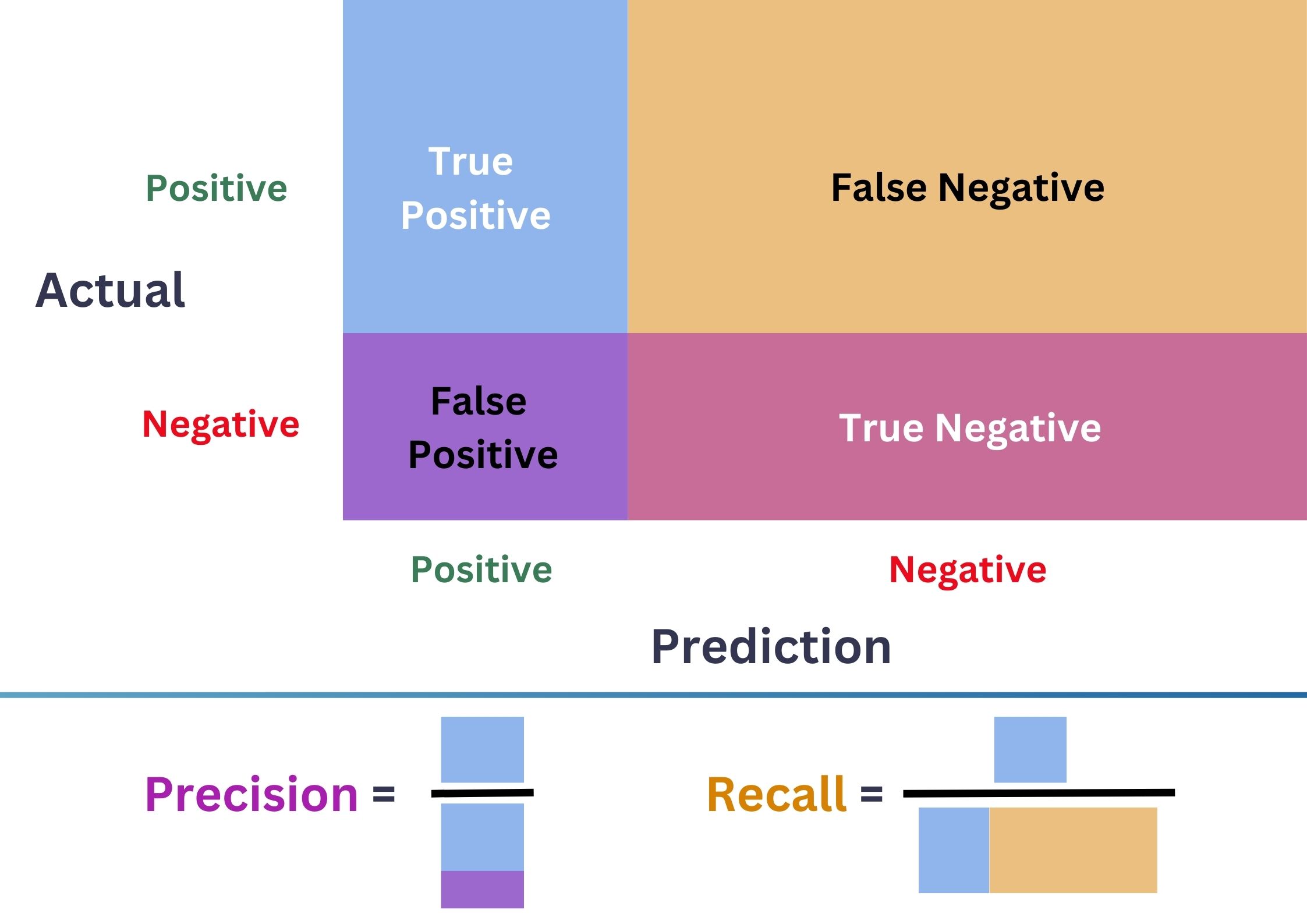
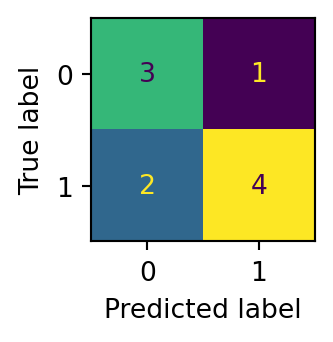
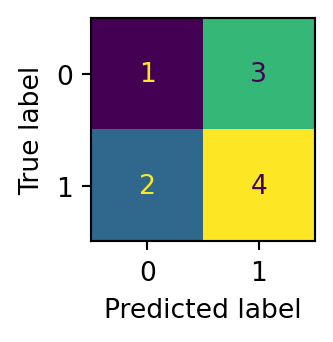
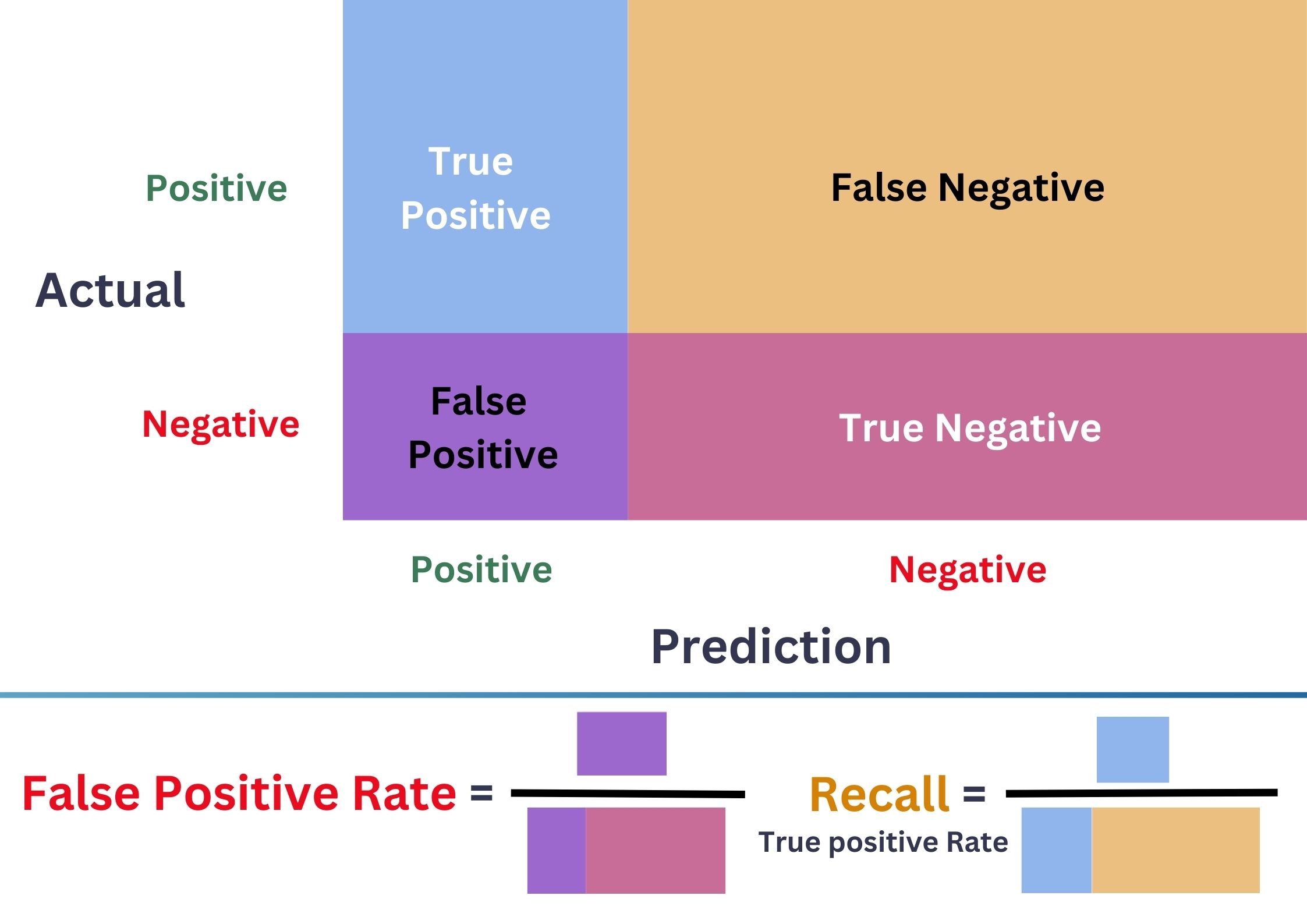
from sklearn.preprocessing import PolynomialFeatures
list_mod = []
degrees = [2,3,4,5,6,7,8,9,10,11,12,13,14,15]
for deg in degrees:
poly = PolynomialFeatures(degree=deg, include_bias=True)
X_poly_train = poly.fit_transform(X_train)
X_poly_test = poly.transform(X_test)
lg2 = LogisticRegression()
lg2 = lg2.fit(X_poly_train, y_train)
list_mod.append(lg2)
y_hat = lg2.predict(X_poly_test)
pred_prob = lg2.predict_proba(X_poly_test)[:,1]
if deg == 2:
perf_tab2 = pd.concat([perf_tab_cv.iloc[[0,-1],:], pd.DataFrame(
{key: metrics[key](y_test, y_hat) if key!="AUC" else metrics[key](y_test, pred_prob) for key in metrics.keys()},
index=['Poly2'])], axis=0
)
else:
perf_tab2 = pd.concat([perf_tab2, pd.DataFrame(
{key: metrics[key](y_test, y_hat) if key!="AUC" else metrics[key](y_test, pred_prob) for key in metrics.keys()},
index=[f'Poly{deg}'])], axis=0
)
perf_tab2