma, prop)))# Compute Responsibilities in E-stepdef responsibilities(x, mu, sigma, prop): n =len(x) K =len(prop) gamma = np.zeros((n, K)) for i inrange(n): for k inrange(K): gamma[i, k] = prop[k] * norm.pdf(x[i], mu[k], sigma[k]) gamma = gamma / gamma.sum(axis=1, keepdims=True) return gamma# Compute Parameters in M-stepdef params(x, gamma): n = gamma.shape[0] K = gamma.shape[1] prop = np.sum(gamma, axis=0) / n mu = (gamma.T @ x) / np.sum(gamma, axis=0) sigma = np.sqrt(np.diag((gamma.T @ (np.tile(x, (K, 1)).T - np.tile(mu, (n, 1)))**2) / np.sum(gamma, axis=0))) return {"prop": prop, "mu": mu, "sigma": sigma}from sklearn.cluster import KMeans# EM algorithm for 1D datadef EM1d(x, K, max_iter =100): n =len(x) # Initialization kmeans = KMeans(n_clusters=K).fit(x.reshape(-1, 1)) cl = kmeans.labels_ gamma = np.zeros((n, K)) gamma[np.arange(n), cl] =1# M step at Iteration 0 old_param = params(x, gamma) loglik = [logLikehood(x, old_param['mu'], old_param['sigma'], old_param['prop'])] # E step at Iteration 1 gamma = responsibilities(x, old_param['mu'], old_param['sigma'], old_param['prop']) # M step at Iteration 1 param = params(x, gamma) loglik.append(logLikehood(x, param['mu'], param['sigma'], param['prop'])) # Main loop for i inrange(max_iter):# E step gamma = responsibilities(x, param['mu'], param['sigma'], param['prop']) # M step param = params(x, gamma) loglik.append(logLikehood(x, param['mu'], param['sigma'], param['prop'])) return {"prop": param['prop'], "mu": param['mu'], "sigma": param['sigma'], "loglik": loglik, "gamma": gamma}
Apply your function to the third column of the iris data with \(K=2,...,10\).
import warnings warnings.filterwarnings('ignore')res = []for k inrange(2, 11): res.append(EM1d(X[:,2], K=k))
c:\Users\hasso\AppData\Local\Programs\Python\Python312\Lib\site-packages\scipy\stats\_distn_infrastructure.py:1983: RuntimeWarning:
divide by zero encountered in divide
c:\Users\hasso\AppData\Local\Programs\Python\Python312\Lib\site-packages\scipy\stats\_distn_infrastructure.py:1983: RuntimeWarning:
invalid value encountered in divide
c:\Users\hasso\AppData\Local\Programs\Python\Python312\Lib\site-packages\scipy\stats\_distn_infrastructure.py:1983: RuntimeWarning:
divide by zero encountered in divide
c:\Users\hasso\AppData\Local\Programs\Python\Python312\Lib\site-packages\scipy\stats\_distn_infrastructure.py:1983: RuntimeWarning:
invalid value encountered in divide
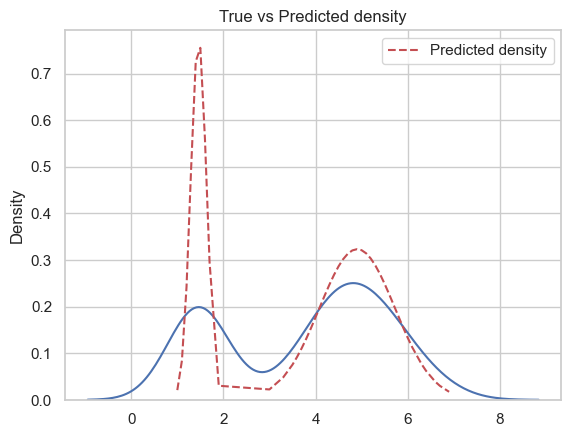
Compute score, AIC and BIC for each \(K\) (you may need to write your own function for that). What is the optimal number of components?
# AICdef AIC(param): prop, mu, sigma, gamma, llik = param['prop'], param['mu'], param['sigma'], param["gamma"], param["loglik"][-1] d =3*len(mu) -1return-2*llik +2*d# BICdef BIC(param): prop, mu, sigma, gamma, llik = param['prop'], param['mu'], param['sigma'], param["gamma"], param["loglik"][-1] d =3*len(mu) -1return-2*llik + d*np.log(gamma.shape[0])import plotly.io as piopio.renderers.default ='notebook'score = []aic = []bic = []for k inrange(9): score.append(res[k-2]["loglik"][-1]) aic.append(AIC(res[k])) bic.append(BIC(res[k]))from plotly.subplots import make_subplotsfig_score = make_subplots( rows=1, cols=3, subplot_titles=("Score vs No. clusters", "AIC vs No. clusters", "BIC vs No. clusters"))fig_score.add_trace(go.Scatter(x=list(range(2,11)), name="Score", y = score), row=1, col=1)fig_score.add_trace(go.Scatter(x=list(range(2,11)), name="AIC", y = aic), row=1, col=2)fig_score.add_trace(go.Scatter(x=list(range(2,11)), name="BIC", y = bic), row=1, col=3)fig_score.update_layout(width=780, height=400, title=f"Score, AIC and BIC of {Iris.feature_names[2]} vs no. clusters")
This result suggests that the optimal number of clusters is \(2\).
Load any image (not too large resolution or it can be an Mnist image from the previous TP).
from skimage import dataimage = data.astronaut()print(image.shape)plt.imshow(image)plt.axis('off')plt.show()
(512, 512, 3)
Reshape it into 1D array, then apply your EM1d function (or sklearn GMM function) on that 1D pixel array with your desired number of components.
Assign each pixel to a component and reshape the segmented image back into its original shape.
Display the original and segmented images side by side. Comment.
# Reduce resolution of the image for fast processingimage_gray = image[::5,::5,2]print(image_gray.shape)# Reshape imageimage1d = image_gray.reshape(-1)plt.imshow(image_gray, cmap="gray")plt.axis('off')plt.show()