| Sex | Pclass | Fare | Cabin | |
|---|---|---|---|---|
| 0 | male | 3 | 7.2500 | NaN |
| 1 | female | 1 | 71.2833 | C85 |
| 2 | female | 3 | 7.9250 | NaN |
| 3 | female | 1 | 53.1000 | C123 |
| 4 | male | 3 | 8.0500 | NaN |
| 5 | male | 3 | 8.4583 | NaN |
| 6 | male | 1 | 51.8625 | E46 |
| 7 | male | 3 | 21.0750 | NaN |
| 8 | female | 3 | 11.1333 | NaN |
| 9 | female | 2 | 30.0708 | NaN |
| 10 | female | 3 | 16.7000 | G6 |
| 11 | female | 1 | 26.5500 | C103 |
Data Quality & Preprocessing
INF-604: Data Analysis
![]()
Data Sources
Format
Structured
- Highly organized and easily searchable in databases using predefined schemas.
Structure:typically stored in tables with rows and columns.Example:- Spreadsheets: Excel
![]()
- CSV files
- Spreadsheets: Excel

Unstructured
- Lacks a predefined format or schema and is typically stored in its raw form.
Structure:Free-form and can betext,images,videos…Example:- Emails/Documents (e.g., Word files, PDFs)
- Social media posts, images, audio, videos
- Web pages…
Data quality
- Someone in 60s said Garbage In, Garbage Out (GIGO)!.
- Data quality is the most important thing in Data Analysis.
Data quality
Data quality
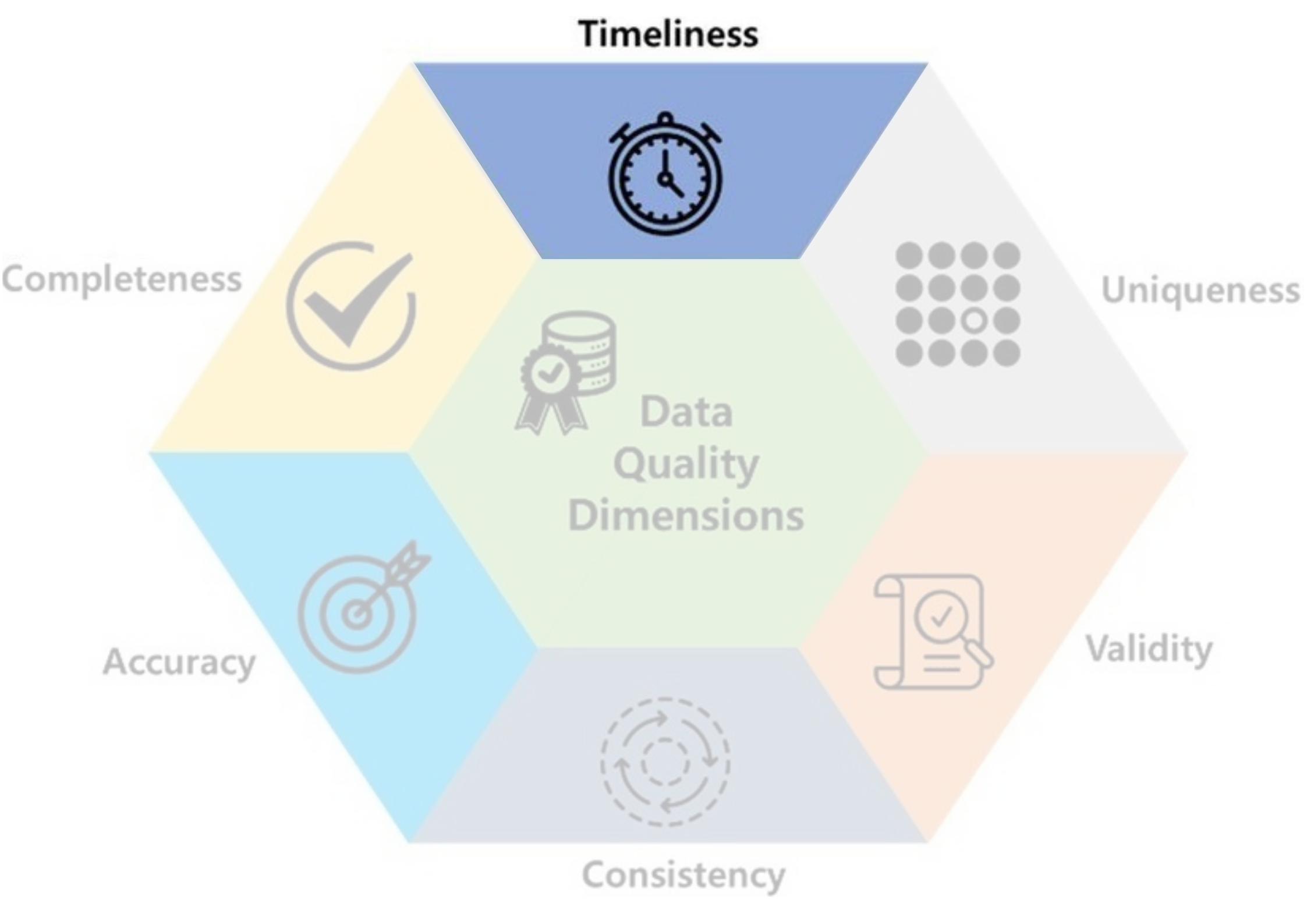
- Timeliness: how up-to-date the data is for its intended use.
- Ex: Temperature of 60s wouldn’t help forecasting tomorrow.
Data quality
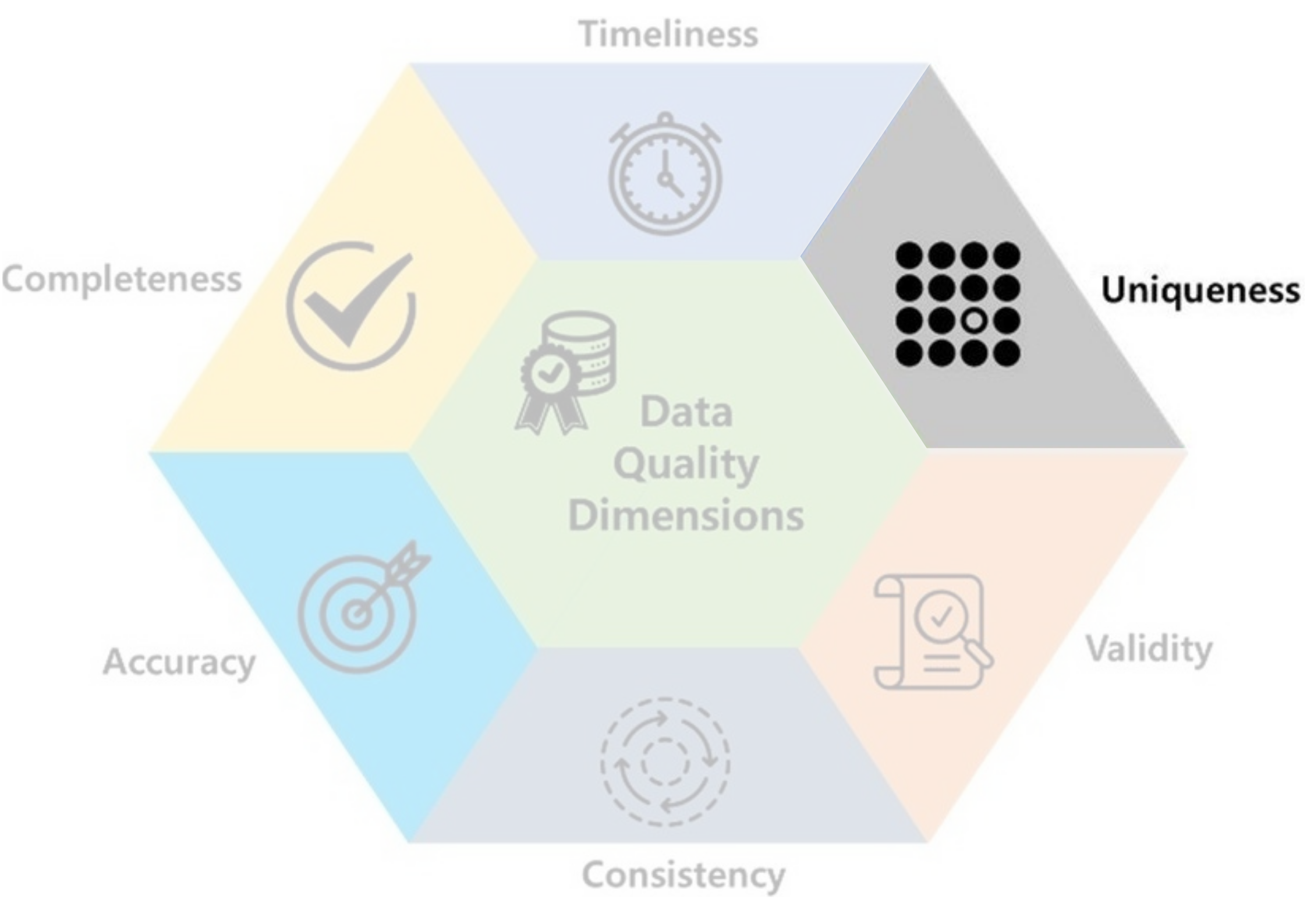
- Uniqueness: data should not be duplicated.
- Ex: Recording the same female heart disease patient many times may lead to a conclusion that females have a higher likelihood of developing heart disease.
Data quality
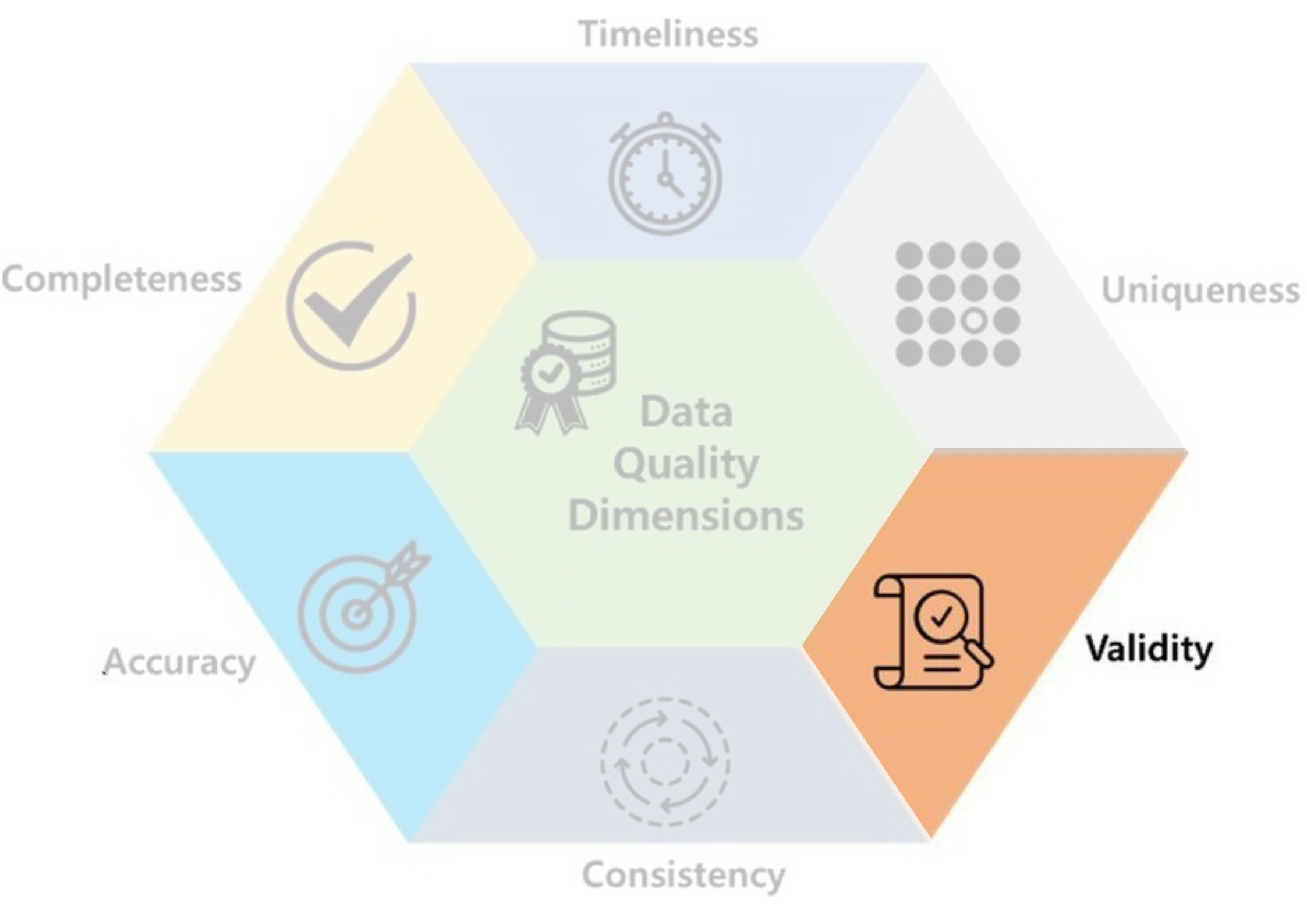
- Validity: data should take values within its valid range.
- Ex: Height & weight should not be 0 nor negative!
Data quality
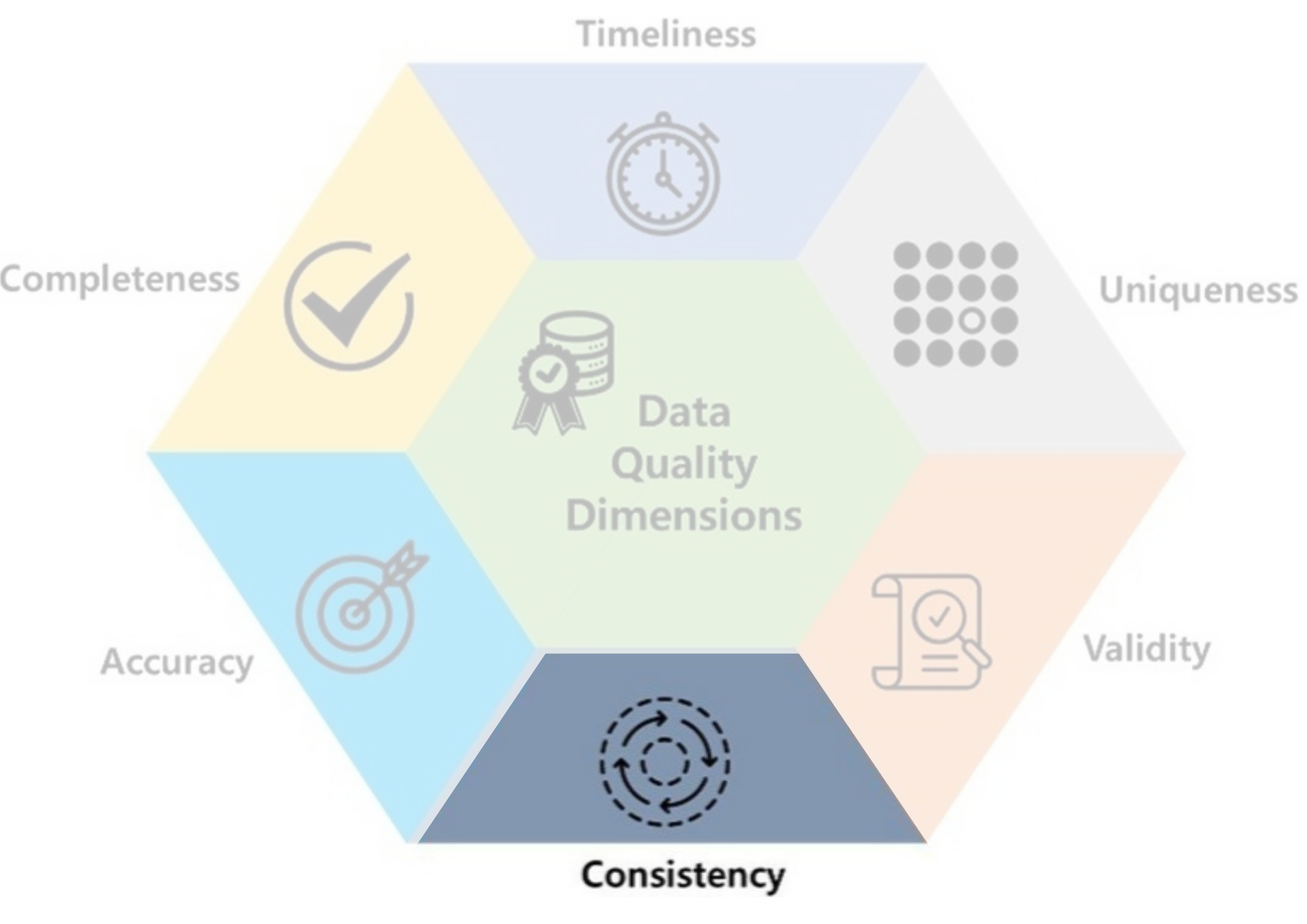
- Consistency: data should be uniform and compatible (format, type…) across different datasets and over time.
- Ex: 15/03/2004 & 03/15/2004, Male & M…
Data quality
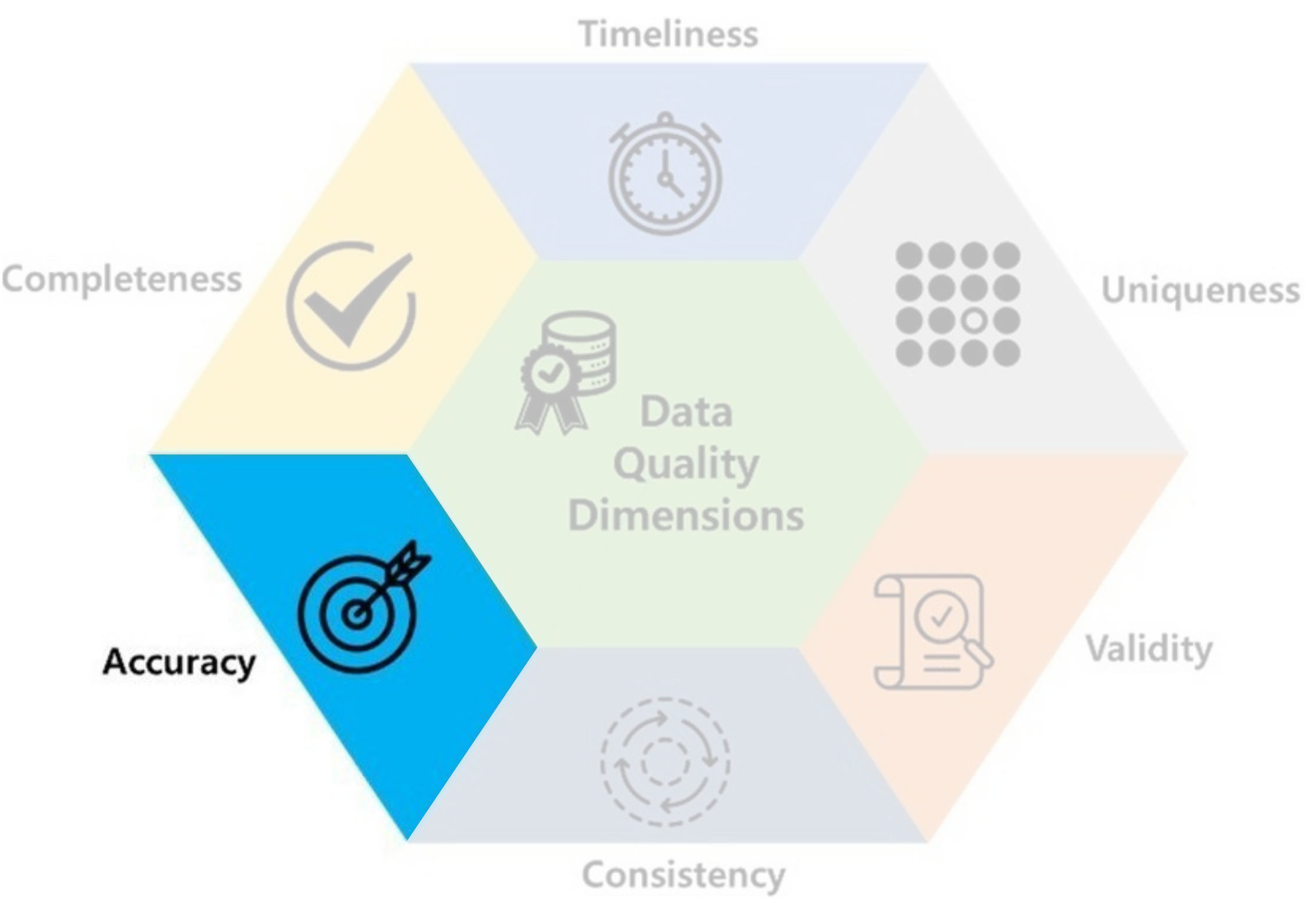
- Accuracy: data should be accurate and reflects what it is meant to measure.
- Ex: You cried and said ‘I like Data Analysis Course SO MUCH 😭!’ when I ask nicely (😠).
Data quality
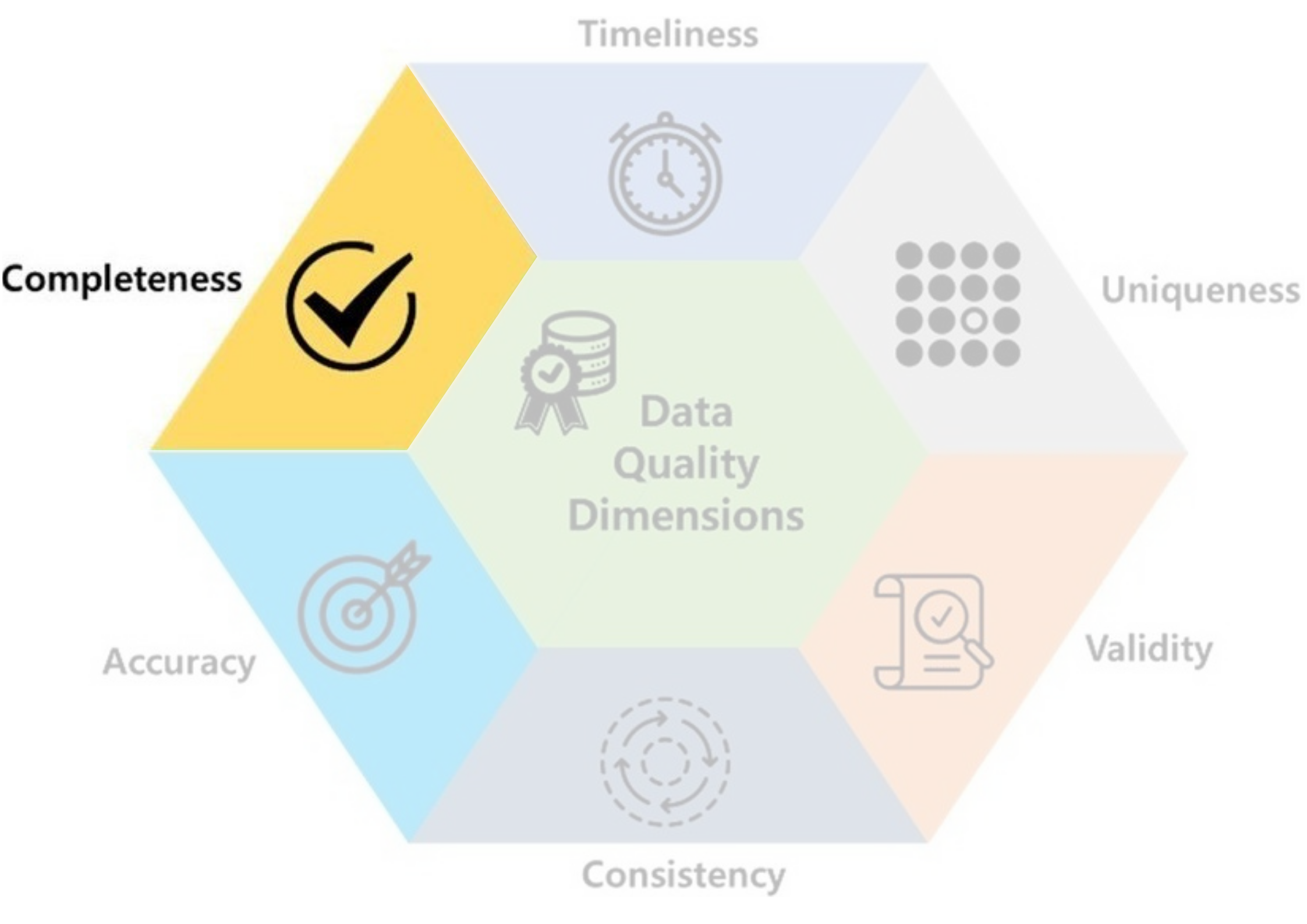
- Completeness: data should not contain missing values.
- Ex: In Lab1,
Cabincolumn of Titanic dataset contains mostlyNaN.
Data quality
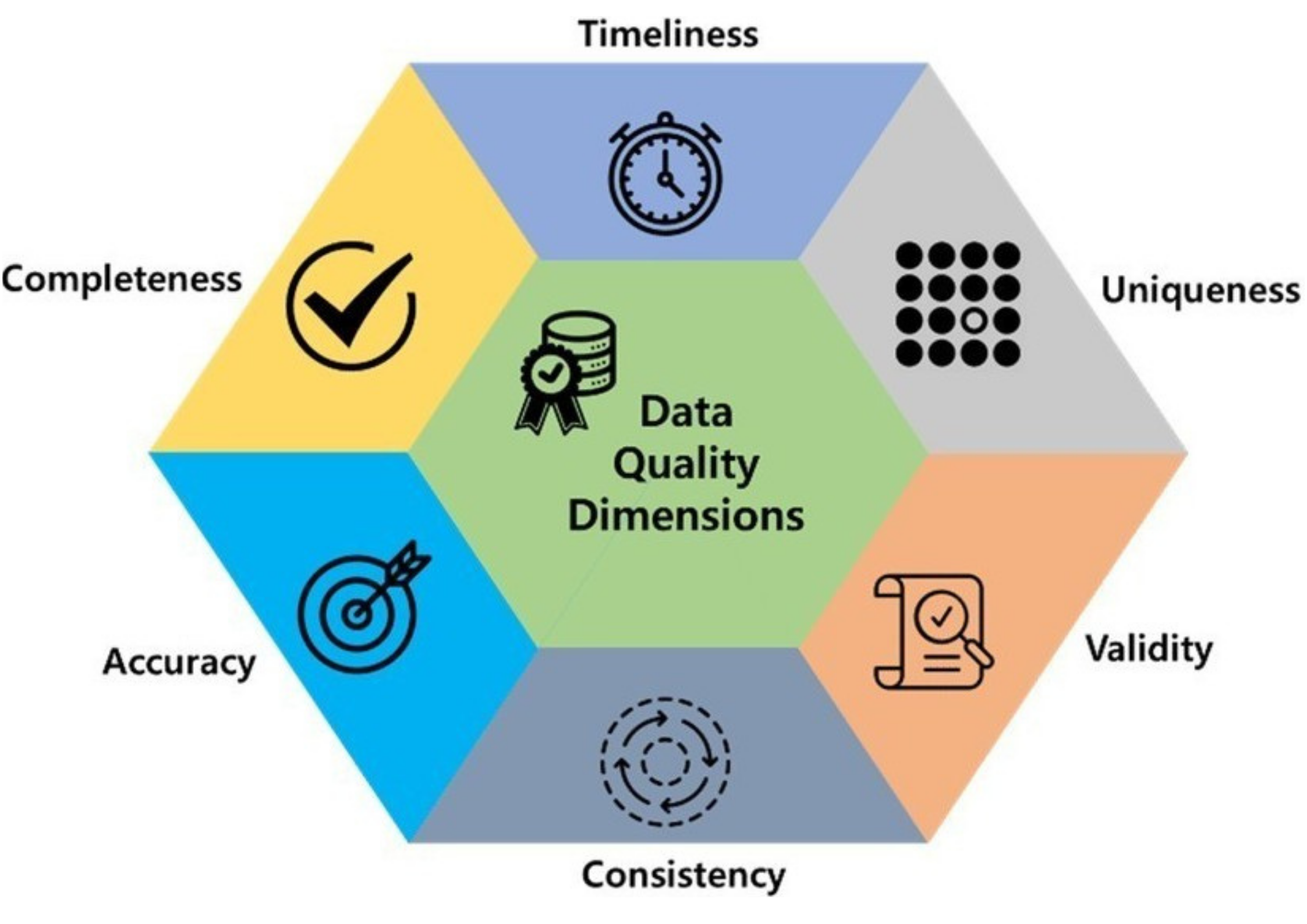
- Data quality includes these 6 factors.
Data quality
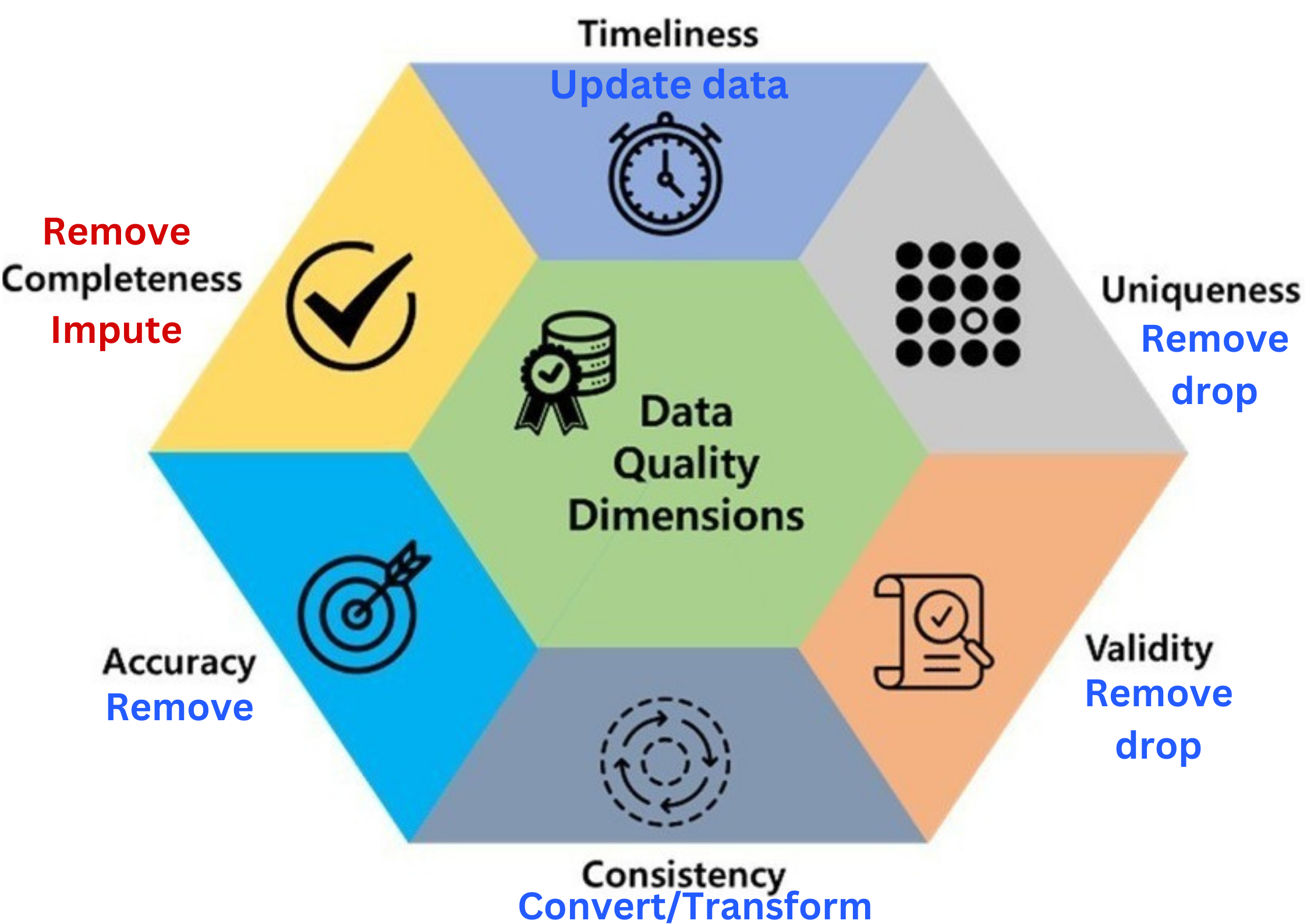
- Data quality includes these 6 factors.
- If there is a problem with any of these, you may ☝️
- For secondary sources, Incompleteness is the common one.
Data preprocessing
Consider an example
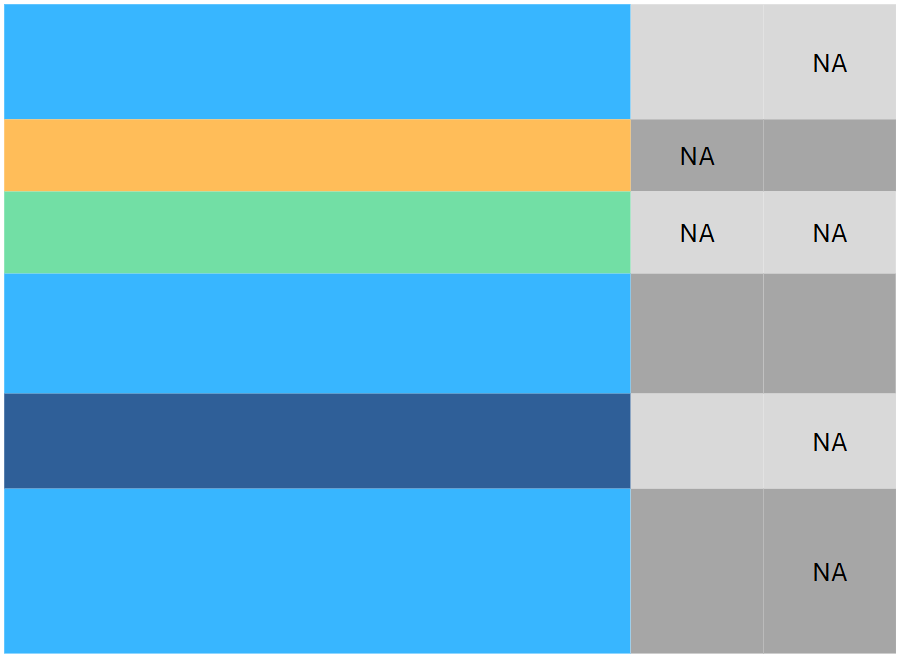
Data preprocessing
Consider an example

| Sex | Pclass | Fare | Cabin | |
|---|---|---|---|---|
| 0 | male | 3 | 7.2500 | NaN |
| 1 | female | 1 | 71.2833 | C85 |
| 2 | female | 3 | 7.9250 | NaN |
| 3 | female | 1 | 53.1000 | C123 |
| 4 | male | 3 | 8.0500 | NaN |
| 5 | male | 3 | 8.4583 | NaN |
| 6 | male | 1 | 51.8625 | E46 |
| 7 | male | 3 | 21.0750 | NaN |
| 8 | female | 3 | 11.1333 | NaN |
| 9 | female | 2 | 30.0708 | NaN |
| 10 | female | 3 | 16.7000 | G6 |
| 11 | female | 1 | 26.5500 | C103 |
Data preprocessing
Consider an example
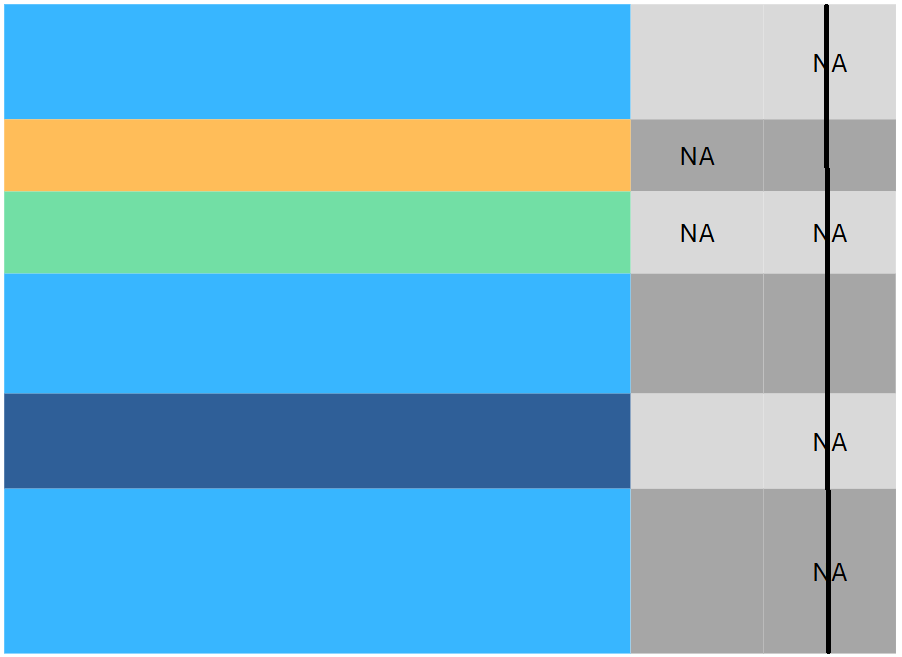
| Sex | Pclass | Fare | Cabin | |
|---|---|---|---|---|
| 0 | male | 3 | 7.2500 | NaN |
| 1 | female | 1 | 71.2833 | C85 |
| 2 | female | 3 | 7.9250 | NaN |
| 3 | female | 1 | 53.1000 | C123 |
| 4 | male | 3 | 8.0500 | NaN |
| 5 | male | 3 | 8.4583 | NaN |
| 6 | male | 1 | 51.8625 | E46 |
| 7 | male | 3 | 21.0750 | NaN |
| 8 | female | 3 | 11.1333 | NaN |
| 9 | female | 2 | 30.0708 | NaN |
| 10 | female | 3 | 16.7000 | G6 |
| 11 | female | 1 | 26.5500 | C103 |
Real Example
Titanic Dataset (891 rows, 12 columns)
- Convert data types:
- Study missing values in
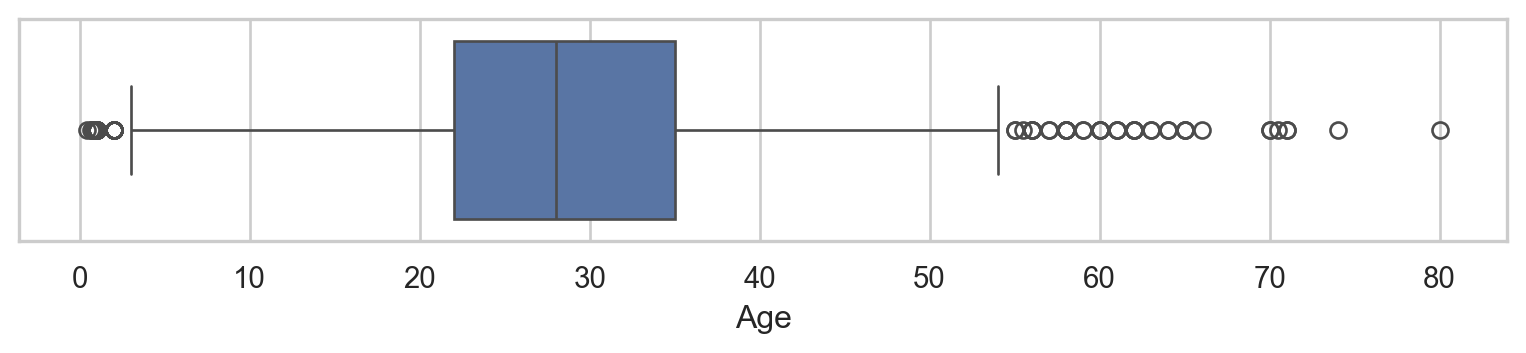
Age:- Impact on qual. columns:
Code
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style="whitegrid")
fig, axs = plt.subplots(2, 4, figsize=(6, 3.5))
col_qual = ['Survived', 'Pclass', 'Sex', 'Embarked']
for i, va in enumerate(col_qual):
sns.countplot(data, x=va, ax=axs[0,i], stat = "proportion")
axs[0,i].bar_label(axs[0,i].containers[0], fmt="%0.2f")
sns.countplot(data.dropna(), x=va, ax=axs[1,i] , stat = "proportion")
axs[1,i].bar_label(axs[1,i].containers[0], fmt="%0.2f")
if i == 0:
axs[0,i].set_ylabel("Before remove NA")
axs[1,i].set_ylabel("After remove NA")
else:
axs[0,i].set_ylabel("")
axs[1,i].set_ylabel("")
plt.tight_layout()
plt.show()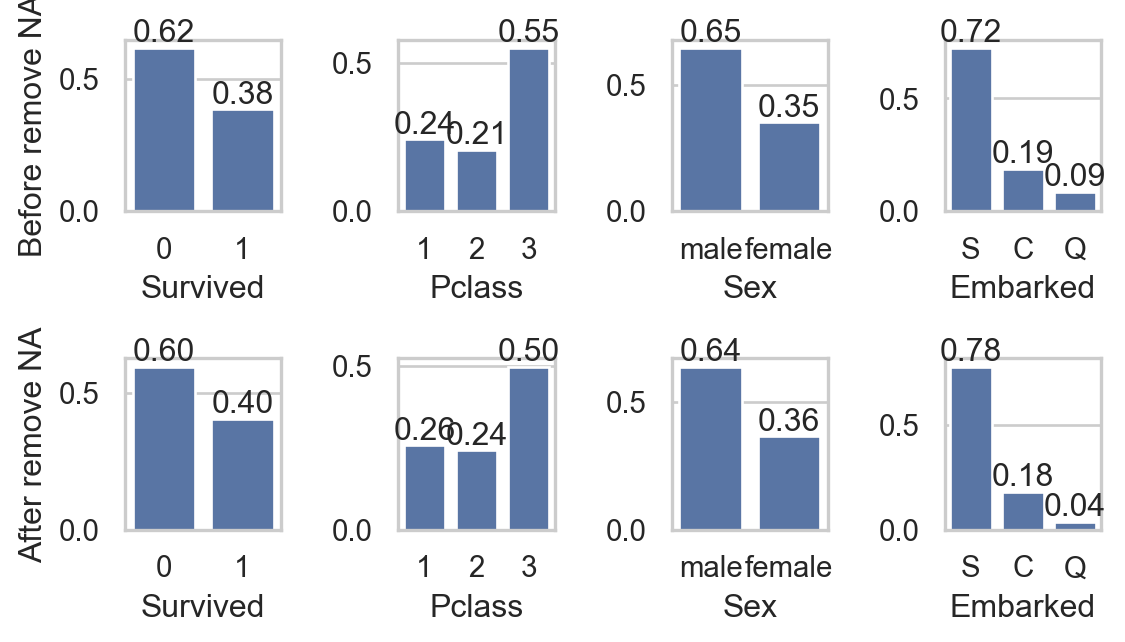
Real Example
Titanic Dataset (891 rows, 12 columns)
- Impact on quan columns:
Code
sns.set(style="whitegrid")
fig, axs = plt.subplots(2, 3, figsize=(6, 3.5))
col_quan = ['SibSp', 'Parch', 'Fare']
for i, va in enumerate(col_quan):
sns.histplot(data, x=va, ax=axs[0,i], kde=True)
sns.histplot(data.dropna(), x=va, ax=axs[1,i], kde=True)
if i == 0:
axs[0,i].set_ylabel("Before remove NA")
axs[1,i].set_ylabel("After remove NA")
else:
axs[0,i].set_ylabel("")
axs[1,i].set_ylabel("")
plt.tight_layout()
plt.show()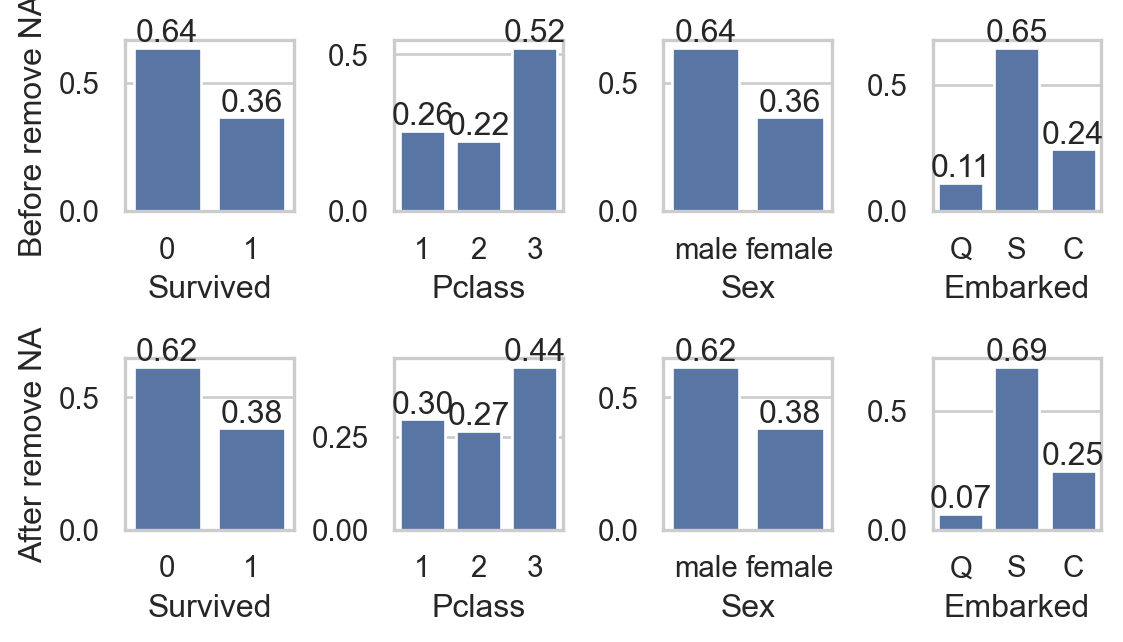
- Do you think that removing
NAgreatly affects other columns?
- Study missing values in
Age:- Impact on qual. columns:
Code
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style="whitegrid")
fig, axs = plt.subplots(2, 4, figsize=(6, 3.5))
col_qual = ['Survived', 'Pclass', 'Sex', 'Embarked']
for i, va in enumerate(col_qual):
sns.countplot(data, x=va, ax=axs[0,i], stat = "proportion")
axs[0,i].bar_label(axs[0,i].containers[0], fmt="%0.2f")
sns.countplot(data.dropna(), x=va, ax=axs[1,i] , stat = "proportion")
axs[1,i].bar_label(axs[1,i].containers[0], fmt="%0.2f")
if i == 0:
axs[0,i].set_ylabel("Before remove NA")
axs[1,i].set_ylabel("After remove NA")
else:
axs[0,i].set_ylabel("")
axs[1,i].set_ylabel("")
plt.tight_layout()
plt.show()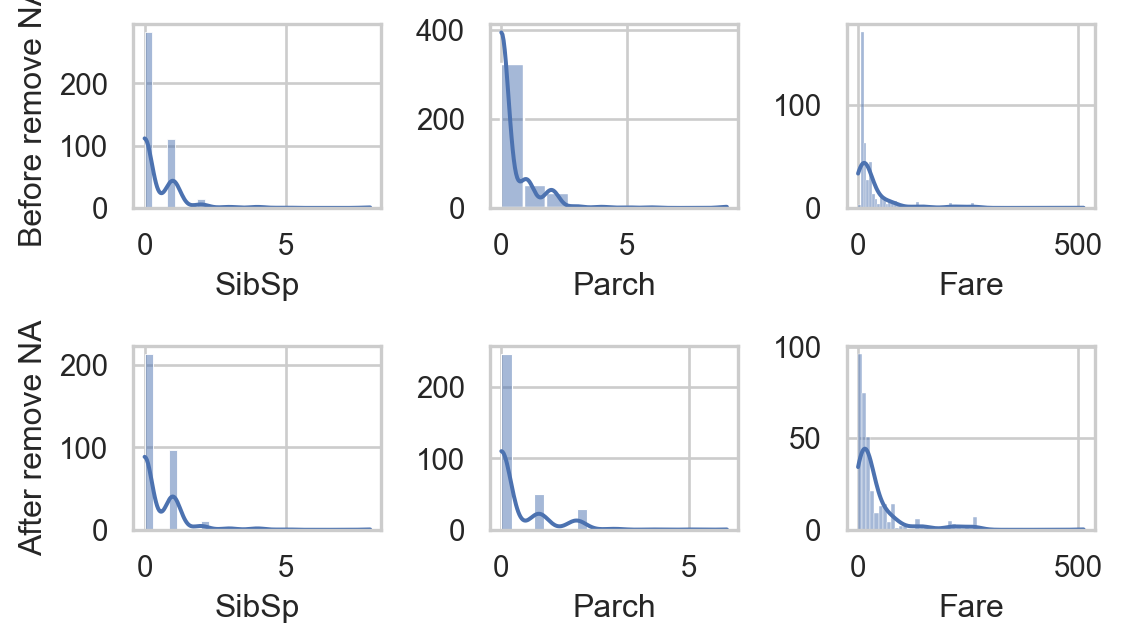
Real Example
Titanic Dataset (891 rows, 12 columns)
- As removing
NAbarely impacts other columns, we can- Drop rows with
NAor - Impute with
median(due to outliers).
- Drop rows with
| Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 |
Ageafter imputation: