Objective: This practical session (TP) is designed to help you apply the concepts and techniques you have learned about Logistic Regression. You will learn to analyze each input variable and its connection to the target which will guide you to a suitable model in predicting the target.
import numpy as npimport pandas as pdimport kagglehub# Download latest versionpath = kagglehub.dataset_download("johnsmith88/heart-disease-dataset")data = pd.read_csv(path +"/heart.csv")data.head(5)
age
sex
cp
trestbps
chol
fbs
restecg
thalach
exang
oldpeak
slope
ca
thal
target
0
52
1
0
125
212
0
1
168
0
1.0
2
2
3
0
1
53
1
0
140
203
1
0
155
1
3.1
0
0
3
0
2
70
1
0
145
174
0
1
125
1
2.6
0
0
3
0
3
61
1
0
148
203
0
1
161
0
0.0
2
1
3
0
4
62
0
0
138
294
1
1
106
0
1.9
1
3
2
0
A. General view of the dataset.
Load the dataset into jupyter notebook.
What’s the dimension of the dataset?
How many qualitative and quantitative variables are there in this dataset (answer this question carefully! Some qualitative variables may be encoded using numerical values)?
Convert variables into their suitable data type if there are any inconsistent variable types.
import numpy as npimport pandas as pdprint(f'The dimension of the dataset: {data.shape}')
The dimension of the dataset: (1025, 14)
data.dtypes.to_frame().T
age
sex
cp
trestbps
chol
fbs
restecg
thalach
exang
oldpeak
slope
ca
thal
target
0
int64
int64
int64
int64
int64
int64
int64
int64
int64
float64
int64
int64
int64
int64
quan_vars = ['age','trestbps','chol','thalach','oldpeak']qual_vars = ['sex','cp','fbs','restecg','exang','slope','ca','thal','target']for i in quan_vars: data[i] = data[i].astype('float')for i in qual_vars: data[i] = data[i].astype('category')
print(f'The number of categorical data is {data.select_dtypes(include="category").shape[1]}')print(f'The number of quantitative data is {data.select_dtypes(include="number").shape[1]}')
The number of categorical data is 9
The number of quantitative data is 5
B. Univariate Analysis.
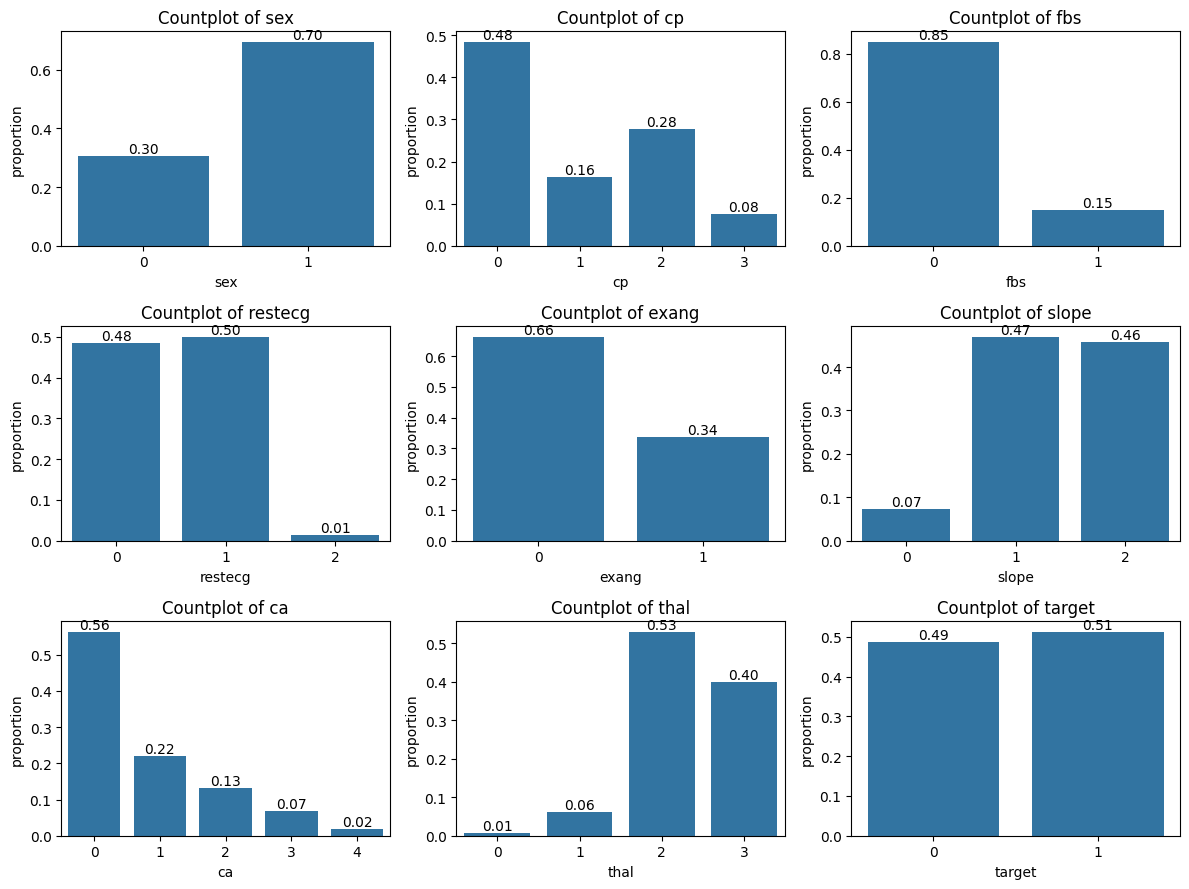
Compute summary statistics and visualize the distribution of the target and the inputs according to their types.
Are there any missing values? Duplicate data? Outliers?
Address or handle the above problems.
data.describe()
age
trestbps
chol
thalach
oldpeak
count
1025.000000
1025.000000
1025.00000
1025.000000
1025.000000
mean
54.434146
131.611707
246.00000
149.114146
1.071512
std
9.072290
17.516718
51.59251
23.005724
1.175053
min
29.000000
94.000000
126.00000
71.000000
0.000000
25%
48.000000
120.000000
211.00000
132.000000
0.000000
50%
56.000000
130.000000
240.00000
152.000000
0.800000
75%
61.000000
140.000000
275.00000
166.000000
1.800000
max
77.000000
200.000000
564.00000
202.000000
6.200000
import seaborn as snsimport matplotlib.pyplot as pltx, axs = plt.subplots(1, 5, figsize=(15, 3))for var in quan_vars: sns.histplot(data=data, x=var, ax=axs[quan_vars.index(var)], kde=True) axs[quan_vars.index(var)].set_title(f"Histogram of {var}")plt.tight_layout()plt.show()
_, axs = plt.subplots(3, 3, figsize=(12, 9))for var in qual_vars: sns.countplot(data=data, x=var, ax=axs[qual_vars.index(var)//3, qual_vars.index(var)%3], stat="proportion") axs[qual_vars.index(var)//3, qual_vars.index(var)%3].set_title(f"Countplot of {var}") axs[qual_vars.index(var)//3, qual_vars.index(var)%3].bar_label(axs[qual_vars.index(var)//3, qual_vars.index(var)%3].containers[0], fmt="%.2f")plt.tight_layout()plt.show()
data.isna().sum().to_frame().T
age
sex
cp
trestbps
chol
fbs
restecg
thalach
exang
oldpeak
slope
ca
thal
target
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
id_duplicated = data.duplicated()data.loc[id_duplicated,:].indexprint(f"Target of duplicated rows: {data.loc[data.duplicated(), ['target']].value_counts()}")print(f'Percentage of duplicated rows: {data.duplicated().sum()/data.shape[0]*100:.2f}%')
Target of duplicated rows: target
1 362
0 361
Name: count, dtype: int64
Percentage of duplicated rows: 70.54%
data.drop_duplicates(inplace=True)
Since the data contains more than 70% duplications, we keeps the duplicated rows.
_, axs = plt.subplots(1, 5, figsize=(15, 3))for var in quan_vars: sns.boxplot(data=data, y=var, x="target", hue="target", ax=axs[quan_vars.index(var)]) axs[quan_vars.index(var)].set_title(f"{var} vs Heart disease")plt.tight_layout()plt.show()
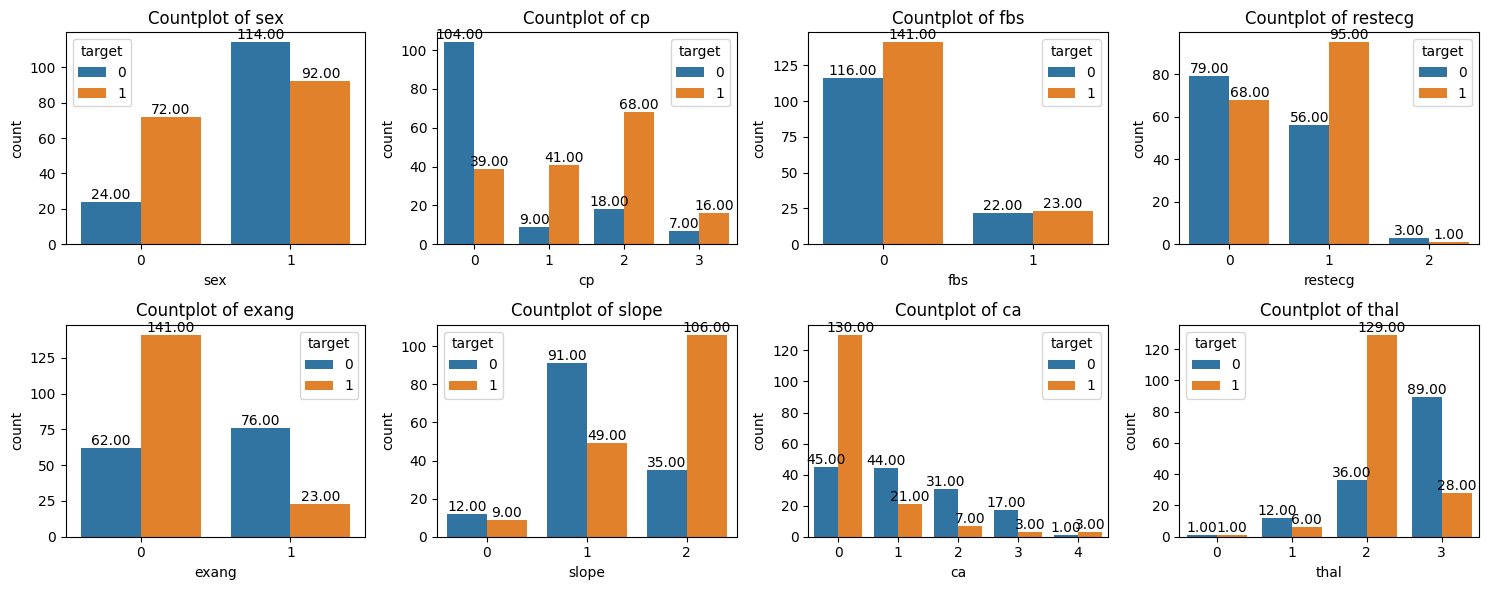
_, axs = plt.subplots(2, 4, figsize=(15, 6))for var in qual_vars:if var !="target": sns.countplot(data=data, x=var, hue="target", ax=axs[qual_vars.index(var)//4, qual_vars.index(var)%4]) axs[qual_vars.index(var)//4, qual_vars.index(var)%4].set_title(f"Countplot of {var}") axs[qual_vars.index(var)//4, qual_vars.index(var)%4].bar_label(axs[qual_vars.index(var)//4, qual_vars.index(var)%4].containers[0], fmt="%.2f") axs[qual_vars.index(var)//4, qual_vars.index(var)%4].bar_label(axs[qual_vars.index(var)//4, qual_vars.index(var)%4].containers[1], fmt="%.2f")plt.tight_layout()plt.show()
Remark: You should try to understand the differences between these two types of correlation as they are helpful in guiding you to the correct transformation of inputs for model development. At the end of this step, you should have strong intuition on the most impactful inputs for building the model and how can to handle the inputs before building models.
D. Building Logistic Regression Models
Split the data into \(80\%-20\%\) training and testing data.
from sklearn.model_selection import train_test_splitX, y = data.iloc[:,:-1], data.iloc[:,-1]X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
Build a logistic regression model using only categorical variables on the training data then compute its performance on the test data using suitable metrics.
Based on EDA step, we found that qualitative variables are more related to the target than the some of numerical variables. When building models, we actually observe that the model with qualitative variables does perform better than the model with only quantitative variables.
Try to study logistic regression using polynomial features. Compute its performance on the test data and compare to the previous result.
We study polynomial features with numerical variables.
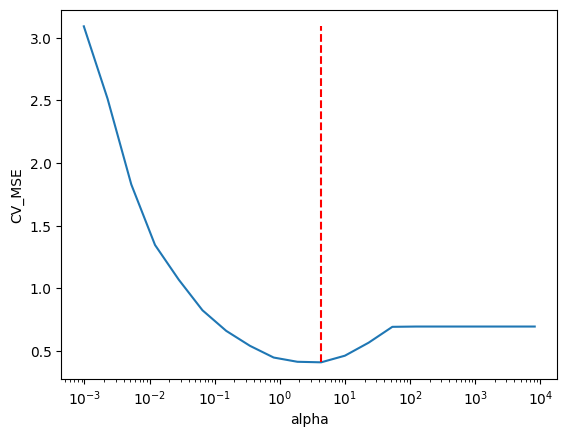
It is very common that with higher degrees, the model becomes too flexible and overfits the data. One can use regularization method to control the flexibility of the model.
Apply regularization methods and evaluate their performances on the test data.
from sklearn.model_selection import cross_val_scorescaler = StandardScaler()# let's fix degreedeg =3poly = PolynomialFeatures(degree=deg, include_bias=False)X_train_poly = np.column_stack([poly.fit_transform(X_train.select_dtypes(include="number")), X_train_cat])X_train_poly = scaler.fit_transform(X_train_poly)X_test_poly = np.column_stack([poly.fit_transform(X_test.select_dtypes(include="number")), X_test_cat])X_test_poly = scaler.transform(X_test_poly)alphas =2** np.linspace(-10, 13, 20)losses = []for alpha in alphas: model = LogisticRegression(penalty="l2", C=1/alpha, max_iter=1000) model = model.fit(X_train_poly, y_train) loss =-cross_val_score(model, X_train_poly, y_train, cv=5, scoring="neg_log_loss") losses.append(np.mean(loss))
/usr/local/lib/python3.10/dist-packages/sklearn/linear_model/_sag.py:349: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge
warnings.warn(
Accuracy
Precision
Recall
F1-score
AUC
Qual_model
0.836066
0.848485
0.848485
0.848485
0.834957
Quan_model
0.786885
0.833333
0.757576
0.793651
0.789502
Full_model
0.836066
0.848485
0.848485
0.848485
0.834957
EDA_model
0.836066
0.848485
0.848485
0.848485
0.834957
Poly2_model
0.836066
0.848485
0.848485
0.848485
0.834957
Poly3_model
0.836066
0.870968
0.818182
0.843750
0.837662
Poly4_model
0.819672
0.866667
0.787879
0.825397
0.822511
Poly5_model
0.819672
0.866667
0.787879
0.825397
0.822511
Poly6_model
0.786885
0.812500
0.787879
0.800000
0.786797
Poly7_model
0.803279
0.818182
0.818182
0.818182
0.801948
Poly8_model
0.803279
0.818182
0.818182
0.818182
0.801948
Poly9_model
0.786885
0.812500
0.787879
0.800000
0.786797
Poly10_model
0.770492
0.787879
0.787879
0.787879
0.768939
Poly11_model
0.754098
0.764706
0.787879
0.776119
0.751082
Poly12_model
0.737705
0.757576
0.757576
0.757576
0.735931
Poly13_model
0.737705
0.757576
0.757576
0.757576
0.735931
Poly14_model
0.737705
0.757576
0.757576
0.757576
0.735931
Poly15_model
0.737705
0.757576
0.757576
0.757576
0.735931
Poly3_Ridge_model
0.852459
0.875000
0.848485
0.861538
0.852814
Poly3_Lasso_model
0.836066
0.848485
0.848485
0.848485
0.834957
From these results, Polynomial feature of logistic regression with Ridge regularization is the best model with better score than other models.
E. Try what you have done on Spam dataset.
import pandas as pdpath ="https://raw.githubusercontent.com/hassothea/MLcourses/main/data/spam.txt"data = pd.read_csv(path, sep=" ")data.head(5)
Id
make
address
all
num3d
our
over
remove
internet
order
...
charSemicolon
charRoundbracket
charSquarebracket
charExclamation
charDollar
charHash
capitalAve
capitalLong
capitalTotal
type
0
1
0.00
0.64
0.64
0.0
0.32
0.00
0.00
0.00
0.00
...
0.00
0.000
0.0
0.778
0.000
0.000
3.756
61
278
spam
1
2
0.21
0.28
0.50
0.0
0.14
0.28
0.21
0.07
0.00
...
0.00
0.132
0.0
0.372
0.180
0.048
5.114
101
1028
spam
2
3
0.06
0.00
0.71
0.0
1.23
0.19
0.19
0.12
0.64
...
0.01
0.143
0.0
0.276
0.184
0.010
9.821
485
2259
spam
3
4
0.00
0.00
0.00
0.0
0.63
0.00
0.31
0.63
0.31
...
0.00
0.137
0.0
0.137
0.000
0.000
3.537
40
191
spam
4
5
0.00
0.00
0.00
0.0
0.63
0.00
0.31
0.63
0.31
...
0.00
0.135
0.0
0.135
0.000
0.000
3.537
40
191
spam
5 rows × 59 columns
To detect informative inputs in this case, we use ANOVA test on the set of inputs.
from scipy.stats import f_onewayimp_var = []very_imp = []for va in data.columns[1:-1]: val = f_oneway(data.loc[data['type'] =="spam", va], data.loc[data['type'] =="nonspam", va])[1]if val <0.01: imp_var.append(va)if val <1e-10: very_imp.append(va)print(f"Number of important variables: {len(imp_var)}")print(f"Number of very important variables: {len(very_imp)}")
Number of important variables: 54
Number of very important variables: 43
In this section, you will work with Mnist dataset. It can be imported using the following codes.
from keras.datasets import mnist(train_images, train_labels), (test_images, test_labels) = mnist.load_data()import matplotlib.pyplot as pltimport numpy as npdigit = np.random.choice(train_images.shape[0], size=10)_ , axs = plt.subplots(2,5, figsize=(9, 3))for i inrange(10): axs[i//5, i%5].imshow(train_images[digit[i]]) axs[i//5, i%5].axis("off") axs[i//5, i%5].set_title(f"True label: {train_labels[digit[i]]}")plt.tight_layout()plt.show()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
11490434/11490434 [==============================] - 0s 0us/step
Build Multinomial Logistic Regressoin to recognize images of testing digits of this dataset.
# Data preprocessingM = np.max(train_images)X, y = train_images.reshape(60000, 28*28)/M, train_labelsX_test, y_test = test_images.reshape(10000, 28*28)/M, test_labels# Distribution of targetimport seaborn as snssns.countplot(x=y)plt.show()