Advanced Machine Learning

![]()
Course Criteria
Criteria |
Percentage |
|---|---|
| Attendance | 10% |
| Participation & quiz | 10% |
| Midterm Exam or/and Project | 15%+15% |
| Final Exam | 20% |
| Final Project & Presentation | 30% |
- Programming:
![]()
Python(![]() ,
, ![]() ,
, ![]() ,
, ![]() , …)
, …)



What’s Machine Learning (ML)?
- Machine = Computer
- Learning = Improving in some task w.r.t some measurement.

“The field of study that gives computers the ability to learn (from data) without being explicitly programmed.”
“A computer program is said to learn from experience \(E\) with respect to some class of tasks \(T\) and performance measure \(P\) if its performance at tasks in \(T\), as measured by \(P\), improves with experience \(E\).”

Why does it matter?
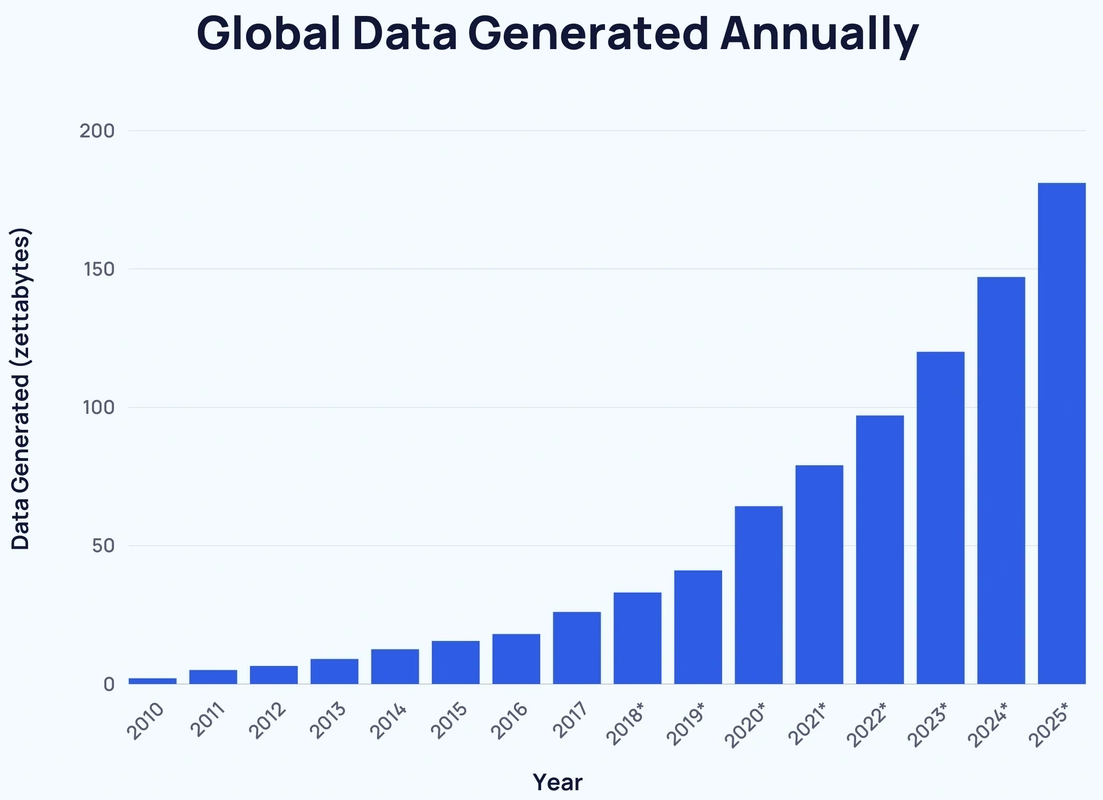

Why does it matter?
MLis a powerful tool in this era.
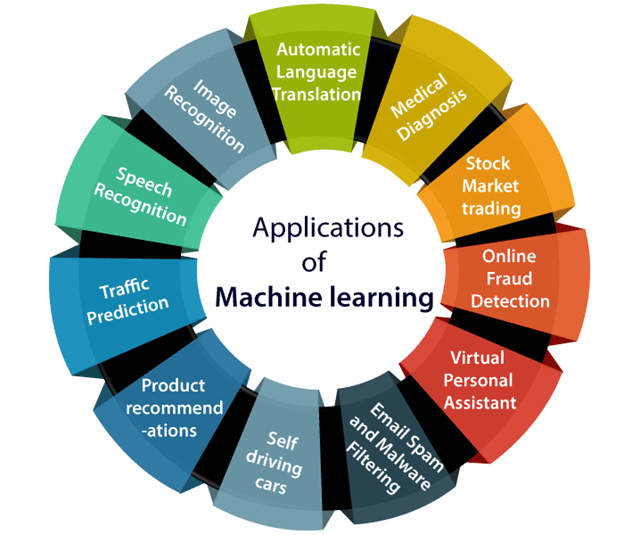
Source: https://www.javatpoint.com/applications-of-machine-learning
Example: Email spam filter ✉️
- Consider \(3\) inputs:
make,address&capitalTotal. - Suitable graphic\(^{\text{📚}}\): histogram, density, boxplot, violinplot…
import matplotlib.pyplot as plt
_, ax = plt.subplots(1, 3, figsize = (12, 3.5))
sns.histplot(data=spam, x="make", ax=ax[0], binwidth=0.2, hue = "type")
ax[0].set_title("Distribution of 'make'")
sns.histplot(data=spam, x="address", ax=ax[1], binwidth=0.5, hue = "type")
ax[1].set_title("Distribution of 'address'")
sns.histplot(data=spam, x="capitalTotal", ax=ax[2], binwidth=700, hue = "type")
ax[2].set_title("Distribution of 'capitalTotal'")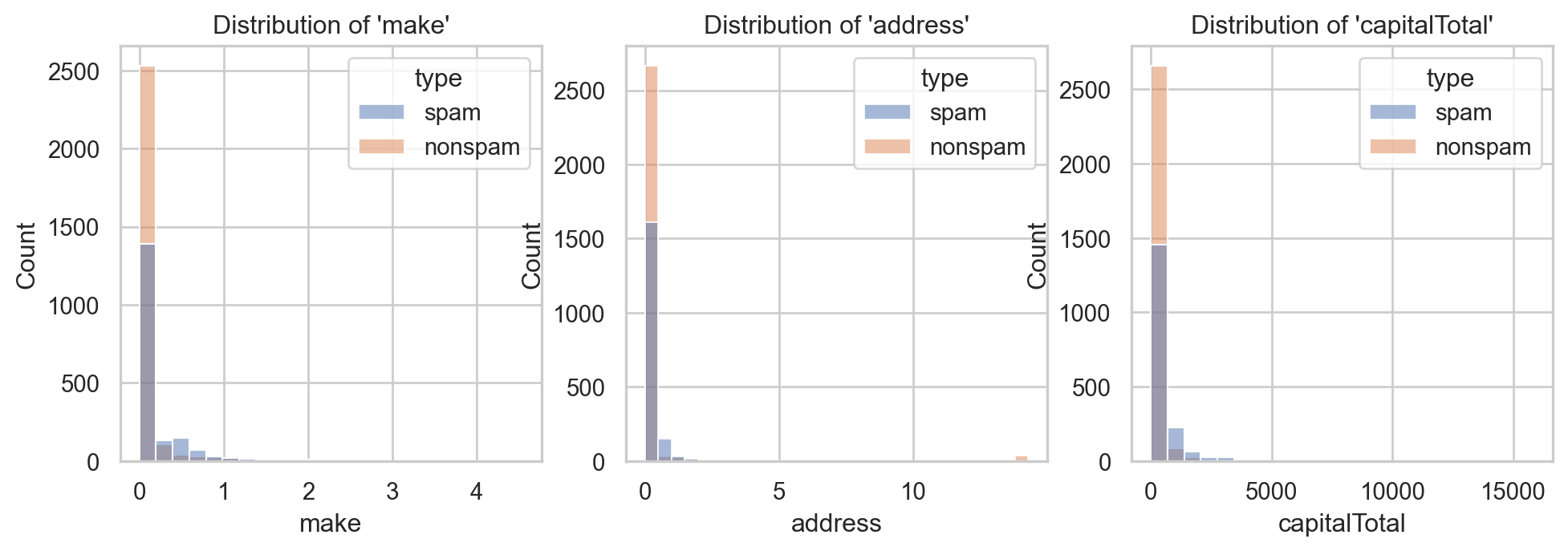
⚠️ Values are too concentrated around \(0\)!
- Use
logscale: too wide range, too dense around \(0\)…
_, ax = plt.subplots(1, 3, figsize = (12, 3.5))
sns.histplot(data=spam, x="make", ax=ax[0], binwidth=0.2, hue = "type")
ax[0].set_title("Distribution of 'make'")
ax[0].set_yscale("log")
sns.histplot(data=spam, x="address", ax=ax[1], binwidth=0.5, hue = "type")
ax[1].set_title("Distribution of 'address'")
ax[1].set_yscale("log")
sns.histplot(data=spam, x="capitalTotal", ax=ax[2], binwidth=700, hue = "type")
ax[2].set_title("Distribution of 'capitalTotal'")
ax[2].set_yscale("log")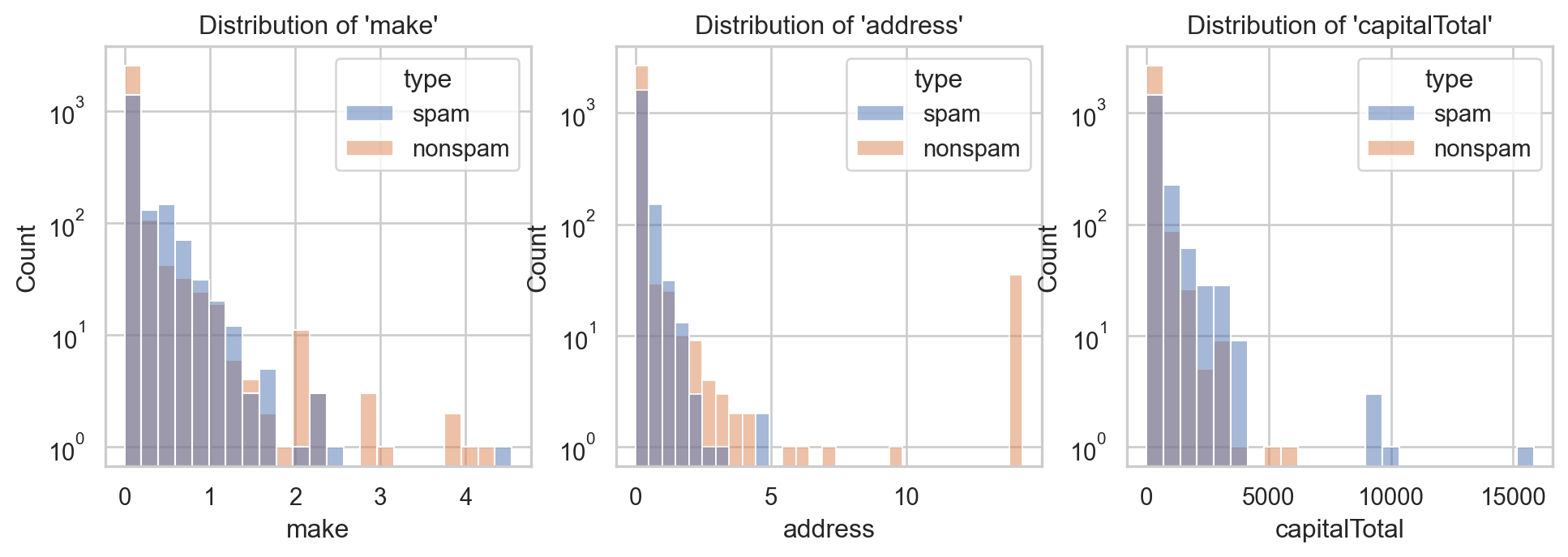
✅ Better, isn’t it?
Example: Email spam filter ✉️
- Consider \(X=(\)
make,address,capitalTotal\()\in\mathbb{R}^3\).
Code
from scipy.stats import gaussian_kde
import numpy as np
x1 = [1.5, 4.2, 5050]
x2 = [1.5, 4.2, 9000]
# Given Y = 1
ker_make = gaussian_kde(spam.make[spam.type=="spam"])
ker_address = gaussian_kde(spam.address[spam.type=="spam"])
ker_capital = gaussian_kde(spam.capitalTotal[spam.type=="spam"])
den11 = [ker_make(x1[0]), ker_address(x1[1]), ker_capital(x1[2])]
den12 = [ker_make(x2[0]), ker_address(x2[1]), ker_capital(x2[2])]
n_spam = np.sum(spam.type=="spam")
n_non = spam.shape[0] - n_spam
pro11 = n_spam/spam.shape[0] * np.prod(den11)
pro12 = n_spam/spam.shape[0] * np.prod(den12)
# Given Y = 0
ker_make = gaussian_kde(spam.make[spam.type=="nonspam"])
ker_address = gaussian_kde(spam.address[spam.type=="nonspam"])
ker_capital = gaussian_kde(spam.capitalTotal[spam.type=="nonspam"])
den01 = [ker_make(x1[0]), ker_address(x1[1]), ker_capital(x1[2])]
den02 = [ker_make(x2[0]), ker_address(x2[1]), ker_capital(x2[2])]
pro01 = n_non/spam.shape[0] * np.prod(den01)
pro02 = n_non/spam.shape[0] * np.prod(den02)
pro01, pro11 = pro01/(pro01+pro11), pro11/(pro01+pro11)
pro02, pro12 = pro02/(pro02+pro12), pro12/(pro02+pro12)
ax[0].vlines([x1[0]], ymin=[0], ymax=[3000], color='black', linestyle = "dashed")
ax[1].vlines([x1[1]], ymin=[0], ymax=[3000], color='black', linestyle = "dashed")
ax[2].vlines([x1[2], x2[2]], ymin=[0], ymax=[3000], color=['red', 'blue'], linestyle = "dashed")
display(fig)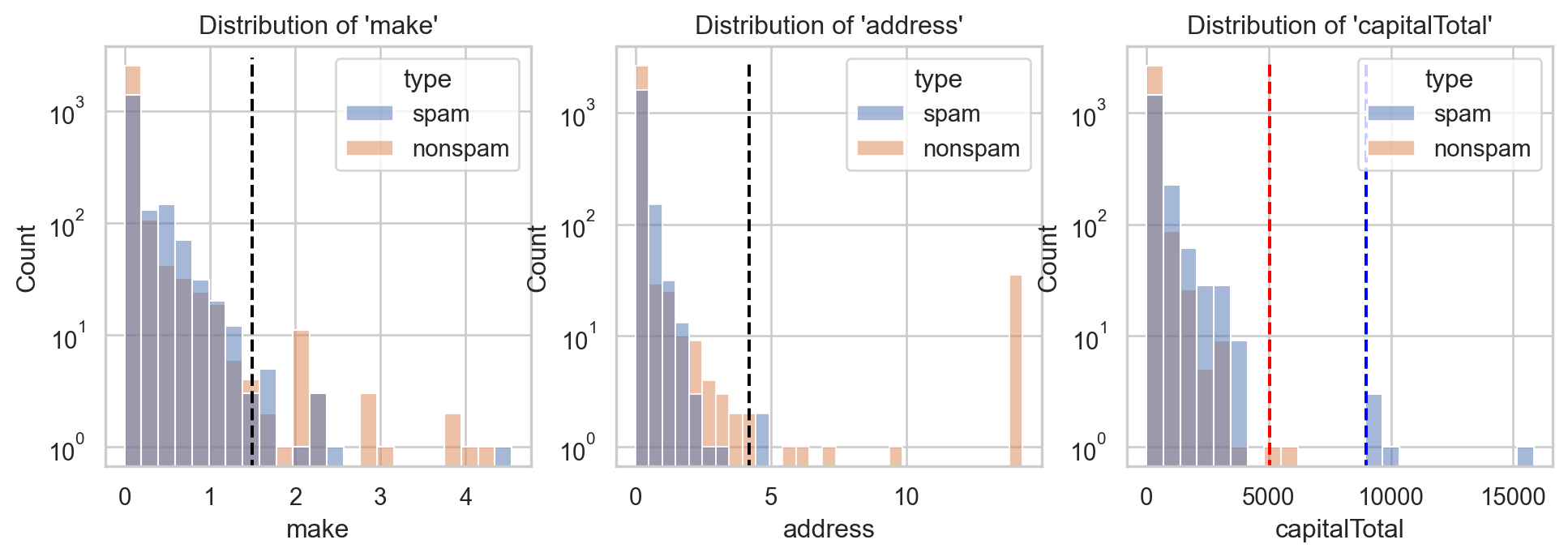
- Type of \(\text{x}_1=(1.5, 4.2, \color{red}{5050})\) and \(\text{x}_2=(1.5, 4.2, \color{blue}{9000})\)?
Back to email spam filter problem
For any email \(\text{x}=(x_1,\dots, x_d)\): \[\mathbb{P}(Y=1|X=\text{x})=\frac{\mathbb{P}^{\small\text{📚}}(X=\text{x}|Y=1)\times\mathbb{P}(Y=1)}{\mathbb{P}(X=\text{x})}.\]
\(\mathbb{P}(Y=1|X=\text{x})^{\small\text{📚}}\) allows us to classify email \(x\): \[\text{Email x} \text{ is a }\begin{cases}\text{spam}& \mbox{if }\mathbb{P}(Y=1|X=\text{x})\geq\delta\\ \text{nonspam}& \mbox{if }\mathbb{P}(Y=1|X=\text{x})<\delta\end{cases}\] for some \(\delta\in (0,1)\). A common choice is \(\delta=0.5\).

Back to email spam filter problem
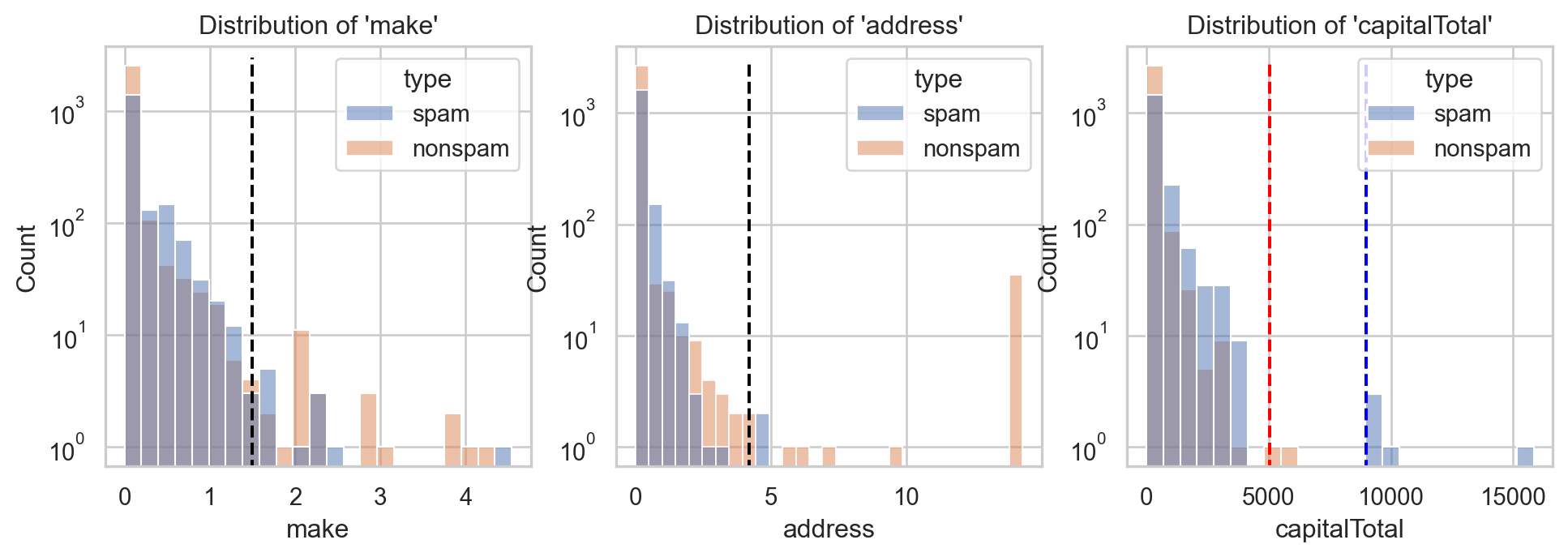
- For \(\text{x}_1=(1.5, 4.2, \color{red}{5050})\) and \(\text{x}_2=(1.5, 4.2, \color{blue}{9000})\):
- \(\mathbb{P}(Y=1|X=\text{x}_1)=\) 3.84e-05.
- \(\mathbb{P}(Y=1|X=\text{x}_2)=\) 1.0, with \(\mathbb{P}(Y=1)=\) 0.394.
Results on Spam dataset
- Data: \((\text{x},y)\in\mathbb{R}^{57}\times\{0,1\}\).
- Test data: \(20\%\) of total 4601 observations.
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
from sklearn.model_selection import train_test_split
sns.set(style="white")
X_train1, X_test1, y_train1, y_test1 = train_test_split(spam.iloc[:,:57], spam.iloc[:,57], test_size = 0.2, random_state=42)
nb1 = GaussianNB()
nb1 = nb1.fit(X_train1, y_train1)
pred1 = nb1.predict(X_test1)
conf1 = confusion_matrix(pred1, y_test1)
con_fig1 = ConfusionMatrixDisplay(conf1)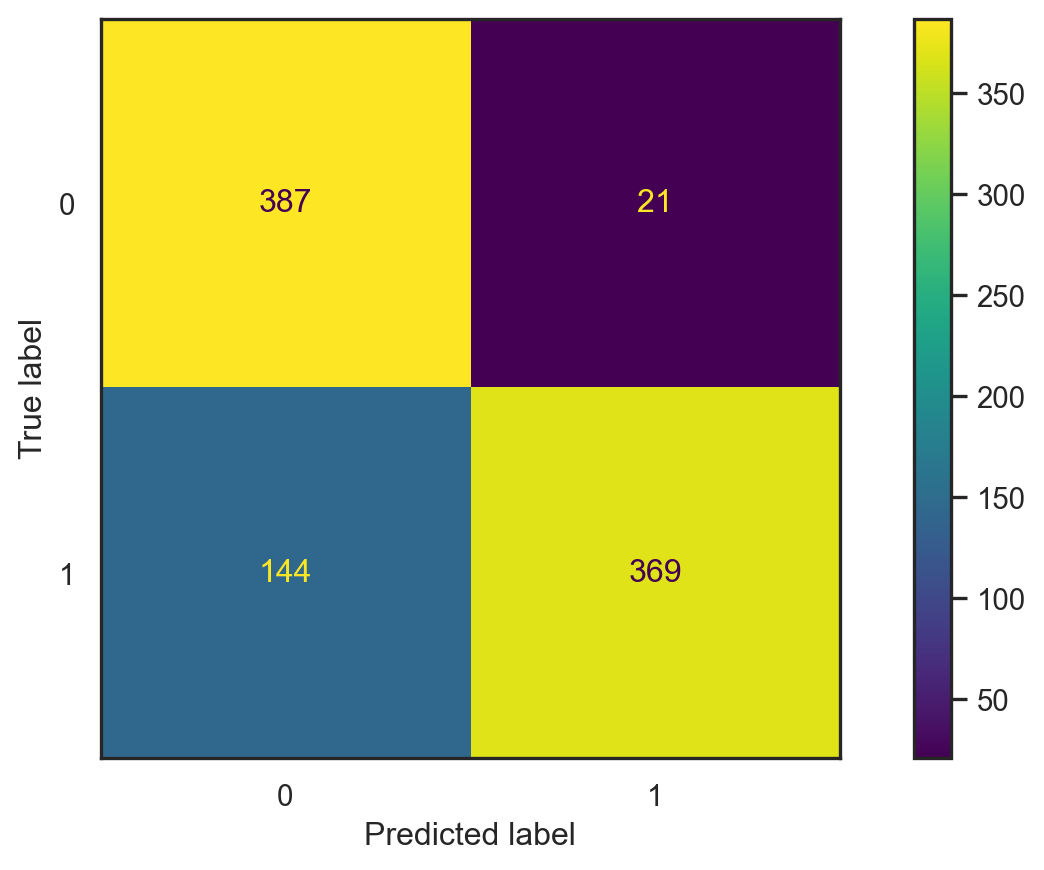
- Accuracy: \[\frac{387+369}{387+369+21+144}\approx 0.821.\]
- Misclassification error: \[1-\text{accuracy}\approx 0.179.\]
- This depends on the split ⚠️
- Input: \(x=(\)
make,address,capitalTotal\()\in\mathbb{R}^3\). - Test data: the same \(20\%\).
X_train2, X_test2, y_train2, y_test2 = train_test_split(spam[["make","address", "capitalTotal"]], spam.iloc[:,57], test_size = 0.2, random_state=42)
nb2 = GaussianNB()
nb2 = nb1.fit(X_train2, y_train2)
pred2 = nb2.predict(X_test2)
conf2 = confusion_matrix(pred2, y_test2)
con_fig2 = ConfusionMatrixDisplay(conf2)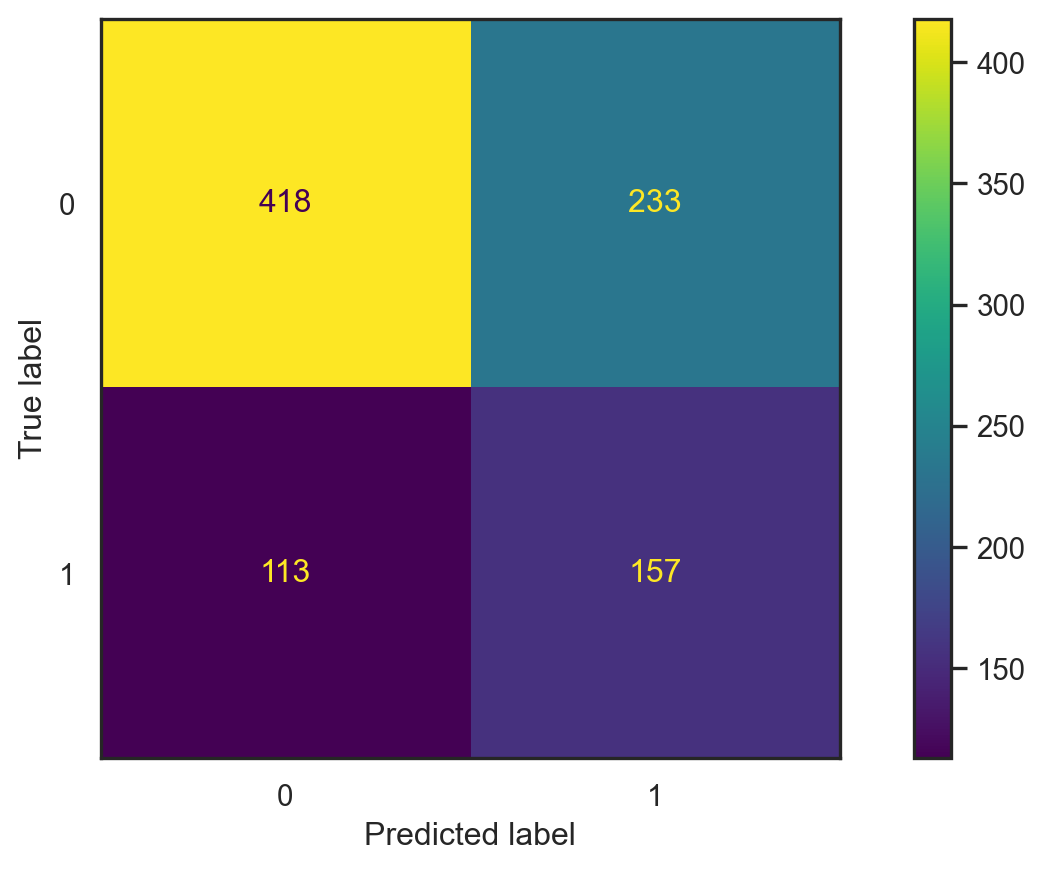
- Accuracy: \[\frac{418+157}{418+157+233+113}\approx 0.624.\]
- Misclassification error: \[1-\text{accuracy}\approx0.376.\]
- This depends on the split ⚠️
Imbalanced data ⚠️
- If the data contains \(95\%\)
nonspam, always guessingnonspamgives \(0.95\) accuracy! Accuracyisn’t the right metric forimbalanceddata ⚠️
Confustion Matrix
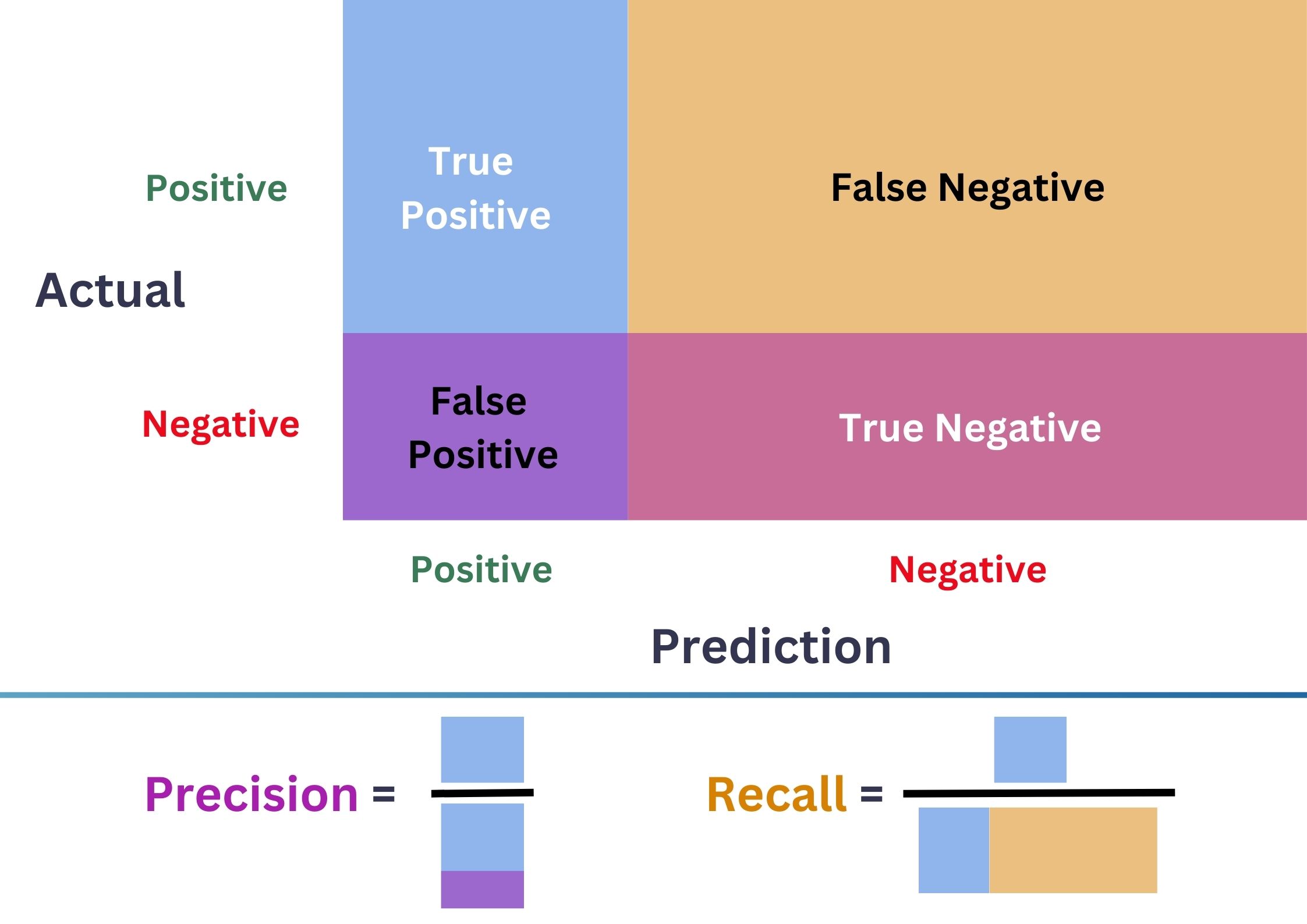
- \(\color{purple}{\text{Precision}}=\frac{\color{CornflowerBlue}{\text{TP}}}{\color{CornflowerBlue}{\text{TP}}+\color{purple}{\text{FP}}}\)
- \(\color{Tan}{\text{Recall}}=\frac{\color{CornflowerBlue}{\text{TP}}}{\color{CornflowerBlue}{\text{TP}}+\color{Tan}{\text{FN}}}\)
- \(\color{ForestGreen}{\text{F1-score}}=\frac{2.\color{purple}{\text{Precision}}.\color{Tan}{\text{Recall}}}{\color{purple}{\text{Precision}}+\color{Tan}{\text{Recall}}}\).
- \(\color{ForestGreen}{\text{F1-score}}\) balances \(\color{purple}{\text{FP}}\) & \(\color{Tan}{\text{FN}}\).
Imbalanced data ⚠️
- \(\color{purple}{\text{Precision}}=\frac{\color{CornflowerBlue}{\text{TP}}}{\color{CornflowerBlue}{\text{TP}}+\color{purple}{\text{FP}}}\)
- \(\color{Tan}{\text{Recall}}=\frac{\color{CornflowerBlue}{\text{TP}}}{\color{CornflowerBlue}{\text{TP}}+\color{Tan}{\text{FN}}}\)
- \(\color{ForestGreen}{\text{F1-score}}=\frac{2.\color{purple}{\text{Precision}}.\color{Tan}{\text{Recall}}}{\color{purple}{\text{Precision}}+\color{Tan}{\text{Recall}}}\).
Code
import plotly.graph_objects as go
x = np.linspace(0,1,20)
y = np.linspace(0,1,20)
z1 = [[2*x[i]*y[j]/(x[i]+y[j]) for j in range(len(y))] for i in range(len(x))]
z2 = [[(x[i]+y[j])/2 for j in range(len(y))] for i in range(len(x))]
camera = dict(
eye=dict(x=1.7, y=-1.2, z=1.2)
)
fig = go.Figure(go.Surface(x = x,
y = y,
z = z1,
name = "F1-score",
colorscale = "Blues",
showscale = False))
fig.add_trace(go.Surface(x = x,
y = y,
z = z2,
name = "Mean",
colorscale = "Electric",
showscale = False))
fig.update_layout(scene = dict(
xaxis_title='Precision',
yaxis_title='Recall',
zaxis_title='Scores'),
title = dict(text="F1-score vs Mean",
y=0.9,
x=0.5,
font=dict(size = 30,
color = "#1C66B5")
),
scene_camera=camera,
width = 560,
height = 500)
fig.show()Imbalanced data ⚠️
Receiver Operating Characteristic Curve (ROC)
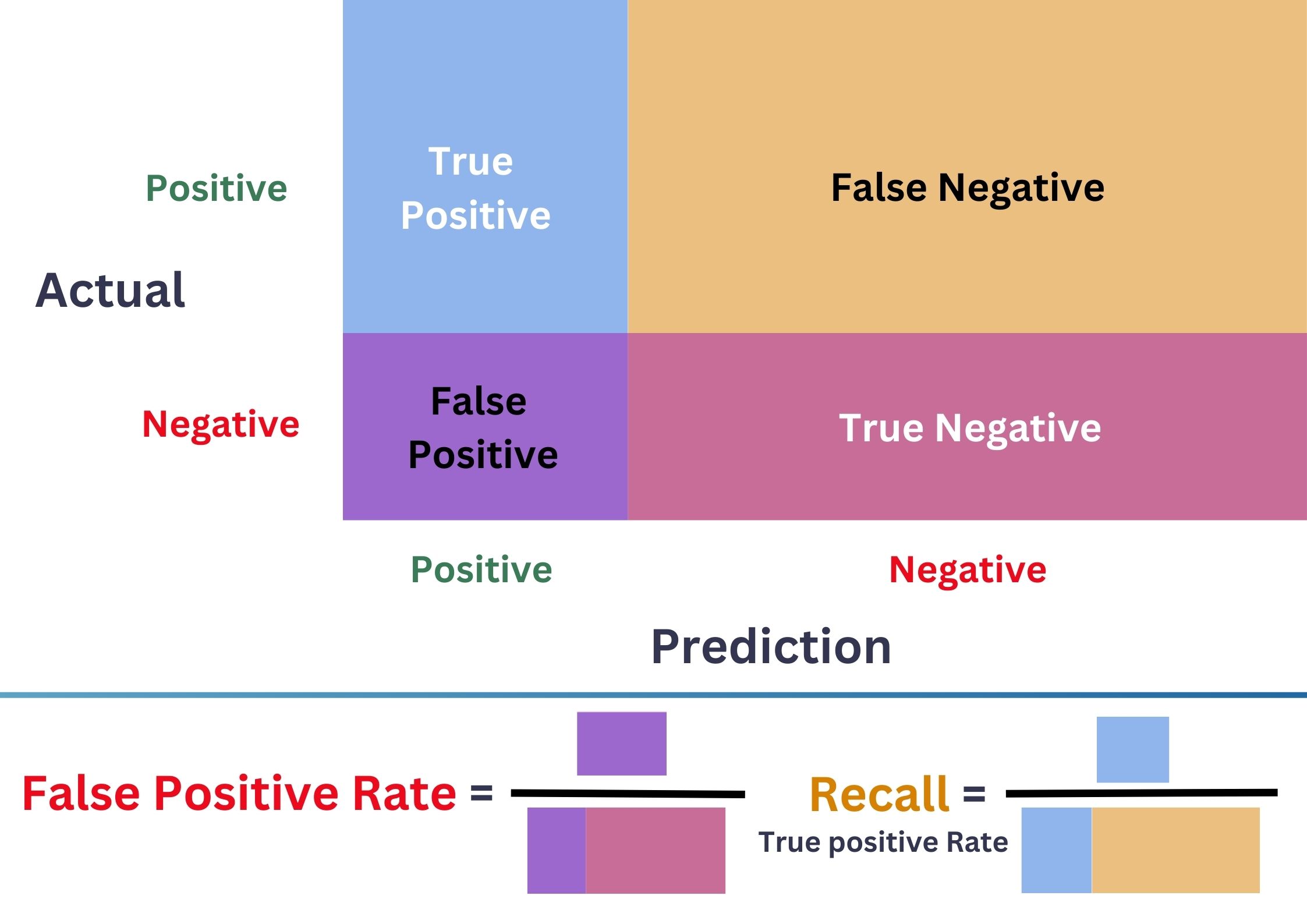
Code
from plot_metric.functions import BinaryClassification
from plotly.tools import mpl_to_plotly
# Visualisation with plot_metric
y1 = 1*(y_test1 == "spam")
bc1 = BinaryClassification(y1, pr1, labels=["nonspam", "spam"], seaborn_style="whitegrid")
bc2 = BinaryClassification(y1, pr2, labels=["nonspam", "spam"], seaborn_style="whitegrid")
# Figures
a = bc1.plot_roc_curve()
fig_full = plt.gcf()
pl_full = mpl_to_plotly(fig_full)
pl_full.update_layout(width=500, height=450,
title=dict(text="ROC Curve of Full model",
font=dict(size=25)),
xaxis_title = dict(font=dict(size=20, color = "red")),
yaxis_title = dict(text='True Positive Rate (Recall)', font=dict(size=20, color = "#EBB31D")),
template='plotly_white')
pl_full.show()Imbalanced data ⚠️
Receiver Operating Characteristic Curve (ROC)
Code
bc2 = BinaryClassification(y1, pr2, labels=["nonspam", "spam"], seaborn_style="whitegrid")
# Figures
b = bc2.plot_roc_curve()
fig_3 = plt.gcf()
pl_3 = mpl_to_plotly(fig_3)
pl_3.update_layout(width=500, height=450,
title=dict(text="ROC Curve of 3-input model",
font=dict(size=25)),
xaxis_title = dict(font=dict(size=20, color = "red")),
yaxis_title = dict(text='True Positive Rate (Recall)', font=dict(size=20, color = "#EBB31D")),
template='plotly_white')
pl_3.show()Imbalanced data ⚠️ (Summary)
Confusion matrix
- Precision: controlls FP.
- Recall: controlls FN.
- F1-score: ballances the two.
ROC Curve & AUC
- ROC Curve: ballances TPR and FPR.
- Can be used to select \(\delta\in [0,1]\).
- Better model = Larger AUC.
Quiz time 🤗

Quiz time (again) 🤗

LDA is slightly simpler than QDA
Boundary Decision of LDA
- The boundary decision takes
Linear Formof \(\text{x}\): \[\text{x}^tv+c=0,\] where \(v\in\mathbb{R}^d\) and \(c\in\mathbb{R}\) and depend on \(\pi_k,\pi_j,\mu_k,\mu_j\) and \(\Sigma\).
Code
import matplotlib as mpl
from matplotlib import colors
import matplotlib.pyplot as plt
from sklearn.inspection import DecisionBoundaryDisplay
# Functions for ellipses and boudary decision
def plot_ellipse(mean, cov, color, ax):
v, w = np.linalg.eigh(cov)
u = w[0] / np.linalg.norm(w[0])
angle = np.arctan(u[1] / u[0])
angle = 180 * angle / np.pi # convert to degrees
# filled Gaussian at 2 standard deviation
ell = mpl.patches.Ellipse(
mean,
2 * v[0] ** 0.5,
2 * v[1] ** 0.5,
angle=180 + angle,
facecolor=color,
edgecolor="black",
linewidth=2,
)
ell.set_clip_box(ax.bbox)
ell.set_alpha(0.4)
ax.add_artist(ell)
def plot_result(estimator, X, y, ax):
cmap = colors.ListedColormap(["tab:red", "tab:blue"])
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="predict_proba",
plot_method="pcolormesh",
ax=ax,
cmap="RdBu",
alpha=0.3,
)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="predict_proba",
plot_method="contour",
ax=ax,
alpha=1.0,
levels=[0.5],
)
y_pred = estimator.predict(X)
X_right, y_right = X[y == y_pred], y[y == y_pred]
X_wrong, y_wrong = X[y != y_pred], y[y != y_pred]
ax.scatter(X_right[:, 0], X_right[:, 1], c=y_right, s=20, cmap=cmap, alpha=0.5)
ax.scatter(
X_wrong[:, 0],
X_wrong[:, 1],
c=y_wrong,
s=30,
cmap=cmap,
alpha=0.9,
marker="x",
)
ax.scatter(
estimator.means_[:, 0],
estimator.means_[:, 1],
c="yellow",
s=200,
marker="*",
edgecolor="black",
)
if isinstance(estimator, LDA):
covariance = [estimator.covariance_] * 2
else:
covariance = estimator.covariance_
plot_ellipse(estimator.means_[0], covariance[0], "tab:red", ax)
plot_ellipse(estimator.means_[1], covariance[1], "tab:blue", ax)
ax.set_box_aspect(1)
ax.spines["top"].set_visible(False)
ax.spines["bottom"].set_visible(False)
ax.spines["left"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.set(xticks=[], yticks=[])
fig, axs = plt.subplots(nrows=1, ncols=2, sharex="row", sharey="row", figsize=(8, 12))
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis as QDA
lda = LDA(solver="svd", store_covariance=True)
qda = QDA(store_covariance=True)
for ax_row, X, y in zip(
(axs,),
(df_qda[["x1", "x2"]].to_numpy()[:600,:], ),
(df_qda['y'].to_numpy()[:600], ),
):
lda.fit(X, y)
plot_result(lda, X, y, ax_row[0])
qda.fit(X, y)
plot_result(qda, X, y, ax_row[1])
axs[0].set_title("Boundary decision of LDA")
axs[1].set_title("Boundary decision of QDA")
plt.show()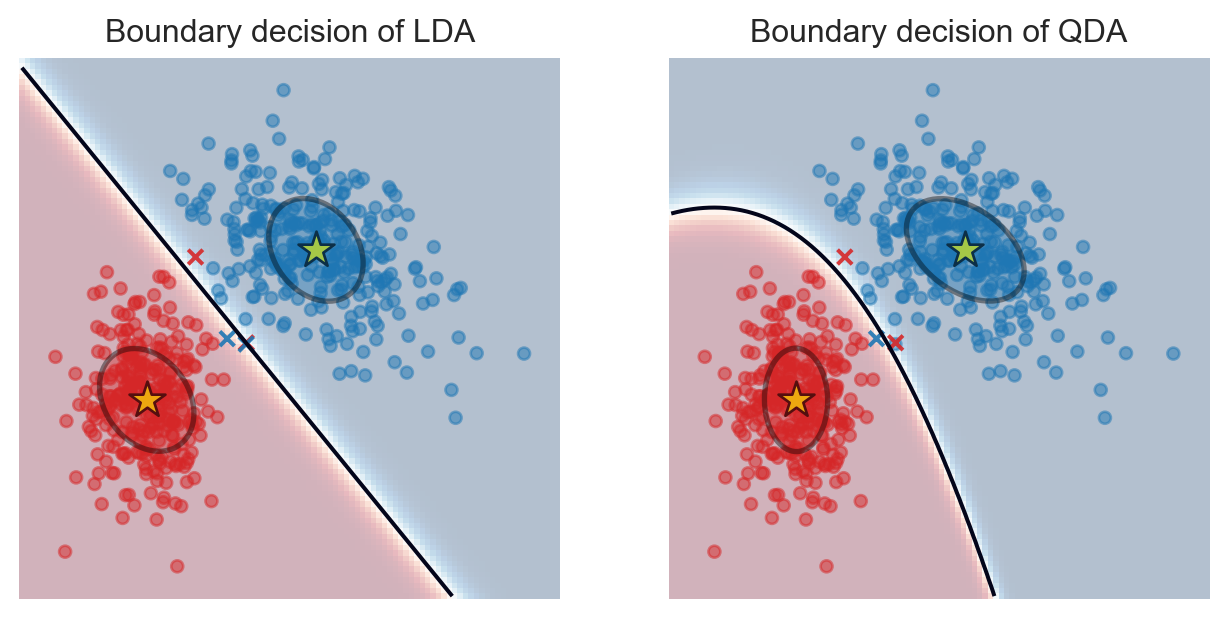
LDA, QDA & RDA on Spam dataset
- Same \(20\%\) test data of total 4601 observations.
sns.set(style="white")
# Build LDA object & predict
lda = LDA(solver="svd", store_covariance=True)
lda1 = lda.fit(X_train1, y_train1)
pred1_lda = lda1.predict(X_test1)
conf1_lda = confusion_matrix(pred1_lda, y_test1)
con_fig1_lda = ConfusionMatrixDisplay(conf1_lda)
qda = QDA(store_covariance=True)
qda1 = qda.fit(X_train1, y_train1)
pred1_qda = qda1.predict(X_test1)
conf1_qda = confusion_matrix(pred1_qda, y_test1)
con_fig1_qda = ConfusionMatrixDisplay(conf1_qda)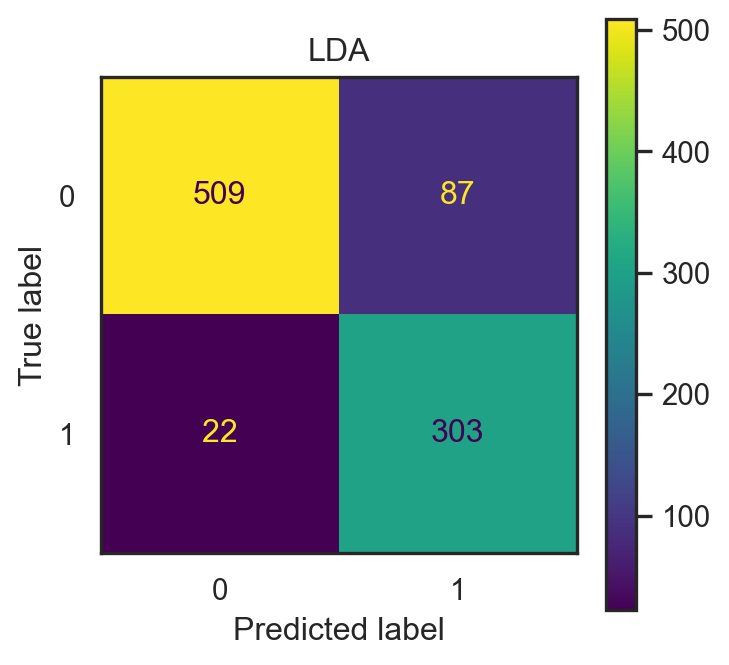
- LDA accuracy: 0.882.
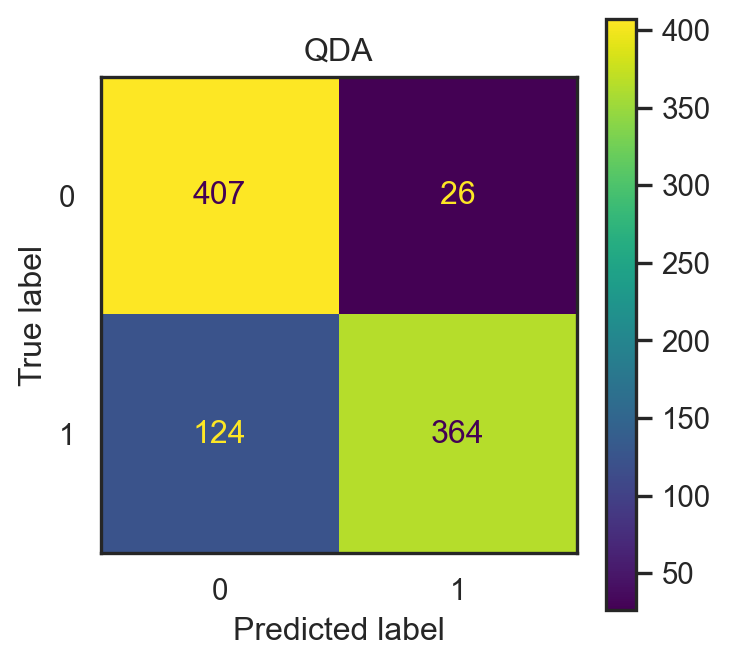
- QDA accuracy: 0.882.
- Input: \(x=(\)
make,address,capitalTotal\()\in\mathbb{R}^3\).
lda = LDA(solver="svd", store_covariance=True)
lda2 = lda.fit(X_train2, y_train2)
pred2_lda = lda2.predict(X_test2)
conf2_lda = confusion_matrix(pred2_lda, y_test2)
con_fig2_lda = ConfusionMatrixDisplay(conf2_lda)
qda = QDA(store_covariance=True)
qda2 = qda.fit(X_train2, y_train2)
pred2_qda = qda2.predict(X_test2)
conf2_qda = confusion_matrix(pred2_qda, y_test2)
con_fig2_qda = ConfusionMatrixDisplay(conf2_qda)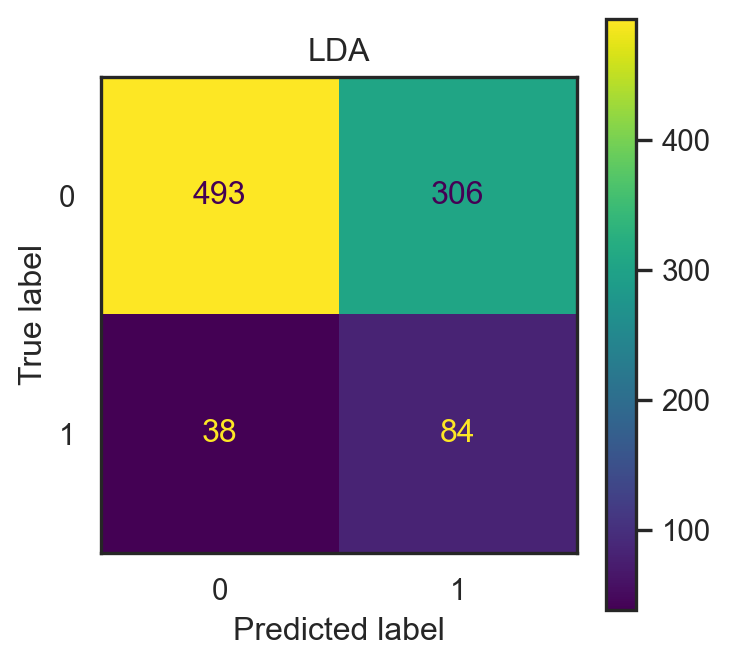
- LDA accuracy: 0.626.
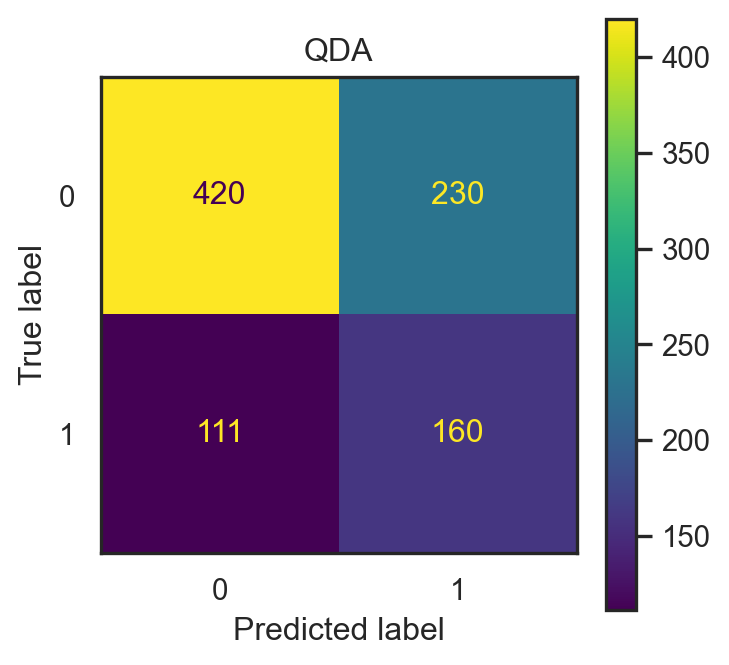
- QDA accuracy: 0.626.
Coming in the TP 😁!
Quiz time 🤗

![]()