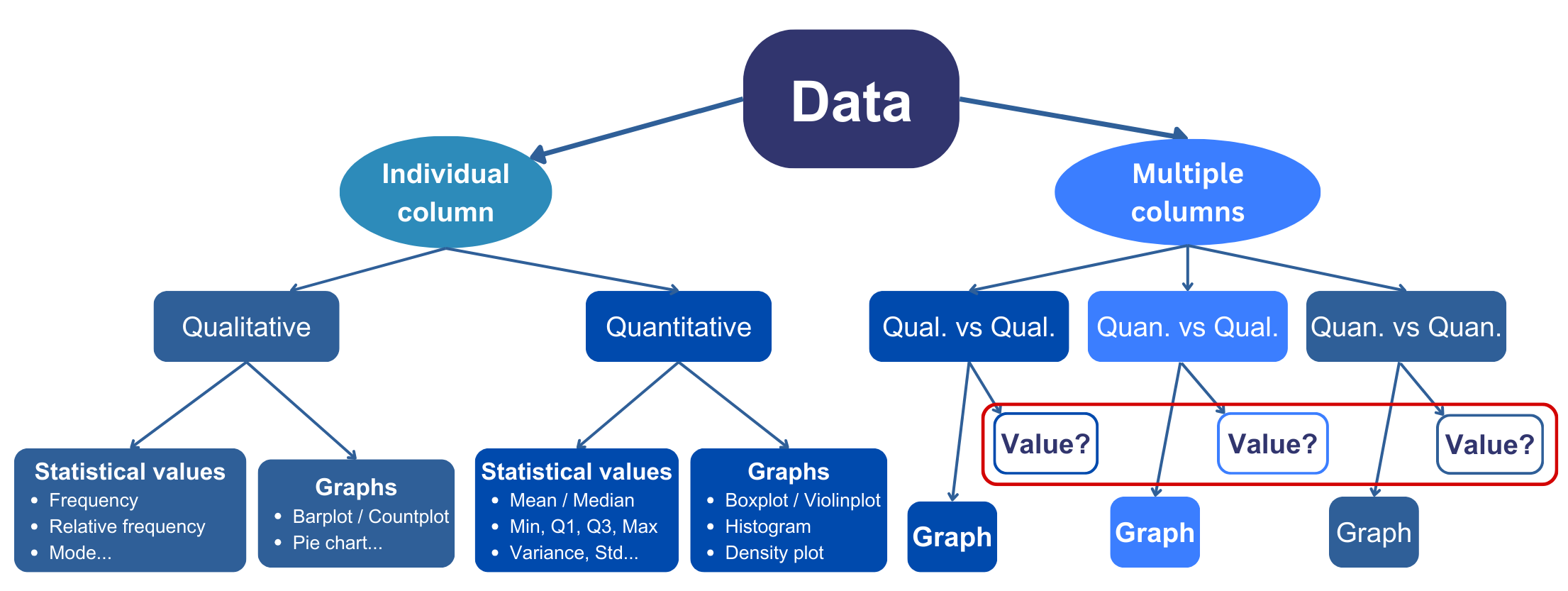
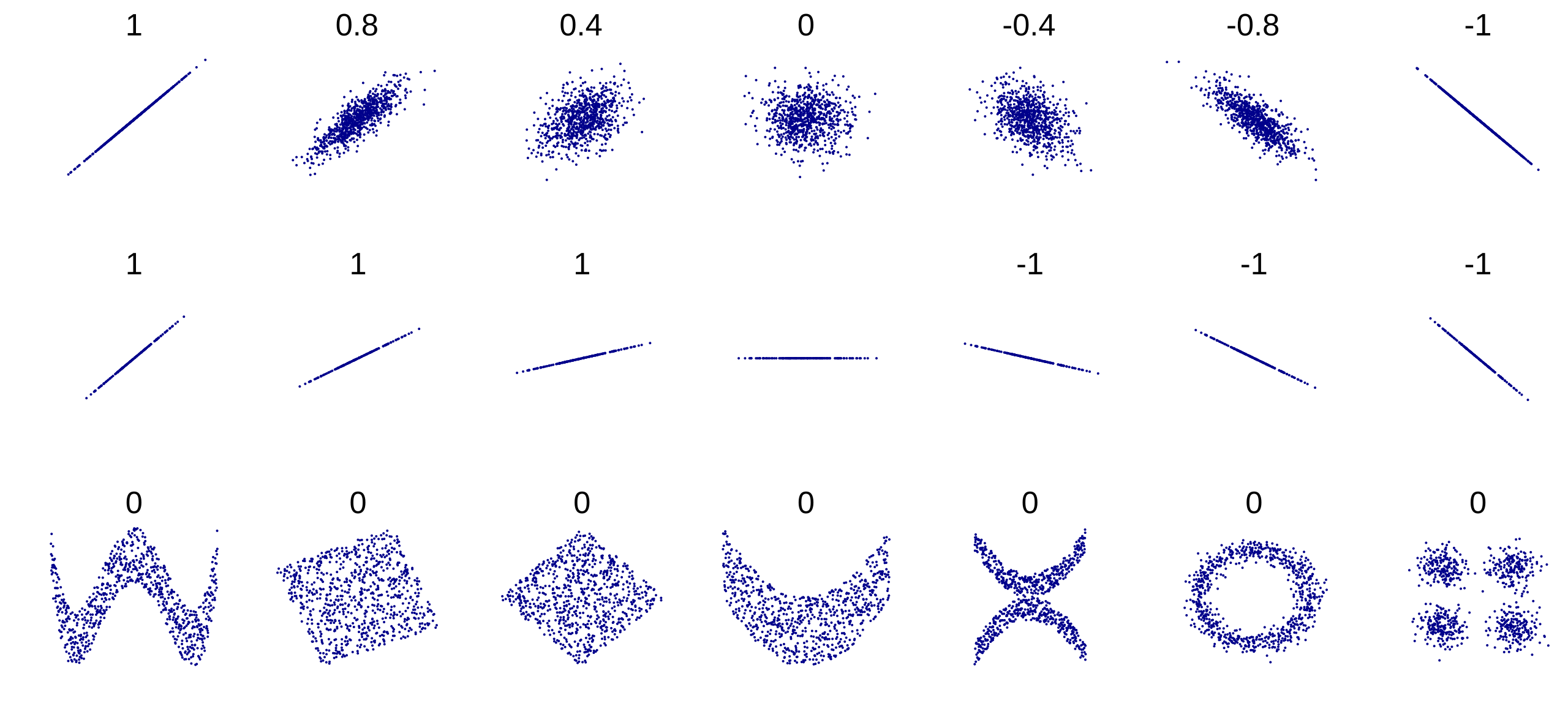
Pearson correlation coefficient
- Correlation between two quan. columns \(X\) and \(Y\): \[r=r_{X,Y}=\frac{\sum_{i=1}^n(\text{x}_{i}-\overline{x})(\text{y}_{i}-\overline{y})}{\sqrt{\left(\sum_{i=1}^n(x_{i1}-\overline{x}_{1})^2\right)\left(\sum_{i=1}^n(x_{i2}-\overline{x}_{2})^2\right)}}=\frac{\text{Cov}(X,Y)}{s_Xs_Y}.\]
- It quantifies the linear relationship/tendency between the two variables.
- For any pair \(X\) and \(Y\) one has \(-1\leq r\leq 1\).
- If \(r\approx 1\), then \(X\) and \(Y\) are positively correlated (change in the same direction).
- If \(r\approx -1\), then \(X\) and \(Y\) are negatively correlated (change in opposite direction).
- If \(r\approx 0\), then \(Y\) and \(Y\) are decorrelated (no pattern/trend/tendency).
- It helps identifying informative/useful inputs for the building models.
- It also helps identifying redundant (strongly correlated) inputs.
- For
tip example: \(\text{Corr}(\text{tip}, \text{bill})=\) 0.676.
- Note: Correlation does not imply causation; it only indicates a relationship, not a cause-and-effect link [👉 For more, read here].