import pandas as pd # Import pandas packageimport seaborn as sns # Package for beautiful graphsimport plotly.express as pximport matplotlib.pyplot as plt # Graph management# path = "https://gist.githubusercontent.com/curran/4b59d1046d9e66f2787780ad51a1cd87/raw/9ec906b78a98cf300947a37b56cfe70d01183200/data.tsv" # The data can be found in this linkdf0 = pd.read_csv(path0 +"/faithful.csv" ) # Import it into Pythondf0.head(5) # Randomly select 4 points
eruptions
waiting
0
3.600
79
1
1.800
54
2
3.333
74
3
2.283
62
4
4.533
85
Code
fig0 = px.scatter(df0, x="waiting", y="eruptions", size_max=50) # Create scatterplotfig0.update_layout( title="Old Faithful data from Yellowstone National Park, US", width=500, height=380) # Titlefig0.show()
Two blocks: shorter wait & eruption, and the longer ones.
Marketing: finding groups of customers with similar behavior given a large database of customer data containing their properties and past buying records.
Biology: classification of plants and animals given their features.
Insurance: identifying groups of motor insurance policy holders with a high average claim cost; identifying frauds.
Bookshops: book ordering (recommendation).
City-planning: identifying groups of houses according to their type, value and geographical location.
Internet: document classification; clustering weblog data to discover groups of similar access patterns; topic modeling…
Introdution & Motivation
Clustering
Code
df0.head(2)
eruptions
waiting
0
3.6
79
1
1.8
54
Clustering aims at partitioning a set of points from some metric space in such a way that
Introdution & Motivation
Clustering
Code
df0.head(2)
eruptions
waiting
0
3.6
79
1
1.8
54
Clustering aims at partitioning a set of points from some metric space in such a way that
Points within the same group are close/similar, and
Introdution & Motivation
Clustering
Code
df0.head(2)
eruptions
waiting
0
3.6
79
1
1.8
54
Clustering aims at partitioning a set of points from some metric space in such a way that
Points within the same group are close/similar, and
Points from different groups are distant.
Introdution & Motivation
Clustering
Code
df0.head(2)
eruptions
waiting
0
3.6
79
1
1.8
54
Clustering aims at partitioning a set of points from some metric space in such a way that
Points within the same group are close/similar, and
Points from different groups are distant.
It belongs to the Unsupervised Learning branch of Machine Learning (ML).
Objective: group data into clusters based on their similarities.
Kmeans as a vector quantization
Kmeans as a vector quantization
Clustering as a compression problem
Given set of data \({\cal D}=\{\text{x}_1,\dots,\text{x}_n\}\subset\mathbb{R}^d\).
Compression: Represent \(\text{x}_i\) using a unique code-vector \(c_k\in{\cal C}=\{c_1,\dots,c_K\}\subset\mathbb{R}^d\) for some \(K\geq 1\).
If codebook\(\cal C=\{c_1,\dots,c_K\}\) is known, Voronoi partition associated with \(\cal C\) is defined by \[\color{green}{S_k}=\{\text{x}_i:\|\text{x}_i-\color{green}{c_k}\|\leq \|\text{x}_i-c_j\|, \forall j\neq k\}.\]
Kmeans as a vector quantization
Nearest Neighbor Condition
If codebook\({\cal C}=\{c_1,\dots,c_K\}\) is known, Voronoi partition associated with \(\cal C\) is defined by \[\color{green}{S_k}=\{\text{x}_i:\|\text{x}_i-\color{green}{c_k}\|\leq \|\text{x}_i-c_j\|, \forall j\neq k\}.\]
Given centroids \({\cal C}=\{c_1,\dots,c_K\}\), we can define groups by simply computing Voronoi partition.
Given a codebook\({\cal C}\), let \(q\) be any quantizer and \(\color{blue}{\hat{q}}\) be the quantizer that assigns any observation\(\text{x}_i\) to its closest code-vector (centroid of its Voronoi partition), i.e., \[\color{blue}{\hat{q}}(\text{x}_i)=\arg\min_{c_k\in{\cal C}}\|\text{x}_i-c_k\|^2\]
Then, one has \[\color{red}{\text{WSS}}(\color{blue}{\hat{q}})\leq \color{red}{\text{WSS}}(q).\]
Kmeans as a vector quantization
Centroid Condition
If codebook\({\cal C}=\{c_1,\dots,c_K\}\) is known, Voronoi partition associated with \(\cal C\) is defined by \[\color{green}{S_k}=\{\text{x}_i:\|\text{x}_i-\color{green}{c_k}\|\leq \|\text{x}_i-c_j\|, \forall j\neq k\}.\]
Given centroids \({\cal C}=\{c_1,\dots,c_K\}\), we can define groups by simply computing Voronoi partition.
Given a partition \({\cal S}=\{S_1,\dots,S_K\}\), let \(q\) be any quantizer and \(\color{blue}{\hat{q}}\) be the quantizer with Voronoi parition and codebook\(\hat{{\cal C}}=\{\hat{c}_k\}\) defined by \[\hat{c}_k=\frac{1}{|S_k|}\sum_{\text{x}_i\in S_k}\text{x}_i.\]
Then, one has \[\color{red}{\text{WSS}}(\color{blue}{\hat{q}})\leq \color{red}{\text{WSS}}(q).\]
Kmeans as a vector quantization
Summary of Lemma 1
Nearet Neighbor Condition: Given codebook \({\cal C}=\{c_k\}\), we know how to assign \(\text{x}_i\mapsto c_k\) optimally, therefore find the best Voronoi parition.
Centroid Condition: Given a partition \({\cal S}=\{S_k\}\), we know how to define an optimal codebook\({\cal C}=\{c_k\}\).
Q1: Based on these results, how would you design a clustering algorithm?
for i = 1,...,n: ….for k = 1,...,K:\[\text{Assign }\text{x}_i\to \color{green}{S_k}\text{ if }\|\text{x}_i-\color{green}{c_k}\|\leq \|\text{x}_i-c_j\|,\forall j\neq k.\]
Centroid Recomputation (CC): From \({\cal S}=\{S_k\}\) recompute new centroids:
for i = 1,...,n: ….for k = 1,...,K:\[\text{Assign }\text{x}_i\to \color{green}{S_k}\text{ if }\|\text{x}_i-\color{green}{c_k}\|\leq \|\text{x}_i-c_j\|,\forall j\neq k.\]
Centroid Recomputation (CC): From \({\cal S}=\{S_k\}\) recompute new centroids:
🔑 If \(\color{blue}{\text{x}_i}\) belongs to cluster \(k\)-th, we define
\(a(\color{blue}{i})=\frac{1}{|S_k|-1}\sum_{j\neq i}\|\text{x}_j-\color{blue}{\text{x}_i}\|^2\): the proximity between \(\color{blue}{\text{x}_i}\) and other members within the same cluster.
\(b(\color{blue}{i})=\min_{j\neq k}\frac{1}{|S_j|}\sum_{\text{x}\in S_j}\|\text{x}-\color{blue}{\text{x}_i}\|^2\): proximity between \(\color{blue}{\text{x}_i}\) and other members of the nearest cluster.
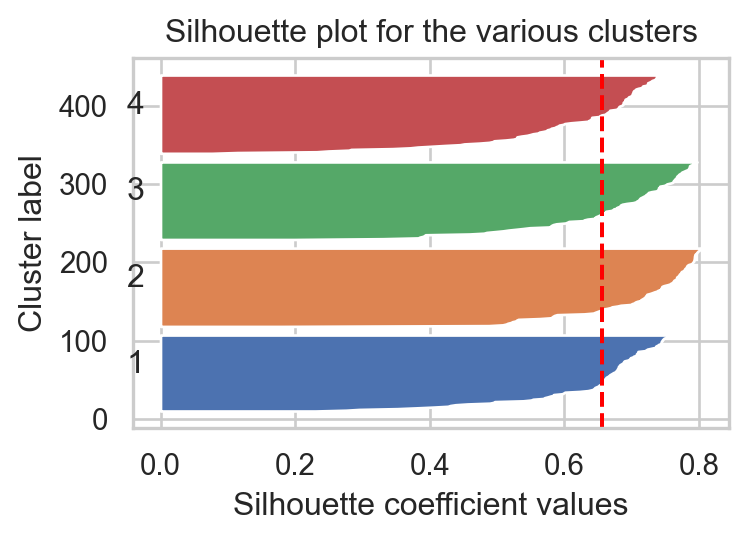
Silhouette value for any data point \(\color{blue}{\text{x}_i}\) is defined by: \[-1\leq s(\color{blue}{i})=\frac{b(\color{blue}{i})-a(\color{blue}{i})}{\max\{a(\color{blue}{i}),b(\color{blue}{i})\}}\leq 1.\]
\(s(\color{blue}{i})\approx 1\) indicates that the data point \(\color{blue}{\text{x}_i}\) is well-clustered within its cluster and distant from other groups.
\(s(\color{blue}{i})\approx -1\) indicates that the data point \(\color{blue}{\text{x}_i}\) is distant from other members of its cluster and should belong to the nearest group.
Silhouette Coefficient for a given \(K\) is \(\tilde{s}(K)=\sum_{i=1}^ns(i)/n.\)
Optimal number of cluster\(K^*=\arg\max_{K_\min\leq k\leq K_\max}\{\tilde{s}(k)\}.\)
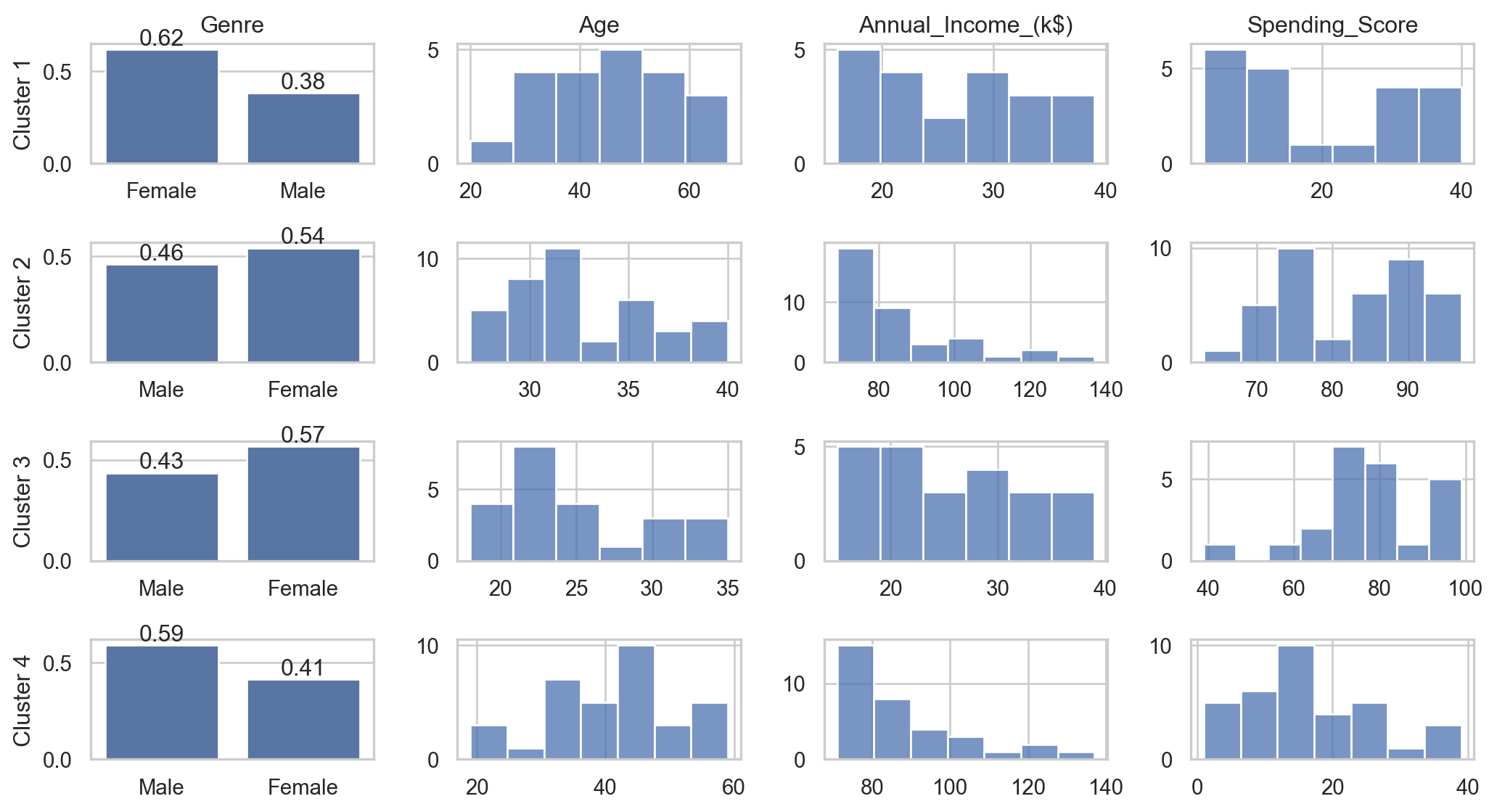
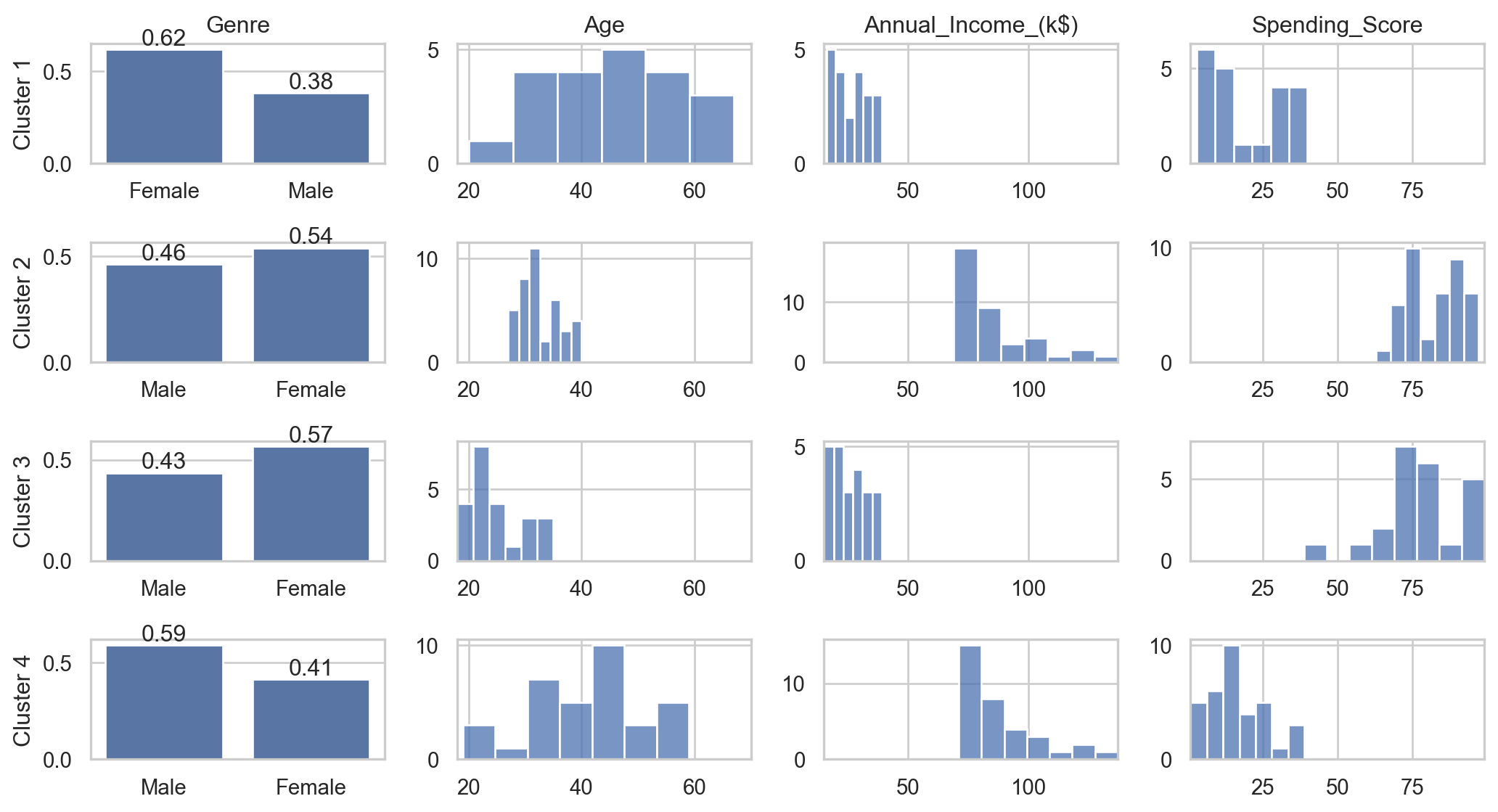
Clustering is a key technique in the unsupervised learning branch of machine learning.
It plays a crucial role in tasks involving the organization and segmentation of data based on their similarities.
It can be applied in various fields such as market segmentation, image processing, and anomaly detection.
There are numerous clustering algorithms available, each suited to different types of data and purposes, such as KMeans, Hierarchical Clustering, DBSCAN, and Spectral Clustering.
Interpreting clustering results can be challenging, but it is an essential step to ensure the validity and usefulness of the clusters identified.