
| label | text | label_num | |
|---|---|---|---|
| 1566 | ham | Subject: hpl nom for march 30 , 2001\r\n( see ... | 0 |
| 1988 | spam | Subject: online pharxmacy 80 % off all meds\r\... | 1 |
| 1235 | ham | Subject: re : nom / actual volume for april 17... | 0 |
🗺️ Content
Introduction & Motivation
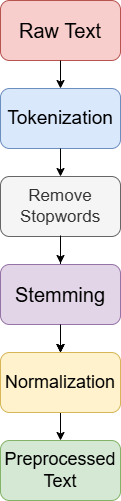
Text Preprocessing
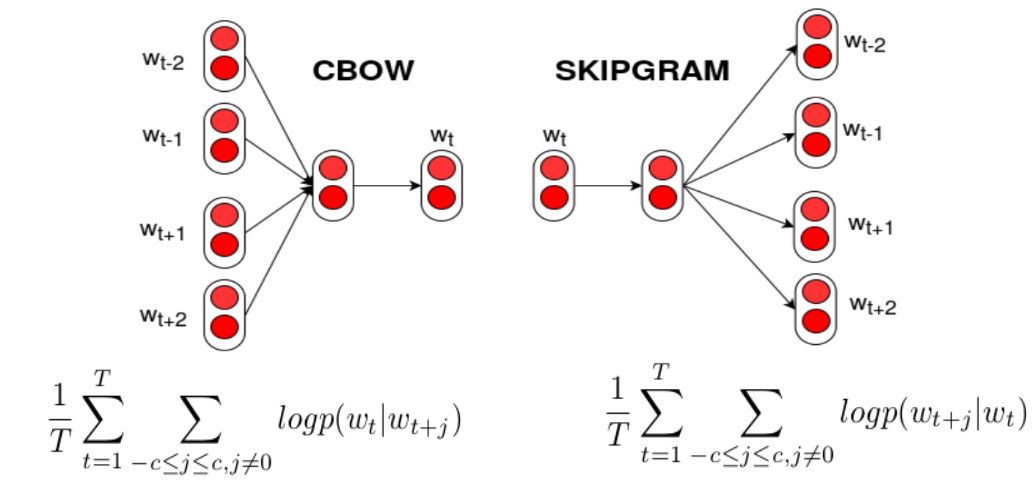
Text Transformation
Feature Selection
Data Mining/Pattern Recovery
Evaluation/Interpretation
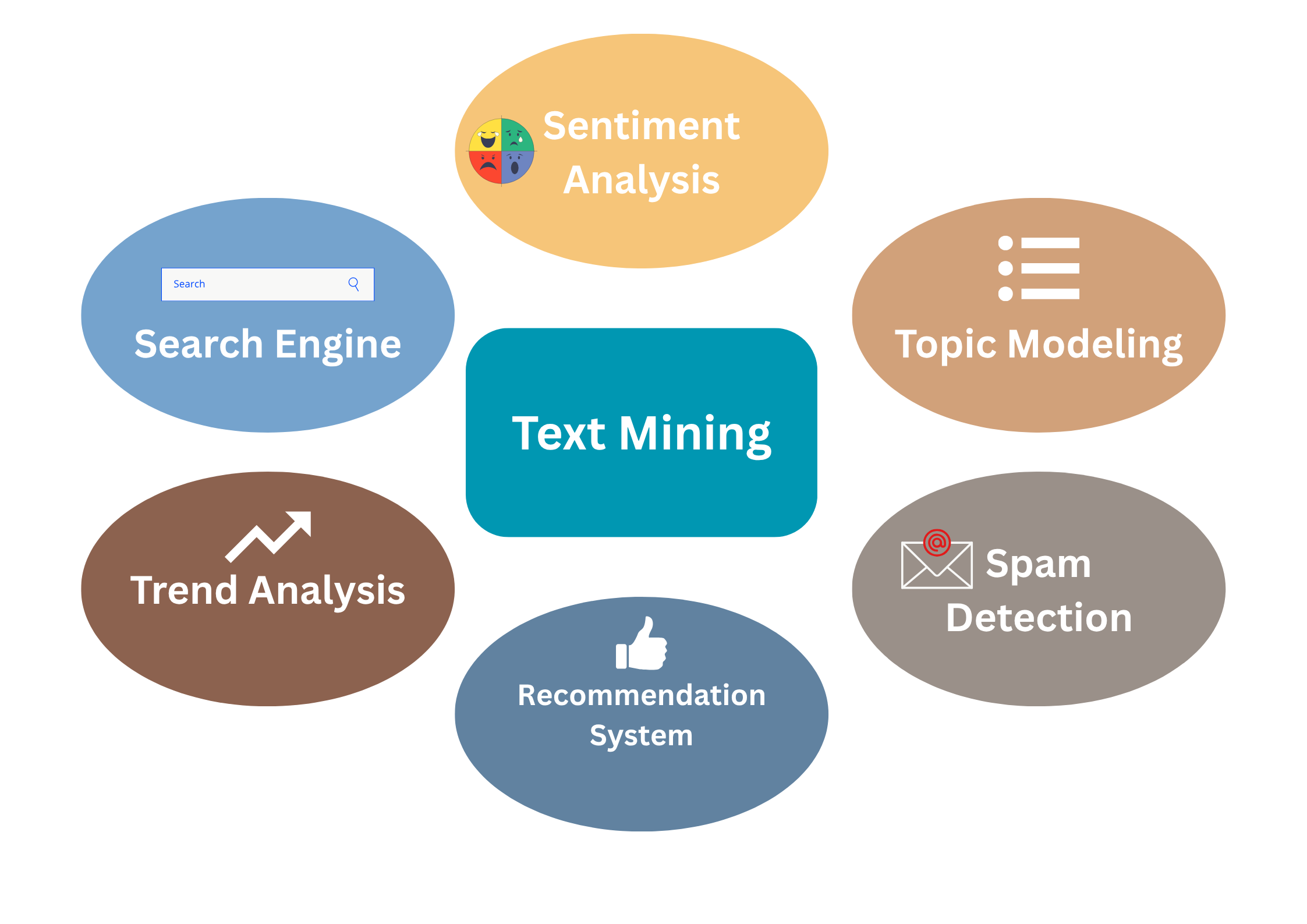
Applications