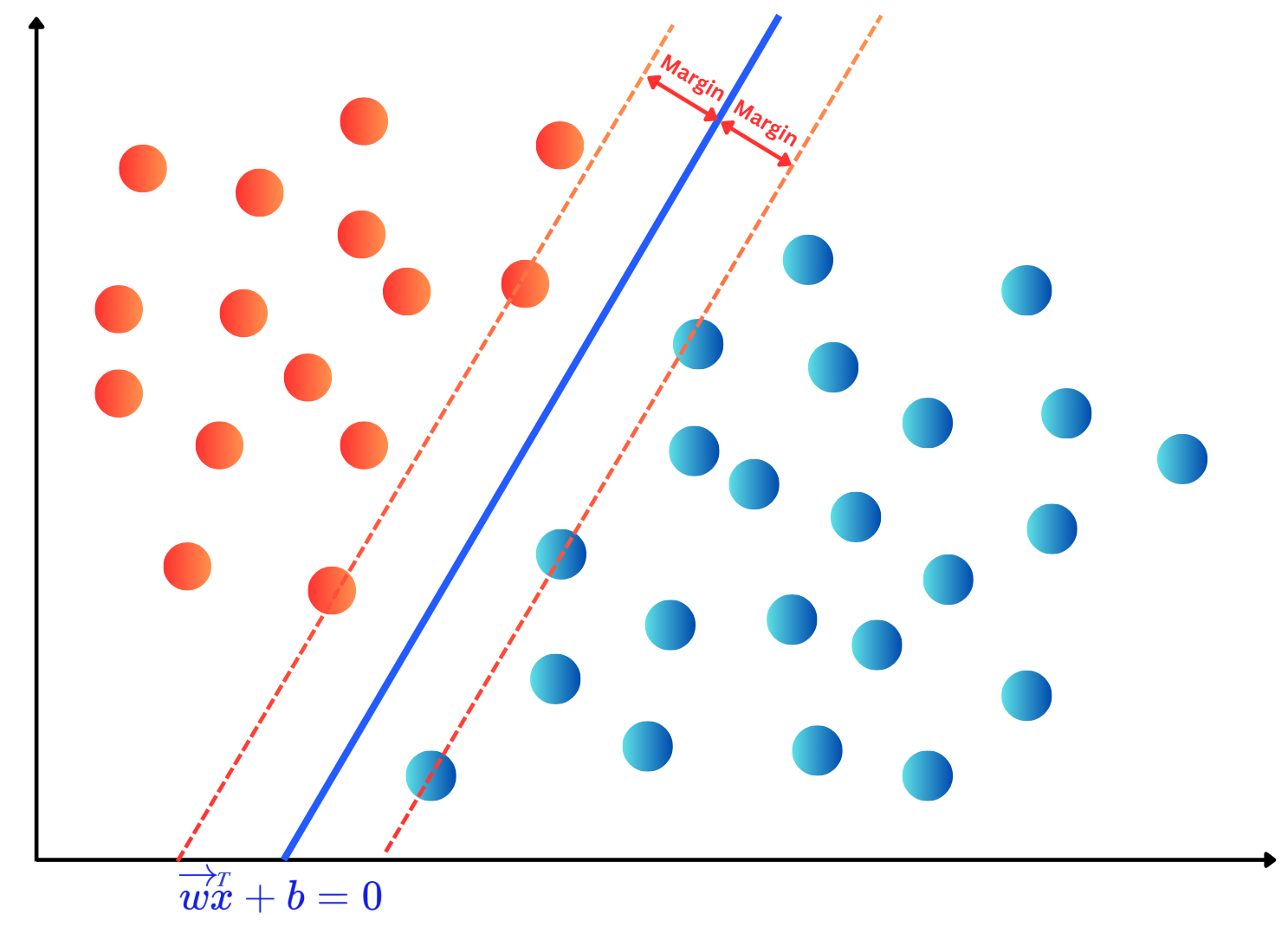
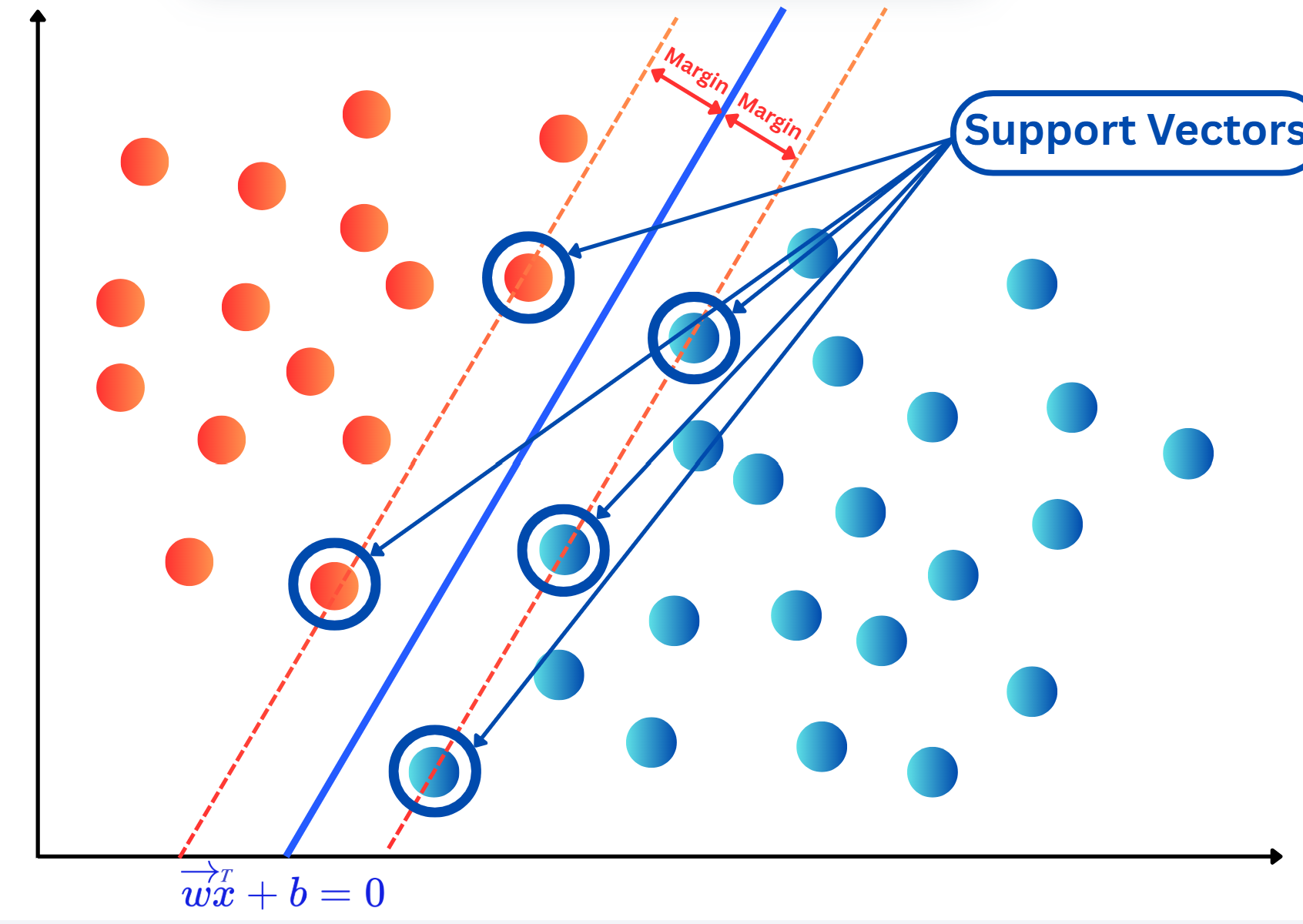
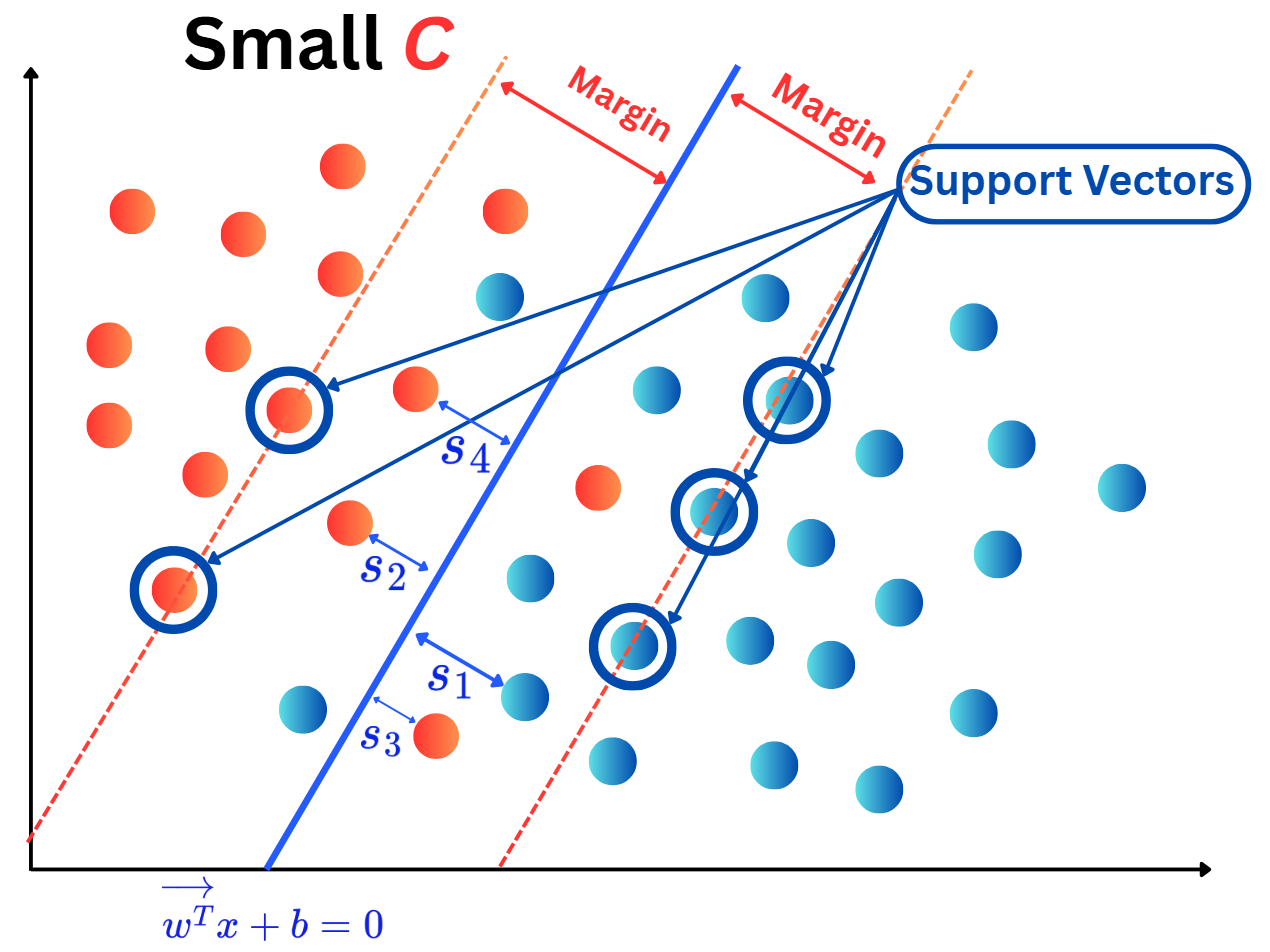
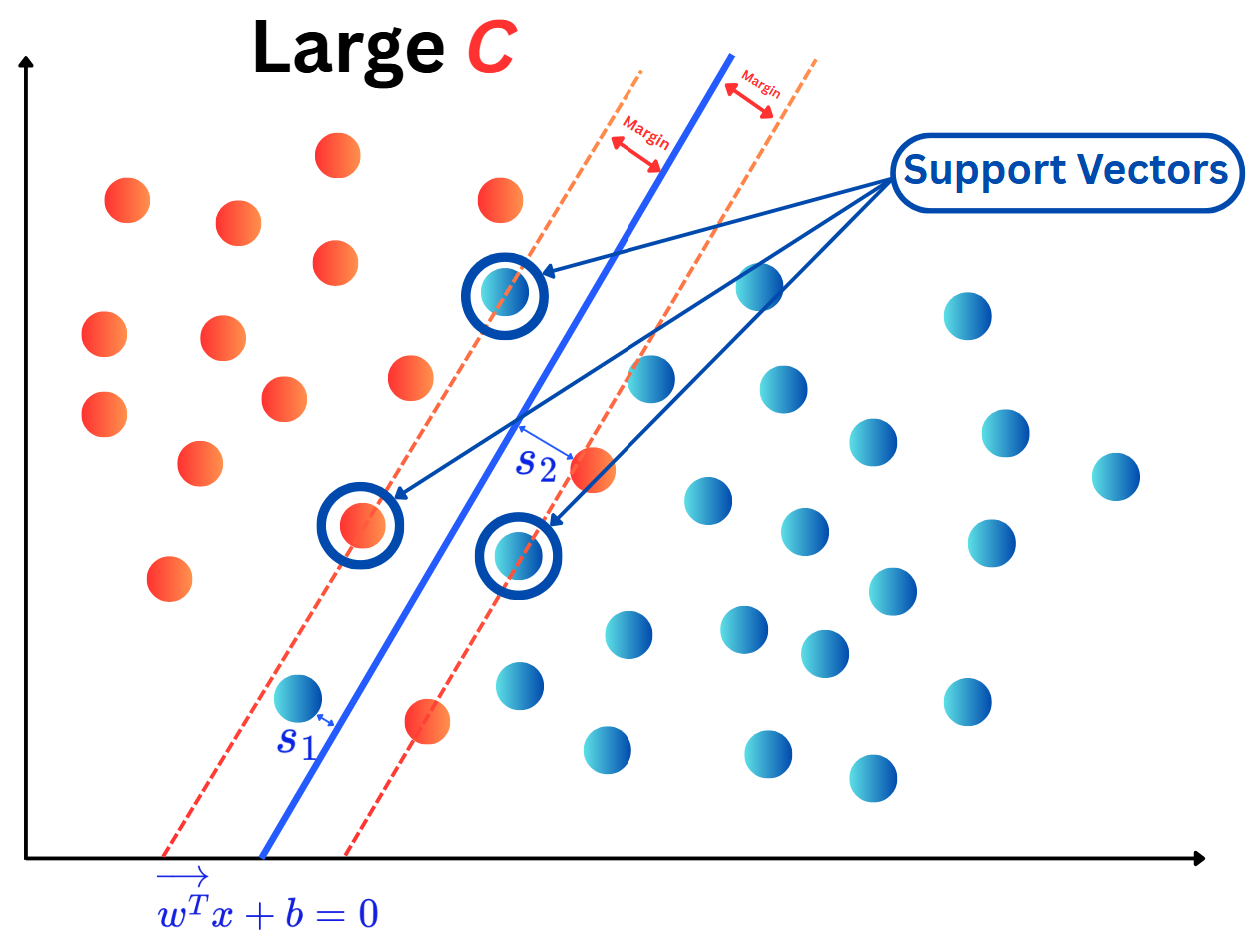
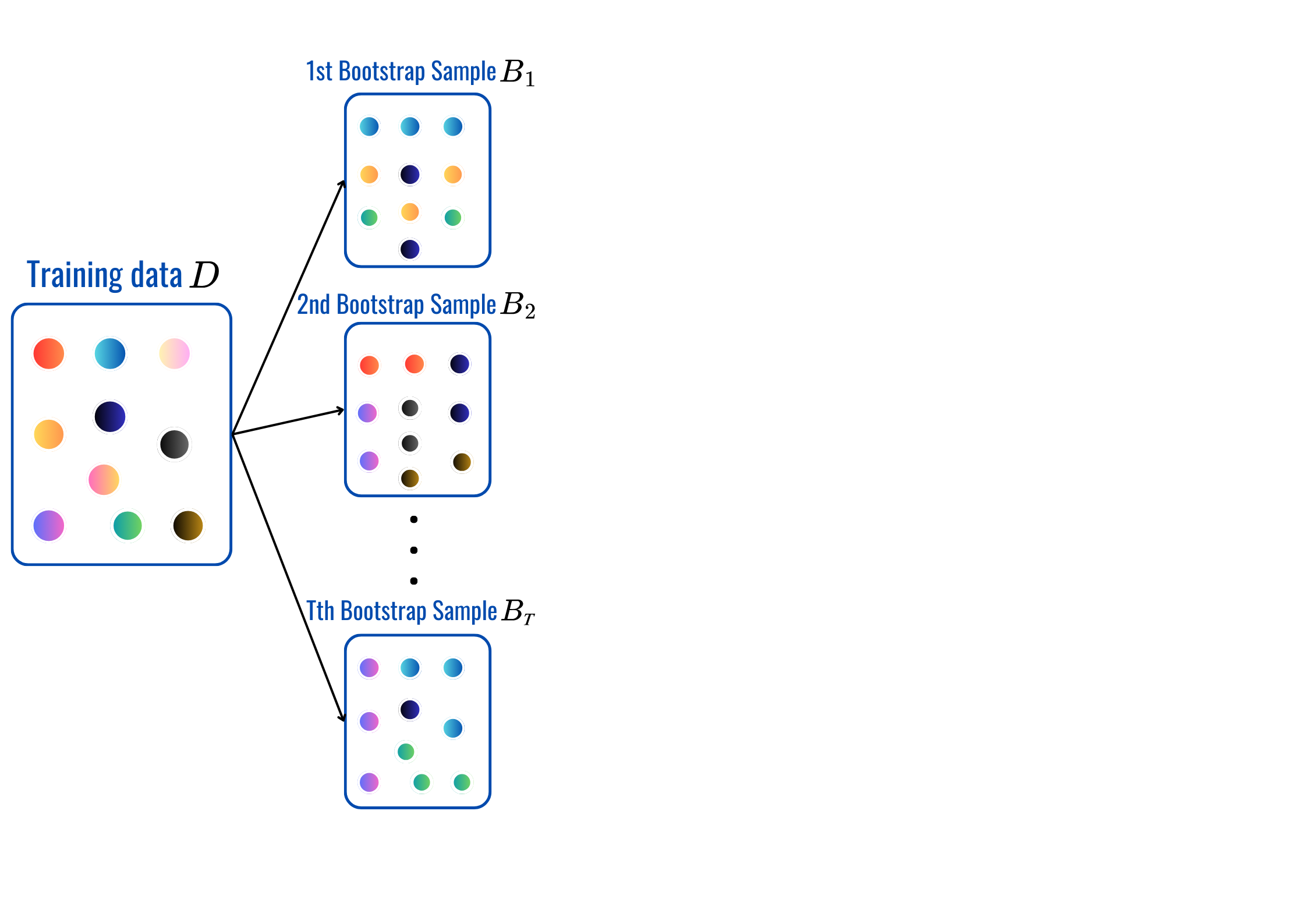
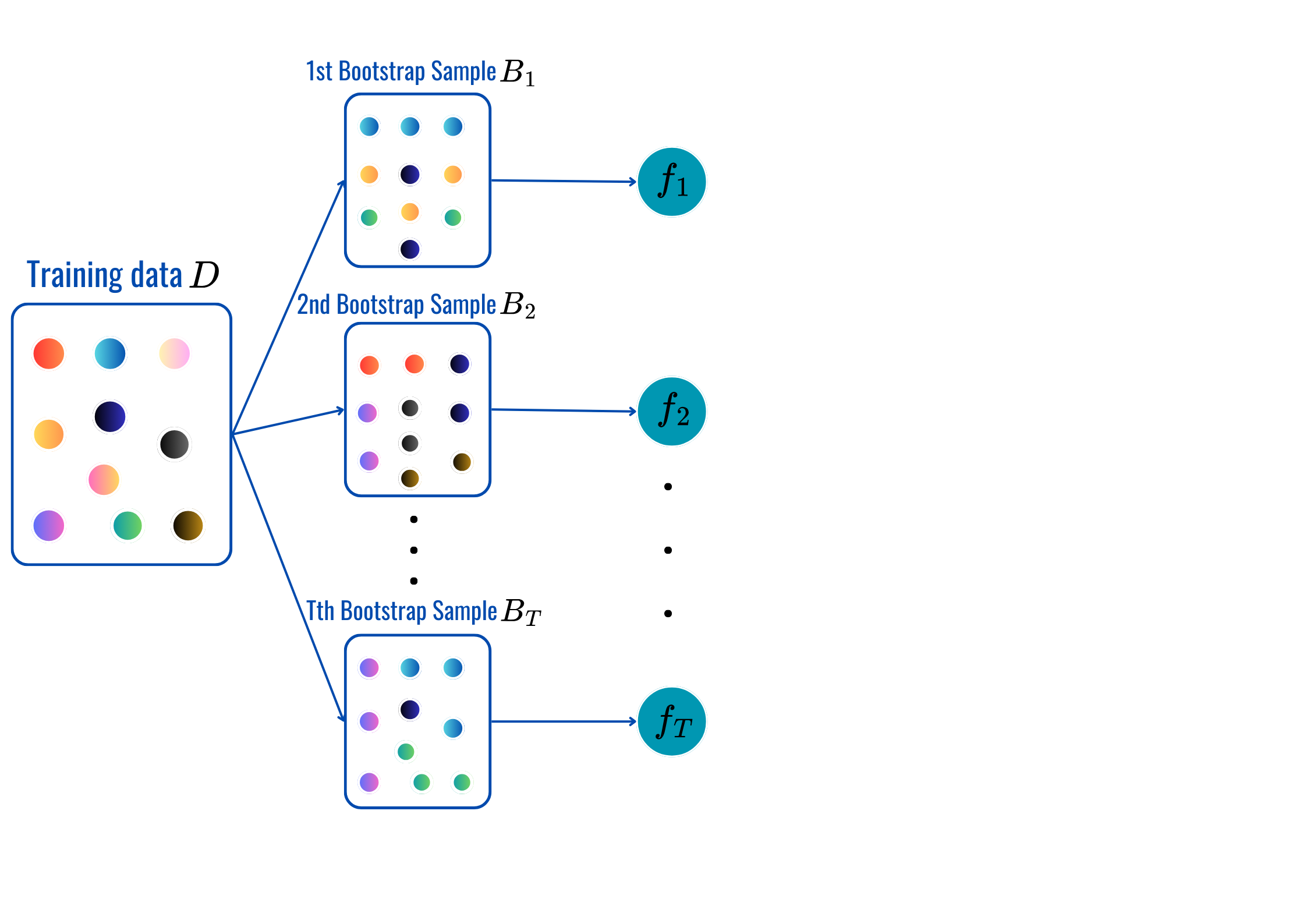
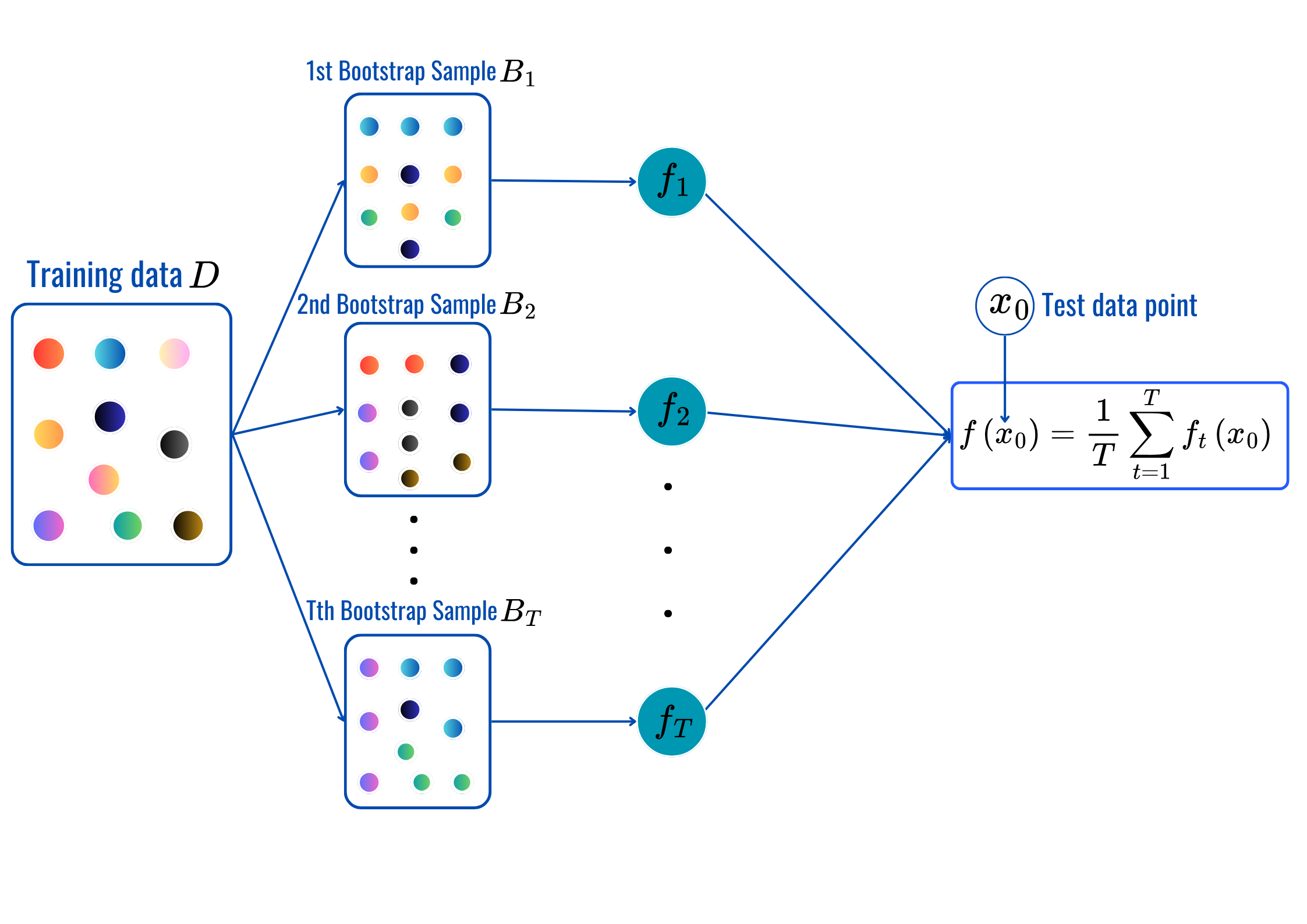
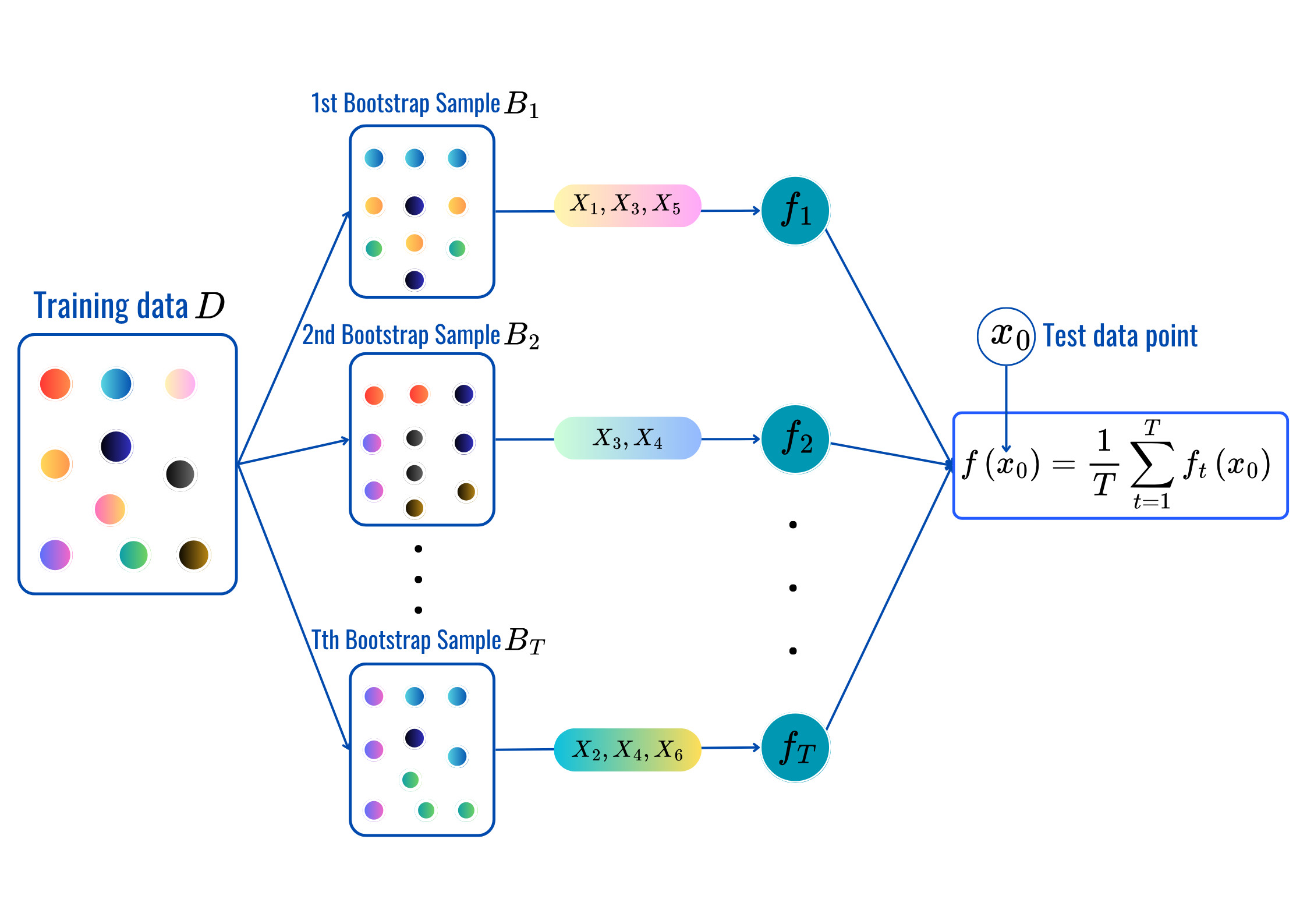
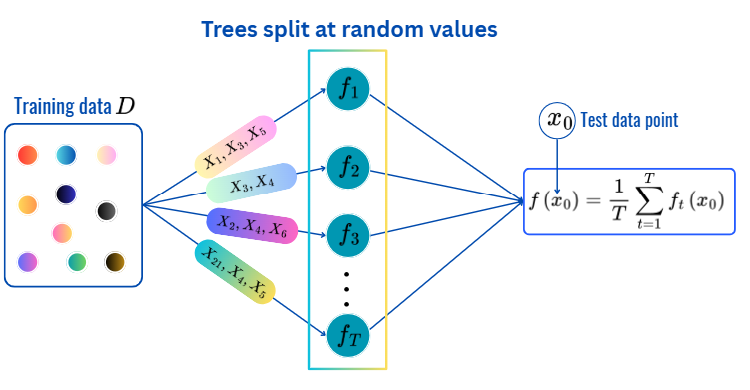
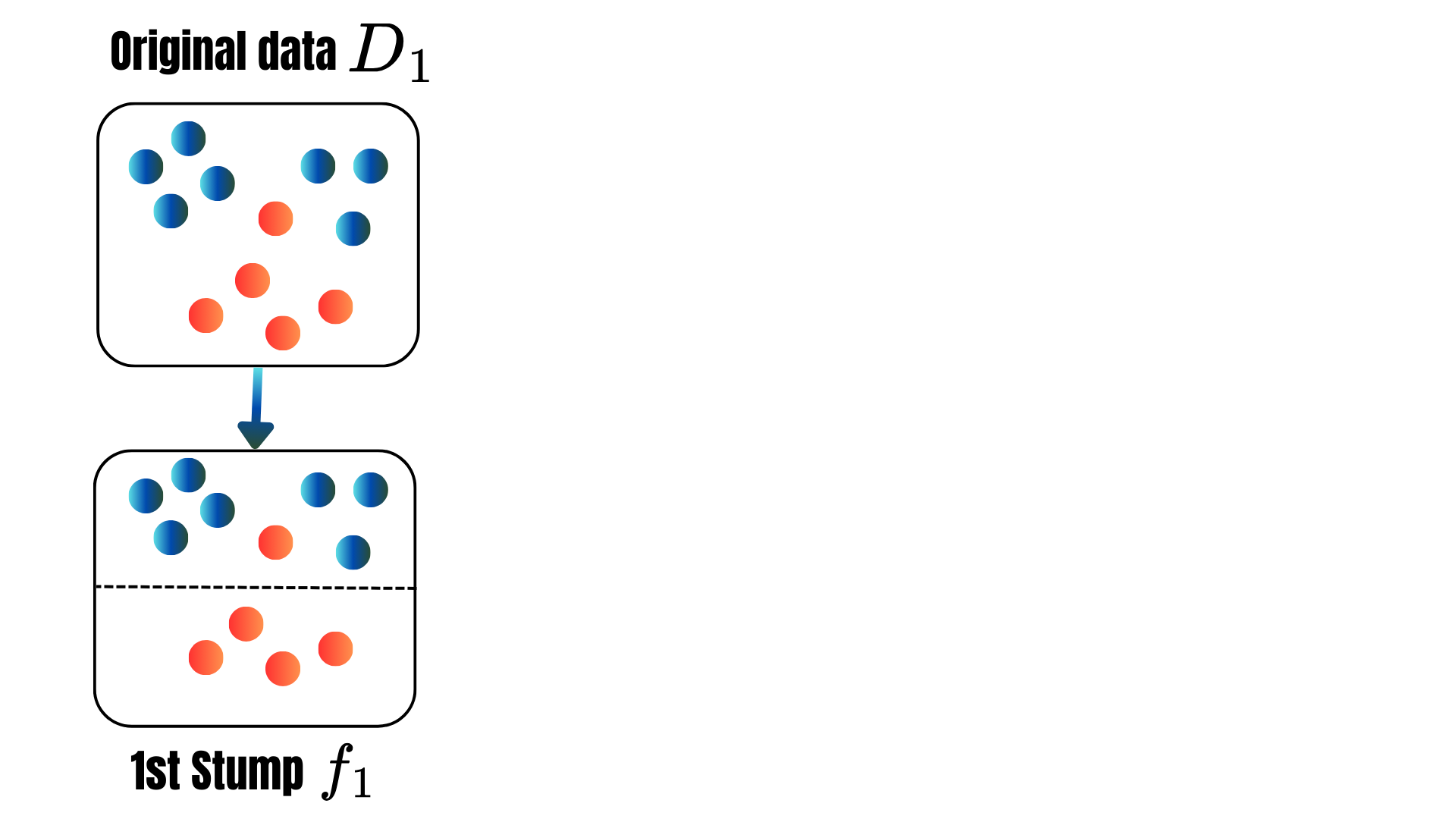
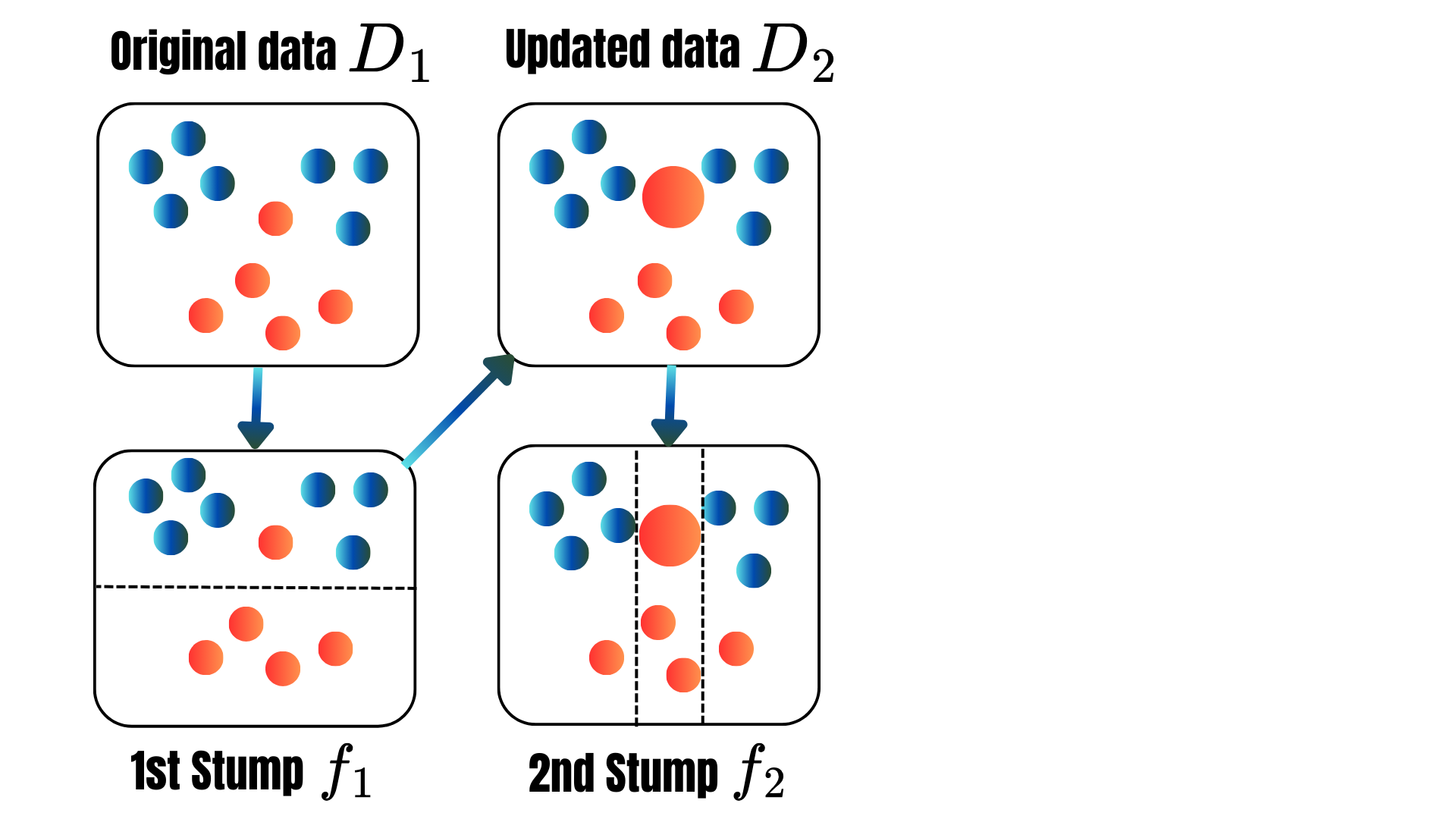
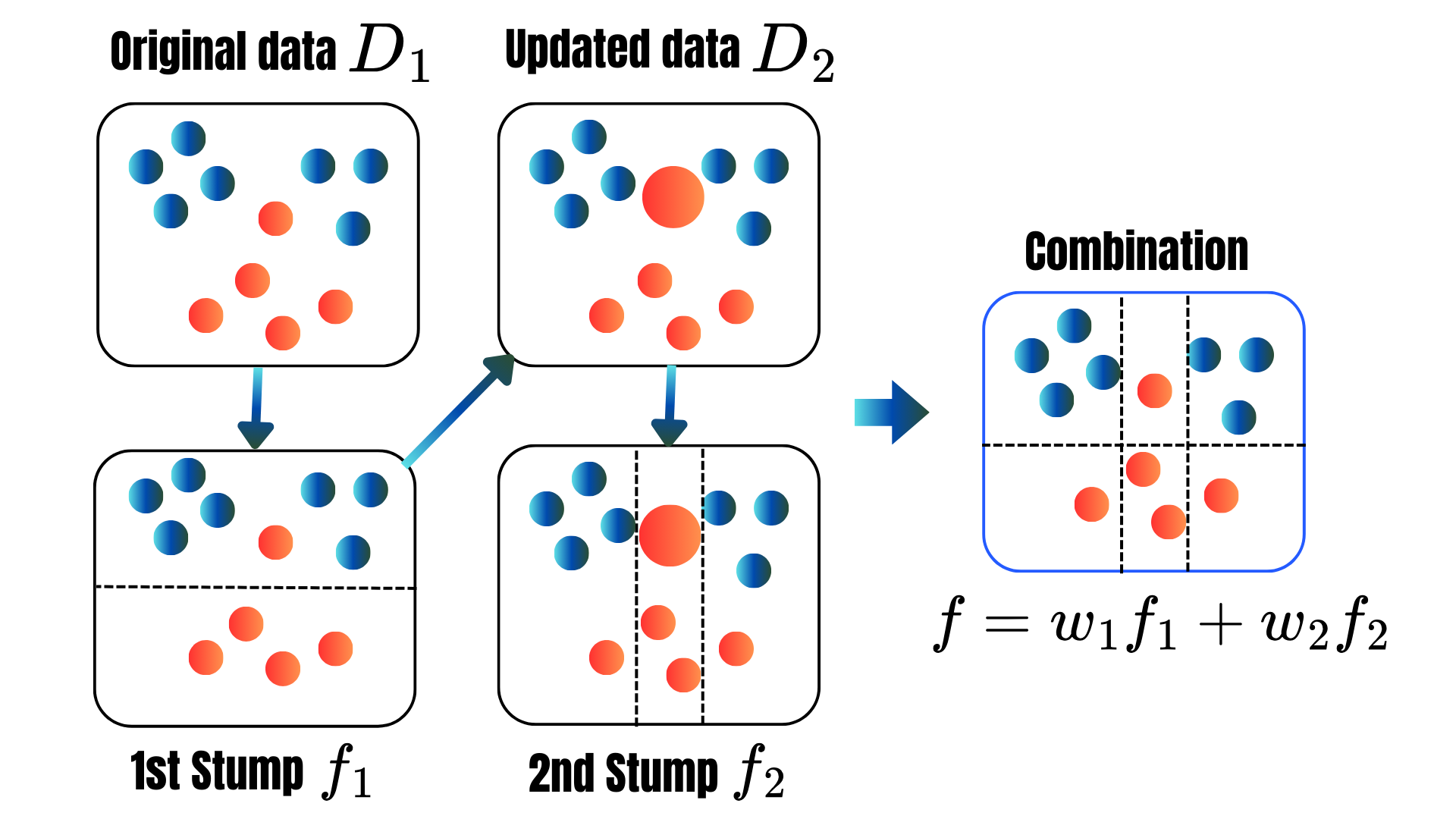
import numpy as np
import numpy as np
import plotly.graph_objects as go
import plotly.express as px
from plotly.subplots import make_subplots
from sklearn.datasets import make_classification, make_circles, make_moons
# Generate 2D binary classification datasets
def generate_2d_dataset(n_samples=500, boundary_type='linear', noise=0.1, random_state=42, mis_class = 0.1):
"""
Generate a 2D binary classification dataset with linear or non-linear decision boundary.
Parameters:
-----------
n_samples : int, default=500
Number of samples to generate
boundary_type : str, default='linear'
Type of decision boundary: 'linear', 'circular', 'moons', 'spiral'
noise : float, default=0.05
Amount of noise to add to the data (0.0 to 1.0)
random_state : int, default=42
Random state for reproducibility
Returns:
--------
X : ndarray of shape (n_samples, 2)
Feature matrix
y : ndarray of shape (n_samples,)
Target labels (0 or 1)
"""
np.random.seed(random_state)
if boundary_type == 'linear':
# Generate well-separated linearly separable data
X, y = make_classification(
n_samples=n_samples,
n_features=2,
n_redundant=0,
n_informative=2,
n_clusters_per_class=1,
random_state=random_state,
class_sep=1.5, # Increased separation
flip_y = mis_class
)
# Add minimal noise
X += np.random.normal(0, noise, X.shape)
elif boundary_type == 'circular':
# Generate well-separated circular decision boundary
X, y = make_circles(
n_samples=n_samples,
noise=noise, # Reduced noise
factor=0.4, # Better separation between circles
random_state=random_state
)
elif boundary_type == 'moons':
# Generate well-separated moon-shaped decision boundary
X, y = make_moons(
n_samples=n_samples,
noise=noise, # Reduced noise
random_state=random_state
)
elif boundary_type == 'spiral':
# Generate better separated spiral decision boundary
n_per_class = n_samples // 2
theta = np.linspace(0, 3*np.pi, n_per_class) # Reduced spiral length
# First spiral (class 0)
r1 = theta / (1.5*np.pi) # Slower growth rate
x1 = r1 * np.cos(theta)
y1 = r1 * np.sin(theta)
# Second spiral (class 1) - better separated
x2 = r1 * np.cos(theta + np.pi)
y2 = r1 * np.sin(theta + np.pi)
# Combine data
X = np.vstack([np.column_stack([x1, y1]), np.column_stack([x2, y2])])
y = np.hstack([np.zeros(n_per_class), np.ones(n_per_class)])
# Add minimal noise
X += np.random.normal(0, noise * 0.3, X.shape)
# Shuffle the data
indices = np.random.permutation(len(X))
X, y = X[indices], y[indices]
else:
raise ValueError("boundary_type must be one of: 'linear', 'circular', 'moons', 'spiral'")
return X, y.astype(int)
#| echo: true
#| code-fold: true
import warnings
warnings.filterwarnings('ignore')
# Plot decision boundary and data
def plot_decision_boundary(X, y, model=None, title="Decision Boundary",
resolution=100, alpha_contour=0.7, alpha_points=0.8,
colorscale='RdYlBu', point_size=8, show_mesh=True):
"""
Create an interactive decision boundary plot using Plotly with color gradients.
Parameters:
-----------
X : array-like of shape (n_samples, 2)
Feature matrix (must be 2D)
y : array-like of shape (n_samples,)
Target labels
model : sklearn estimator or None, default=None
Trained model that implements predict() and predict_proba() or decision_function().
If None, only plots the dataset without decision boundary.
title : str, default="Decision Boundary"
Title for the plot
resolution : int, default=100
Resolution of the decision boundary mesh
alpha_contour : float, default=0.7
Transparency of the decision boundary
alpha_points : float, default=0.8
Transparency of the data points
colorscale : str, default='RdYlBu'
Plotly colorscale for the decision boundary
point_size : int, default=8
Size of the scatter points
show_mesh : bool, default=True
Whether to show the decision boundary mesh (ignored if model is None)
Returns:
--------
fig : plotly.graph_objects.Figure
Interactive Plotly figure
"""
# Create the figure
fig = go.Figure()
# Add decision boundary contour only if model is provided and show_mesh is True
if model is not None and show_mesh:
# Ensure model is fitted
if not hasattr(model, 'predict'):
raise ValueError("Model must be fitted and have a predict method")
# Create mesh grid
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, resolution),
np.linspace(y_min, y_max, resolution))
mesh_points = np.c_[xx.ravel(), yy.ravel()]
# Get predictions for the mesh
try:
# Try to get probability predictions for smoother boundaries
if hasattr(model, 'predict_proba'):
Z = model.predict_proba(mesh_points)[:, 1] # Probability of class 1
elif hasattr(model, 'decision_function'):
Z = model.decision_function(mesh_points)
# Normalize decision function output to [0, 1] range
Z = (Z - Z.min()) / (Z.max() - Z.min())
else:
Z = model.predict(mesh_points).astype(float)
except Exception as e:
print(f"Error getting model predictions: {e}")
Z = model.predict(mesh_points).astype(float)
Z = Z.reshape(xx.shape)
# Add decision boundary contour
fig.add_trace(go.Contour(
x=np.linspace(x_min, x_max, resolution),
y=np.linspace(y_min, y_max, resolution),
z=Z,
colorscale=colorscale,
opacity=alpha_contour,
showscale=True,
colorbar=dict(
title="Decision<br>Confidence",
tickmode="linear",
tick0=0,
dtick=0.2
),
contours=dict(
start=0,
end=1,
size=0.1,
),
name="Decision Boundary"
))
# Add data points
unique_labels = np.unique(y)
colors = px.colors.qualitative.Set1[:len(unique_labels)]
for i, label in enumerate(unique_labels):
mask = y == label
fig.add_trace(go.Scatter(
x=X[mask, 0],
y=X[mask, 1],
mode='markers',
marker=dict(
size=point_size,
color=colors[i],
opacity=alpha_points,
line=dict(width=1, color='black')
),
name=f'Class {label}',
hovertemplate=f'<b>Class {label}</b><br>' +
'Feature 1: %{x:.2f}<br>' +
'Feature 2: %{y:.2f}<br>' +
'<extra></extra>'
))
# Update layout
fig.update_layout(
title=dict(
text=title,
x=0.5,
font=dict(size=18, family="Arial Black")
),
xaxis_title="Feature 1",
yaxis_title="Feature 2",
width=700,
height=600,
showlegend=True,
legend=dict(
yanchor="top",
y=0.99,
xanchor="left",
x=0.01,
bgcolor="rgba(255,255,255,0.8)",
bordercolor="black",
borderwidth=1
),
plot_bgcolor='white',
paper_bgcolor='white'
)
# Make axes equal
fig.update_xaxes(scaleanchor="y", scaleratio=1)
fig.update_yaxes(scaleanchor="x", scaleratio=1)
# Add information text if no model is provided
if model is None:
fig.add_annotation(
xref="paper", yref="paper",
x=0.02, y=0.02,
text="Dataset visualization<br>(No model provided)",
showarrow=False,
font=dict(size=12, color="gray"),
bgcolor="rgba(255,255,255,0.8)",
bordercolor="gray",
borderwidth=1
)
return fig
n = 300
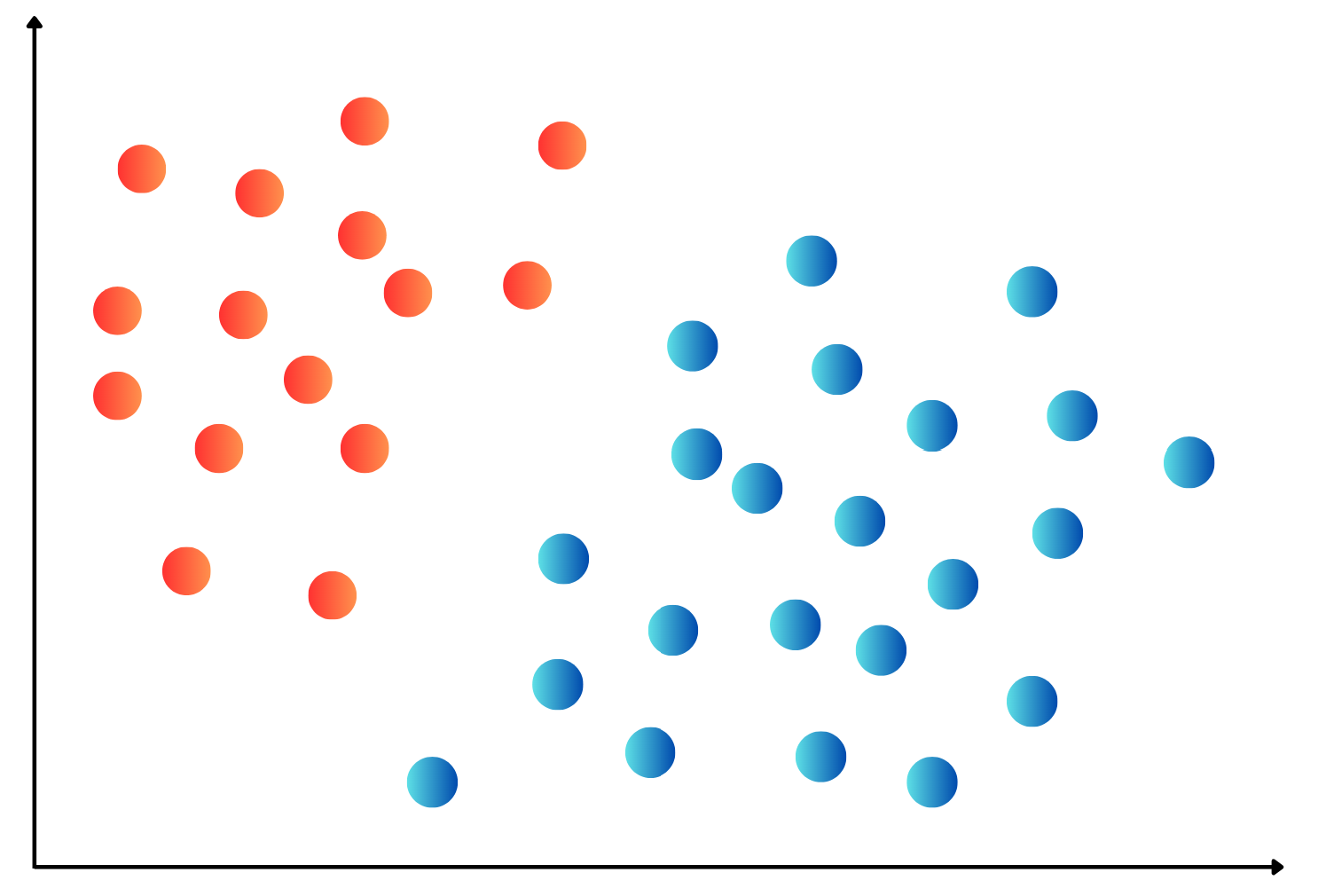
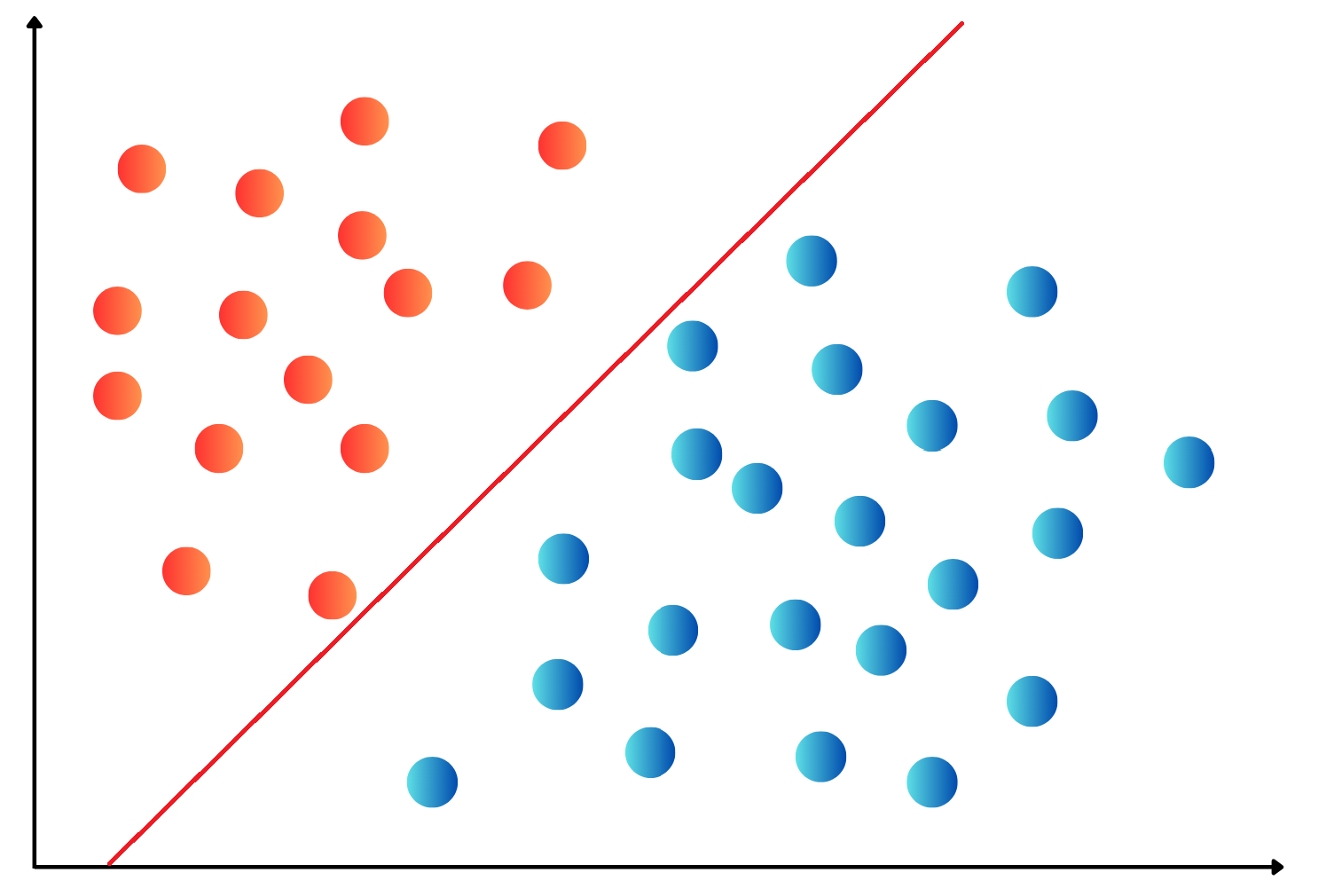
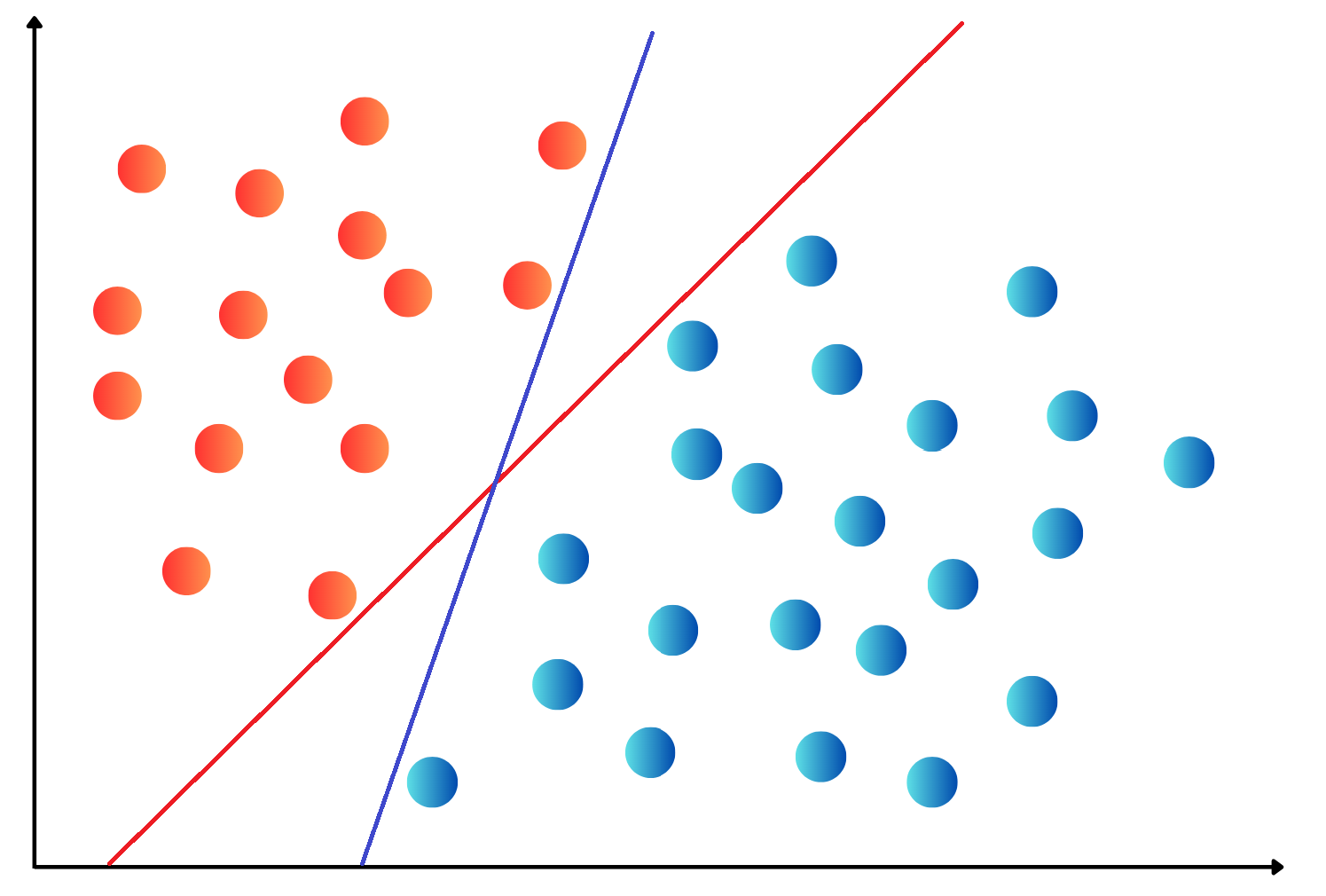
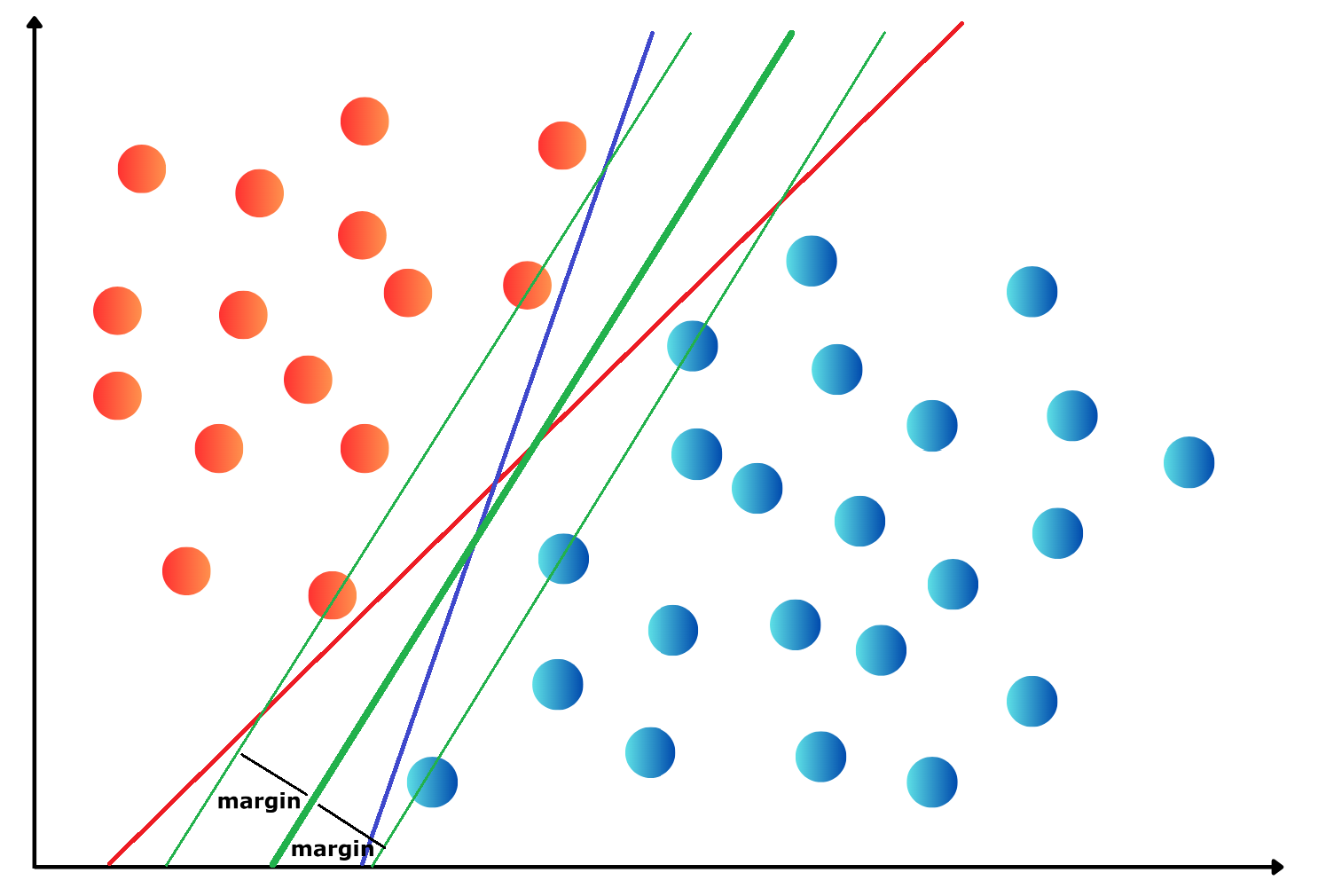
data1 = generate_2d_dataset(n_samples=n, boundary_type="moons", noise=0.2)
fig1 = plot_decision_boundary(data1[0], data1[1], model=None)
fig1.update_layout(
title="Non-linear Decision Boundary Example (Moons Dataset)",
width=500,
height=270
)
fig1.show()