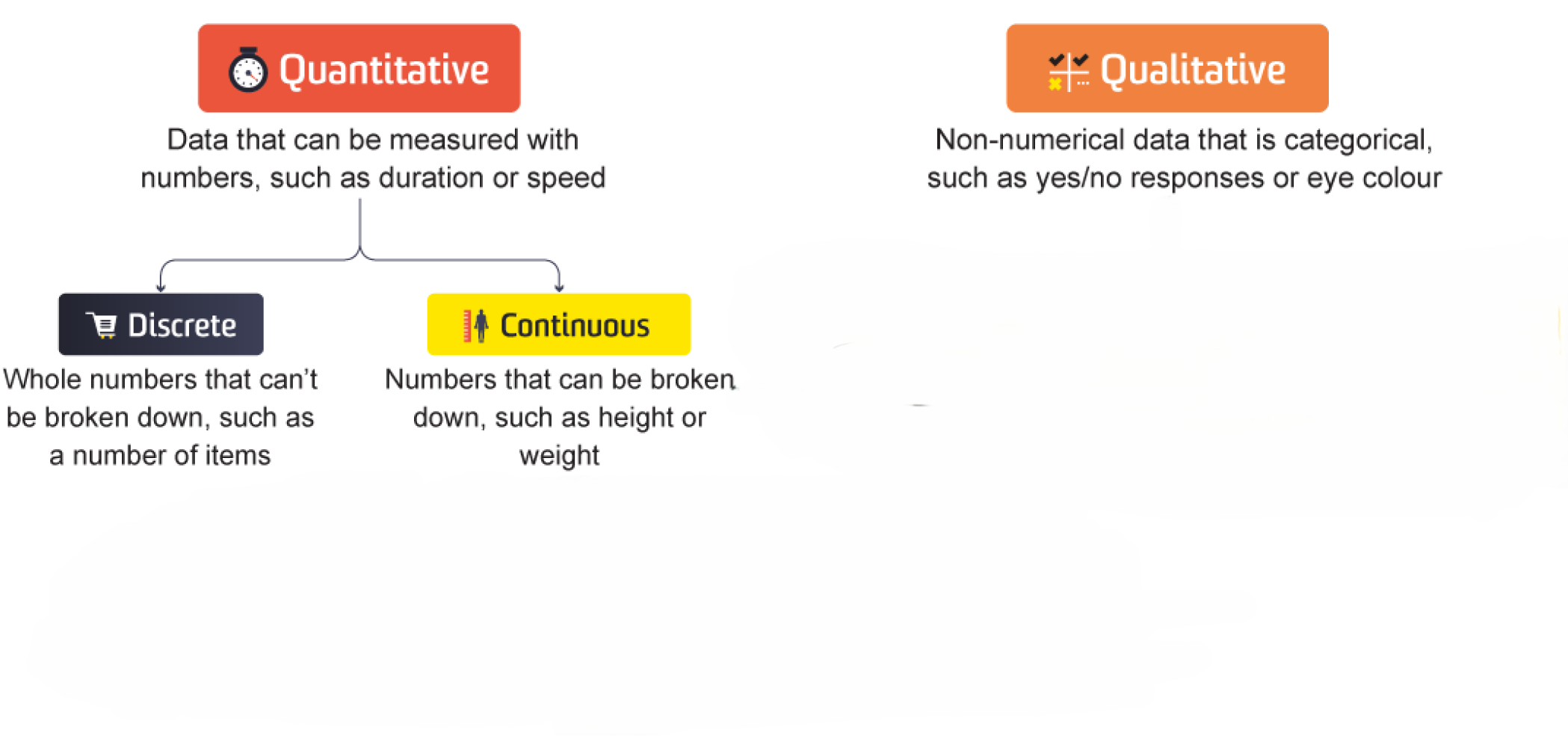
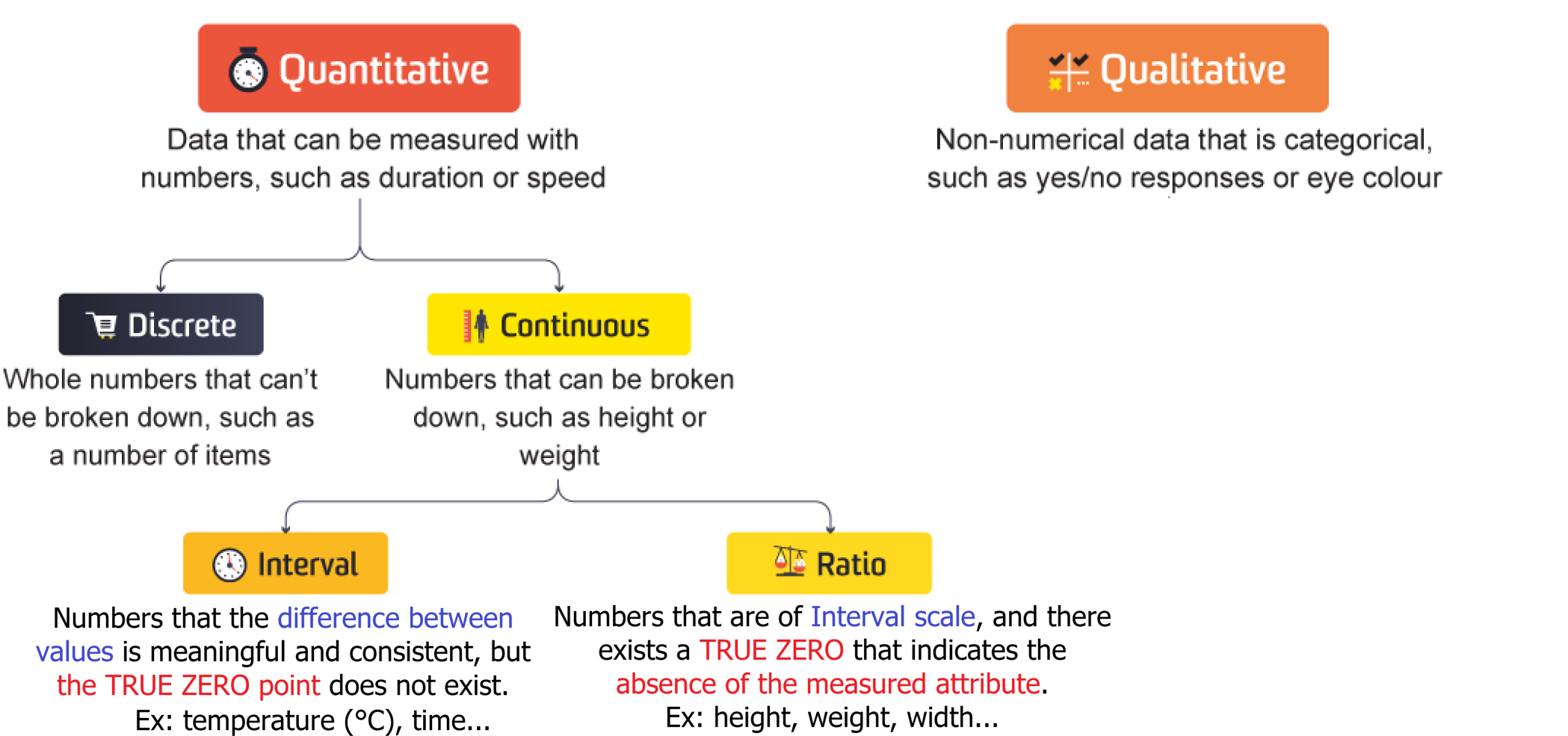
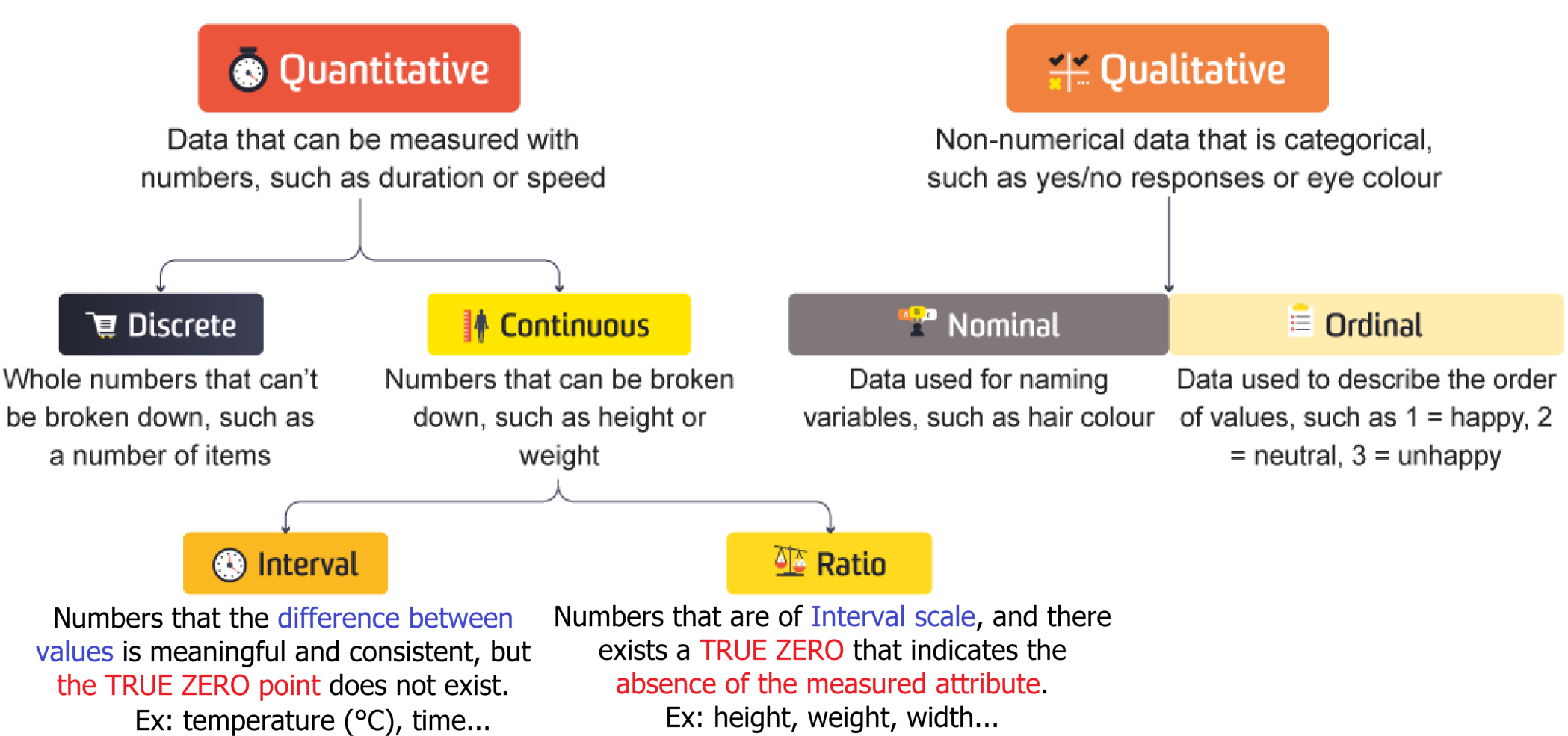
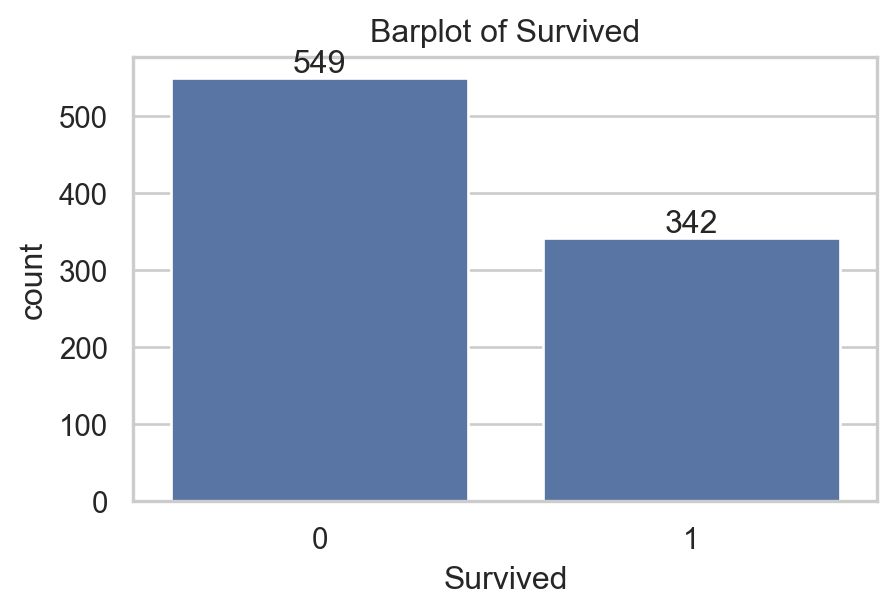
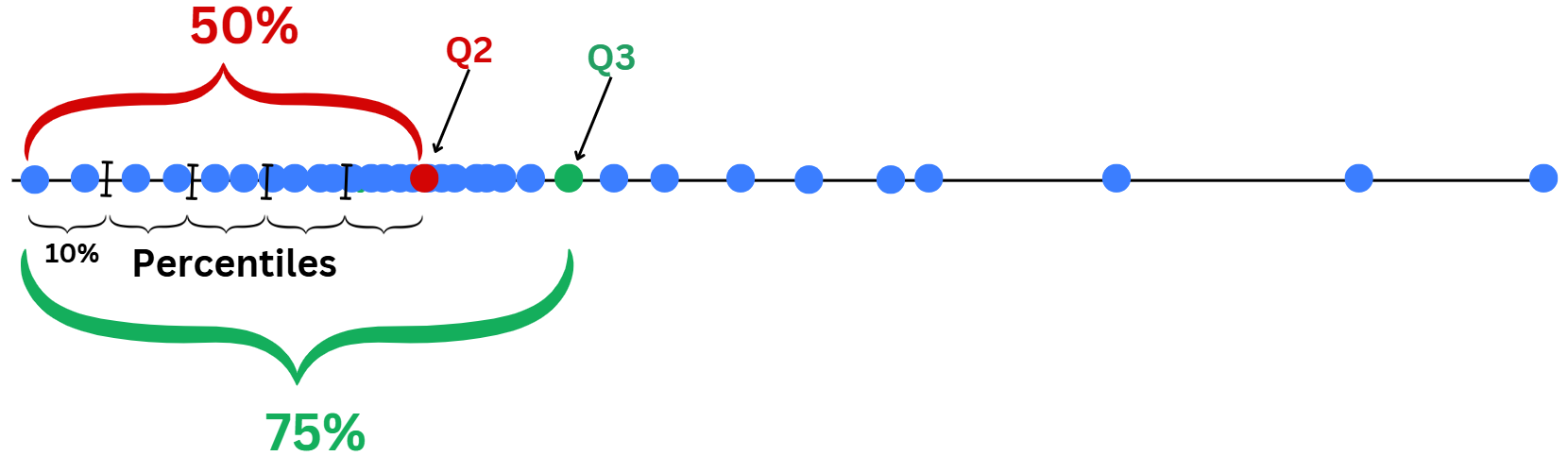
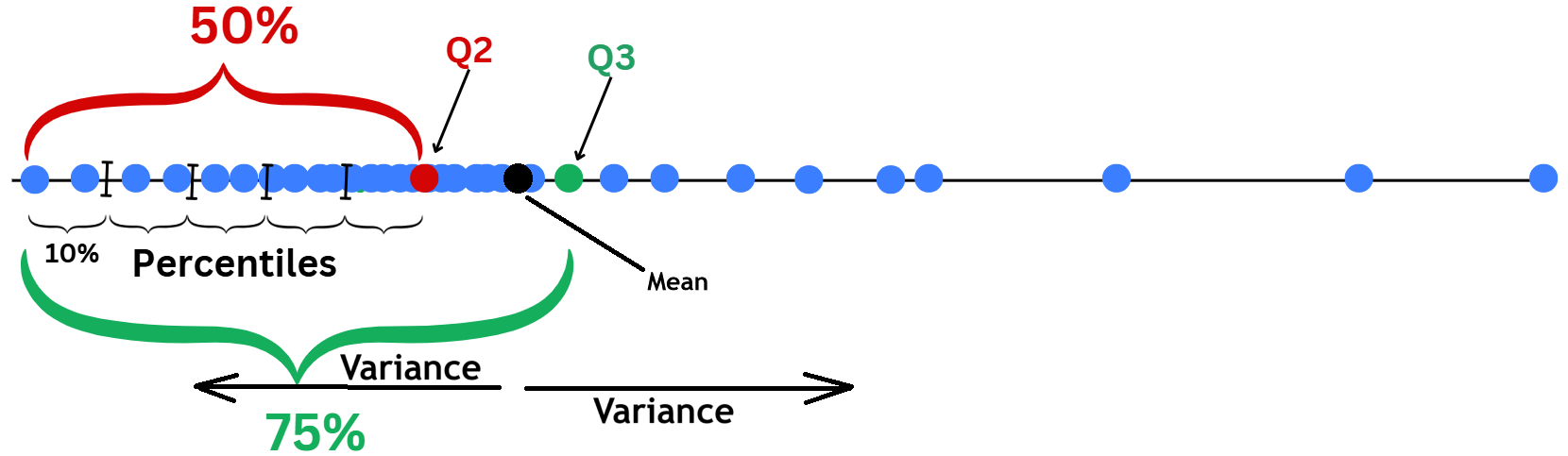
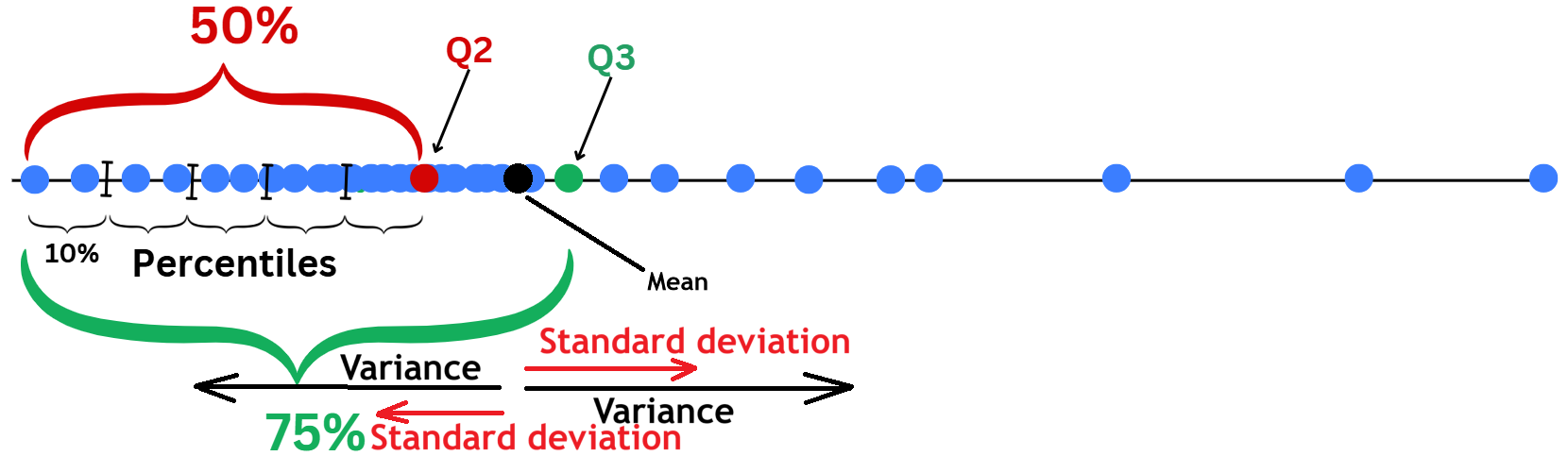
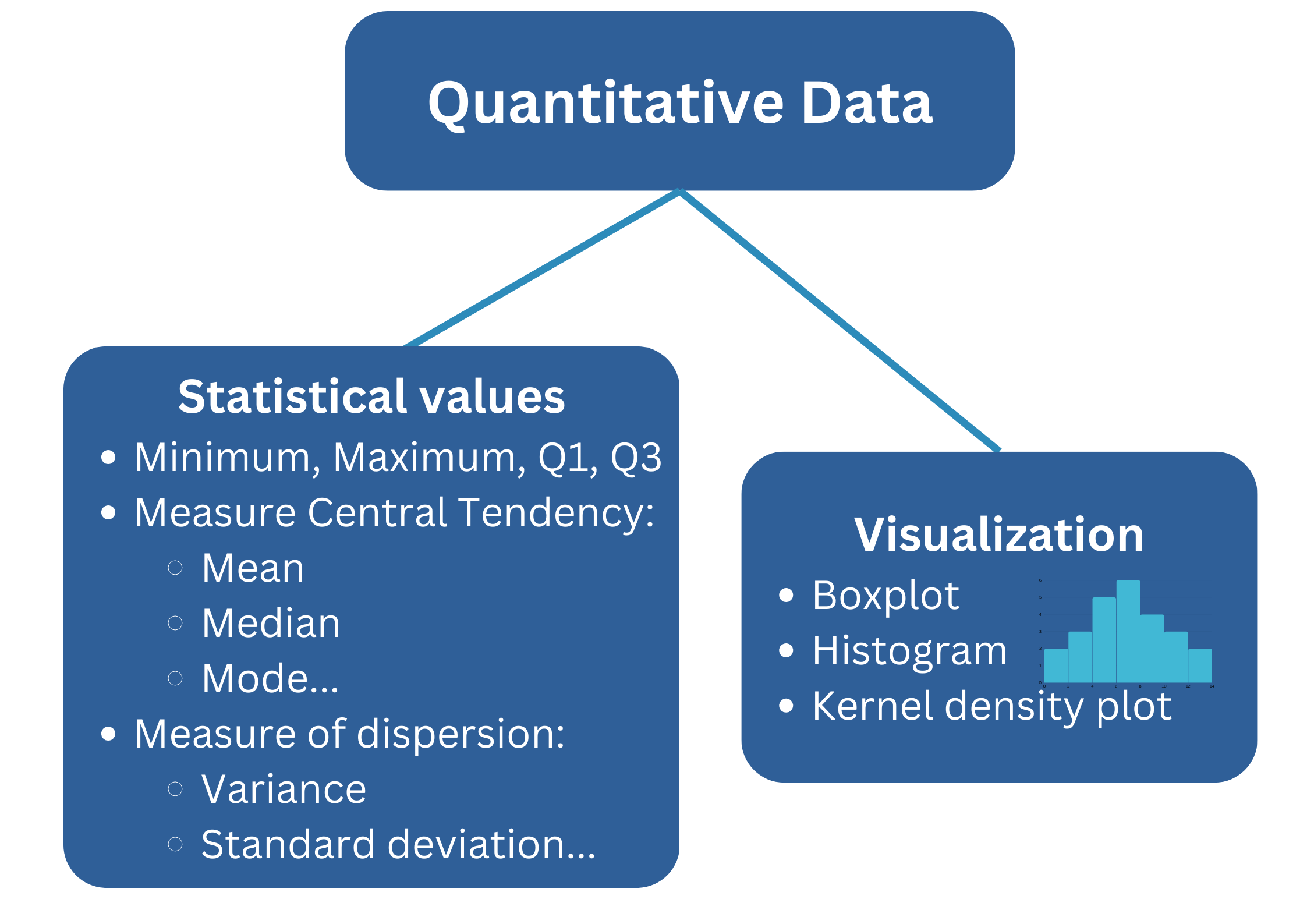
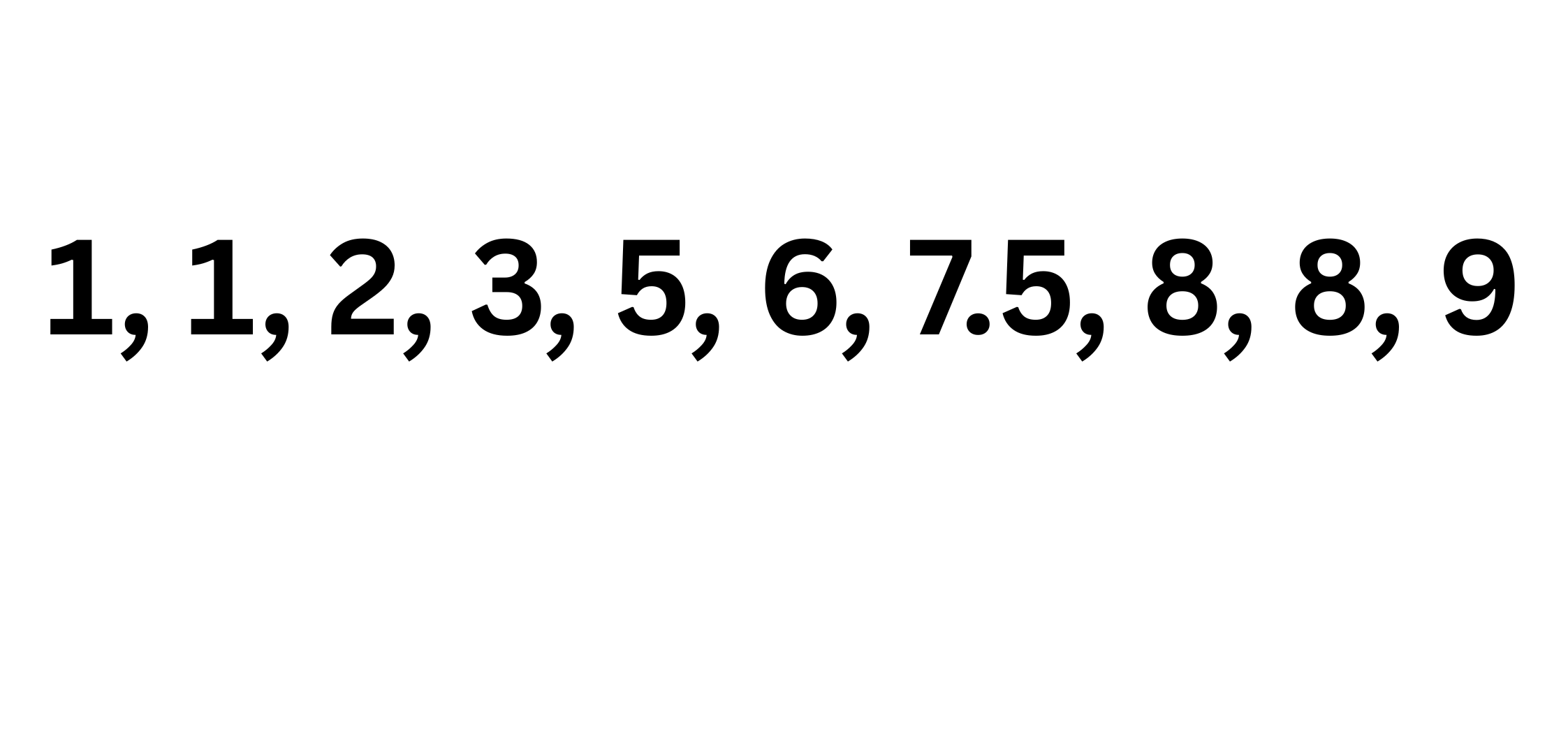quan_var = ['Age', 'SibSp', 'Parch', 'Fare']
cols = ['#C96451', '#80C96F', '#6B7FDB', '#C07EDE']
fig = make_subplots(
rows=2, cols=4,
subplot_titles=("Distribution of Age", "Distribution of Parch", "Distribution of SibSp", "Distribution of log(Fare)", "","","",""))
for i, va in enumerate(quan_var):
fig.add_trace(
go.Box(x=data[va].values, name=va, marker_color = cols[i]), col=i+1, row=1)
fig.add_trace(
go.Histogram(x=data[va].values, name=va, marker_color = cols[i]), col=i+1, row=2)
fig.update_layout(height=450, width=1000)
fig.update_xaxes(type="log", row=1, col=4)
fig.update_yaxes(type="log", row=2, col=4)
fig.show()